 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture Matters: Pedestrian Gesture Recognition for AVs Through Skeleton Pose Evaluation
Feb 09, 2026Gestures are a key component of non-verbal communication in traffic, often helping pedestrian-to-driver interactions when formal traffic rules may be insufficient. This problem becomes more apparent when autonomous vehicles (AVs) struggle to interpret such gestures. In this study, we present a gesture classification framework using 2D pose estimation applied to real-world video sequences from the WIVW dataset. We categorise gestures into four primary classes (Stop, Go, Thank & Greet, and No Gesture) and extract 76 static and dynamic features from normalised keypoints. Our analysis demonstrates that hand position and movement velocity are especially discriminative in distinguishing between gesture classes, achieving a classification accuracy score of 87%. These findings not only improve the perceptual capabilities of AV systems but also contribute to the broader understanding of pedestrian behaviour in traffic contexts.
Feature Importance in Pedestrian Intention Prediction: A Context-Aware Review
Sep 11, 2024
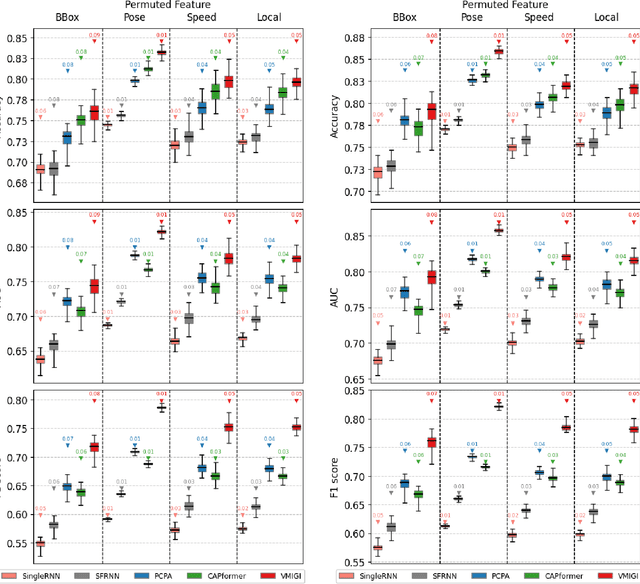
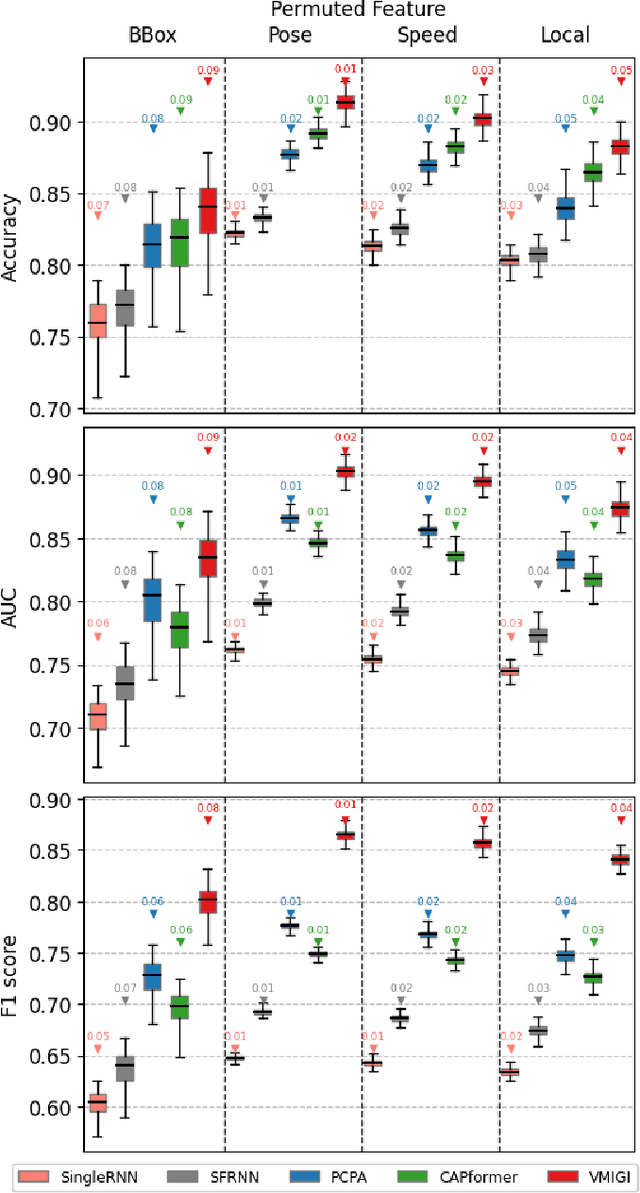
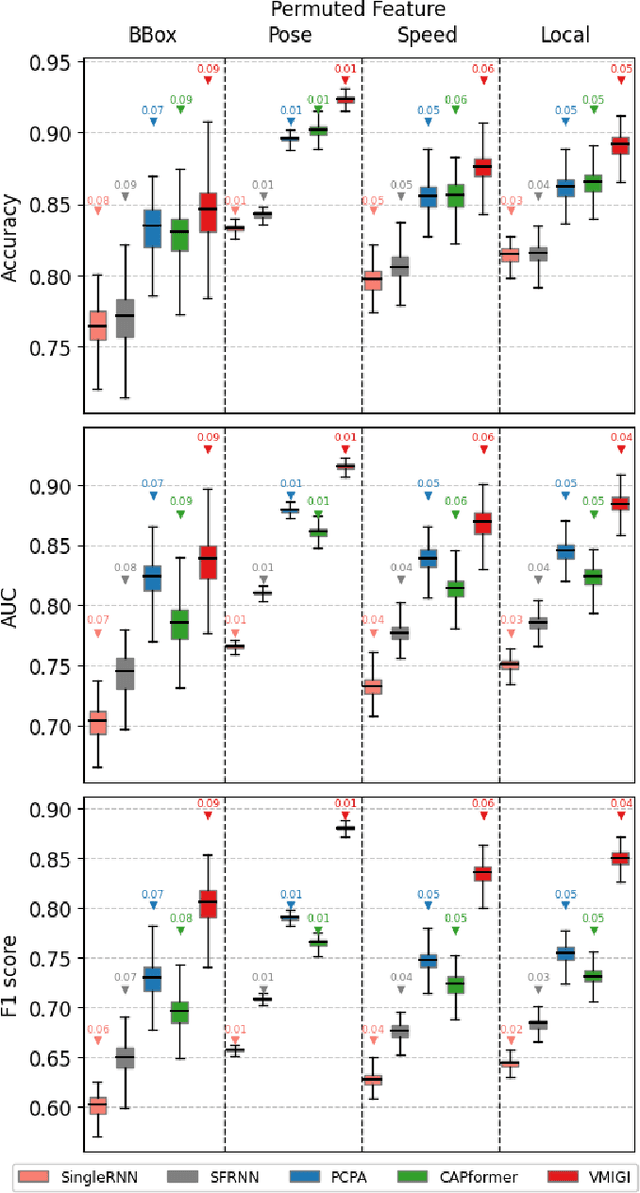
Recent advancements in predicting pedestrian crossing intentions for Autonomous Vehicles using Computer Vision and Deep Neural Networks are promising. However, the black-box nature of DNNs poses challenges in understanding how the model works and how input features contribute to final predictions. This lack of interpretability delimits the trust in model performance and hinders informed decisions on feature selection, representation, and model optimisation; thereby affecting the efficacy of future research in the field. To address this, we introduce Context-aware Permutation Feature Importance (CAPFI), a novel approach tailored for pedestrian intention prediction. CAPFI enables more interpretability and reliable assessments of feature importance by leveraging subdivided scenario contexts, mitigating the randomness of feature values through targeted shuffling. This aims to reduce variance and prevent biased estimations in importance scores during permutations. We divide the Pedestrian Intention Estimation (PIE) dataset into 16 comparable context sets, measure the baseline performance of five distinct neural network architectures for intention prediction in each context, and assess input feature importance using CAPFI. We observed nuanced differences among models across various contextual characteristics. The research reveals the critical role of pedestrian bounding boxes and ego-vehicle speed in predicting pedestrian intentions, and potential prediction biases due to the speed feature through cross-context permutation evaluation. We propose an alternative feature representation by considering proximity change rate for rendering dynamic pedestrian-vehicle locomotion, thereby enhancing the contributions of input features to intention prediction. These findings underscore the importance of contextual features and their diversity to develop accurate and robust intent-predictive models.
AllWeatherNet:Unified Image enhancement for autonomous driving under adverse weather and lowlight-conditions
Sep 03, 2024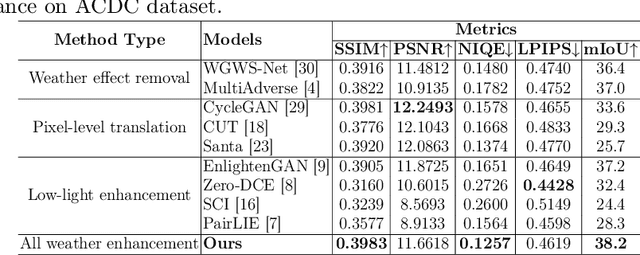

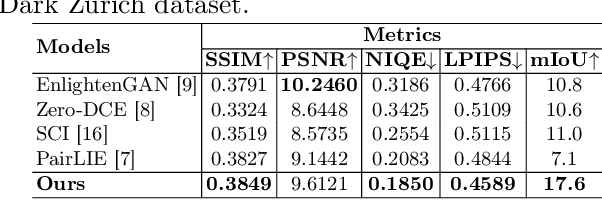
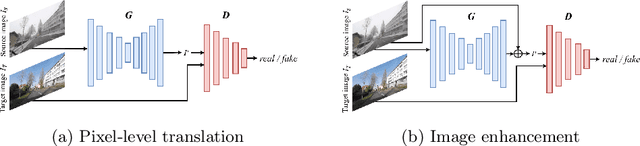
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on only one specific condition, such as removing rain or translating nighttime images into daytime ones. To address these limitations, we propose a method to improve the visual quality and clarity degraded by such adverse conditions. Our method, AllWeather-Net, utilizes a novel hierarchical architecture to enhance images across all adverse conditions. This architecture incorporates information at three semantic levels: scene, object, and texture, by discriminating patches at each level. Furthermore, we introduce a Scaled Illumination-aware Attention Mechanism (SIAM) that guides the learning towards road elements critical for autonomous driving perception. SIAM exhibits robustness, remaining unaffected by changes in weather conditions or environmental scenes. AllWeather-Net effectively transforms images into normal weather and daytime scenes, demonstrating superior image enhancement results and subsequently enhancing the performance of semantic segmentation, with up to a 5.3% improvement in mIoU in the trained domain. We also show our model's generalization ability by applying it to unseen domains without re-training, achieving up to 3.9% mIoU improvement. Code can be accessed at: https://github.com/Jumponthemoon/AllWeatherNet.
PIP-Net: Pedestrian Intention Prediction in the Wild
Mar 01, 2024Accurate pedestrian intention prediction (PIP) by Autonomous Vehicles (AVs) is one of the current research challenges in this field. In this article, we introduce PIP-Net, a novel framework designed to predict pedestrian crossing intentions by AVs in real-world urban scenarios. We offer two variants of PIP-Net designed for different camera mounts and setups. Leveraging both kinematic data and spatial features from the driving scene, the proposed model employs a recurrent and temporal attention-based solution, outperforming state-of-the-art performance. To enhance the visual representation of road users and their proximity to the ego vehicle, we introduce a categorical depth feature map, combined with a local motion flow feature, providing rich insights into the scene dynamics. Additionally, we explore the impact of expanding the camera's field of view, from one to three cameras surrounding the ego vehicle, leading to enhancement in the model's contextual perception. Depending on the traffic scenario and road environment, the model excels in predicting pedestrian crossing intentions up to 4 seconds in advance which is a breakthrough in current research studies in pedestrian intention prediction. Finally, for the first time, we present the Urban-PIP dataset, a customised pedestrian intention prediction dataset, with multi-camera annotations in real-world automated driving scenarios.
Evaluating Driver Readiness in Conditionally Automated Vehicles from Eye-Tracking Data and Head Pose
Jan 20, 2024
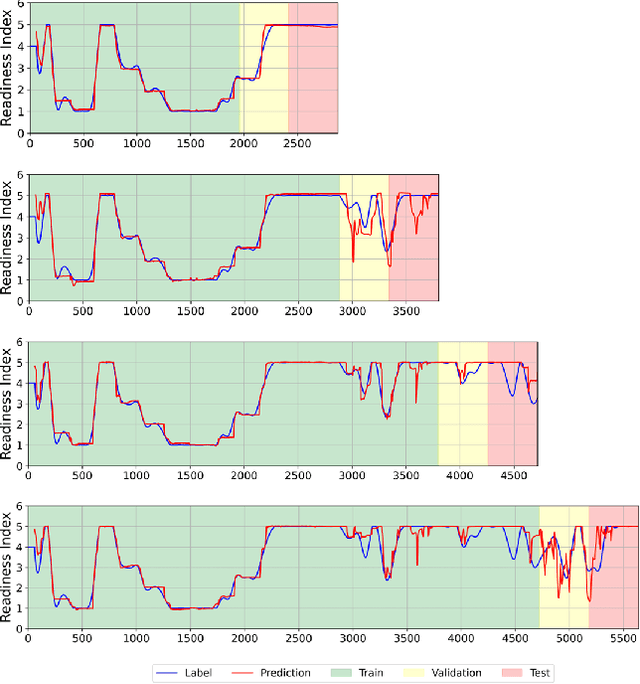
As automated driving technology advances, the role of the driver to resume control of the vehicle in conditionally automated vehicles becomes increasingly critical. In the SAE Level 3 or partly automated vehicles, the driver needs to be available and ready to intervene when necessary. This makes it essential to evaluate their readiness accurately. This article presents a comprehensive analysis of driver readiness assessment by combining head pose features and eye-tracking data. The study explores the effectiveness of predictive models in evaluating driver readiness, addressing the challenges of dataset limitations and limited ground truth labels. Machine learning techniques, including LSTM architectures, are utilised to model driver readiness based on the Spatio-temporal status of the driver's head pose and eye gaze. The experiments in this article revealed that a Bidirectional LSTM architecture, combining both feature sets, achieves a mean absolute error of 0.363 on the DMD dataset, demonstrating superior performance in assessing driver readiness. The modular architecture of the proposed model also allows the integration of additional driver-specific features, such as steering wheel activity, enhancing its adaptability and real-world applicability.
LSTM-based Preceding Vehicle Behaviour Prediction during Aggressive Lane Change for ACC Application
May 05, 2023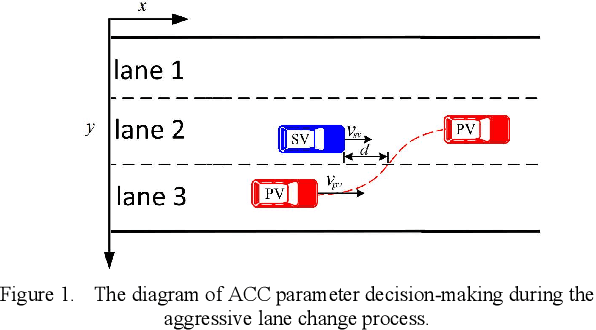
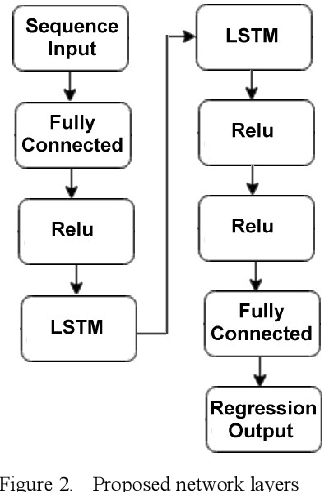
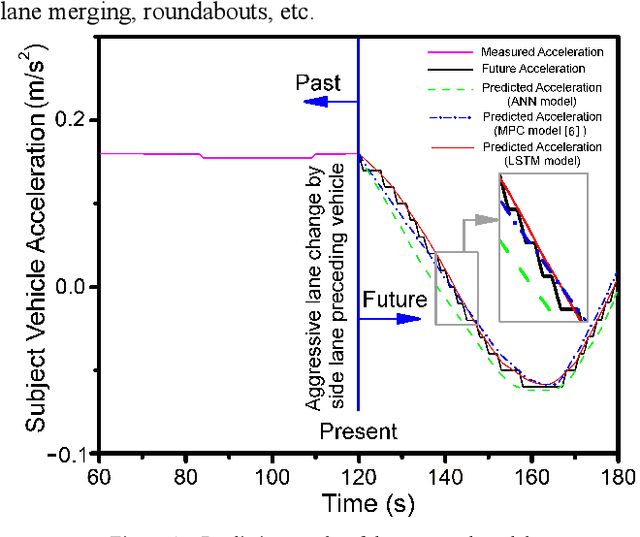
The development of Adaptive Cruise Control (ACC) systems aims to enhance the safety and comfort of vehicles by automatically regulating the speed of the vehicle to ensure a safe gap from the preceding vehicle. However, conventional ACC systems are unable to adapt themselves to changing driving conditions and drivers' behavior. To address this limitation, we propose a Long Short-Term Memory (LSTM) based ACC system that can learn from past driving experiences and adapt and predict new situations in real time. The model is constructed based on the real-world highD dataset, acquired from German highways with the assistance of camera-equipped drones. We evaluated the ACC system under aggressive lane changes when the side lane preceding vehicle cut off, forcing the targeted driver to reduce speed. To this end, the proposed system was assessed on a simulated driving environment and compared with a feedforward Artificial Neural Network (ANN) model and Model Predictive Control (MPC) model. The results show that the LSTM-based system is 19.25% more accurate than the ANN model and 5.9% more accurate than the MPC model in terms of predicting future values of subject vehicle acceleration. The simulation is done in Matlab/Simulink environment.
A Novel Model for Driver Lane Change Prediction in Cooperative Adaptive Cruise Control Systems
May 01, 2023



Accurate lane change prediction can reduce potential accidents and contribute to higher road safety. Adaptive cruise control (ACC), lane departure avoidance (LDA), and lane keeping assistance (LKA) are some conventional modules in advanced driver assistance systems (ADAS). Thanks to vehicle-to-vehicle communication (V2V), vehicles can share traffic information with surrounding vehicles, enabling cooperative adaptive cruise control (CACC). While ACC relies on the vehicle's sensors to obtain the position and velocity of the leading vehicle, CACC also has access to the acceleration of multiple vehicles through V2V communication. This paper compares the type of information (position, velocity, acceleration) and the number of surrounding vehicles for driver lane change prediction. We trained an LSTM (Long Short-Term Memory) on the HighD dataset to predict lane change intention. Results indicate a significant improvement in accuracy with an increase in the number of surrounding vehicles and the information received from them. Specifically, the proposed model can predict the ego vehicle lane change with 59.15% and 92.43% accuracy in ACC and CACC scenarios, respectively.
Local and Global Contextual Features Fusion for Pedestrian Intention Prediction
May 01, 2023


Autonomous vehicles (AVs) are becoming an indispensable part of future transportation. However, safety challenges and lack of reliability limit their real-world deployment. Towards boosting the appearance of AVs on the roads, the interaction of AVs with pedestrians including "prediction of the pedestrian crossing intention" deserves extensive research. This is a highly challenging task as involves multiple non-linear parameters. In this direction, we extract and analyse spatio-temporal visual features of both pedestrian and traffic contexts. The pedestrian features include body pose and local context features that represent the pedestrian's behaviour. Additionally, to understand the global context, we utilise location, motion, and environmental information using scene parsing technology that represents the pedestrian's surroundings, and may affect the pedestrian's intention. Finally, these multi-modality features are intelligently fused for effective intention prediction learning. The experimental results of the proposed model on the JAAD dataset show a superior result on the combined AUC and F1-score compared to the state-of-the-art.
Multi-level and multi-modal feature fusion for accurate 3D object detection in Connected and Automated Vehicles
Dec 19, 2022
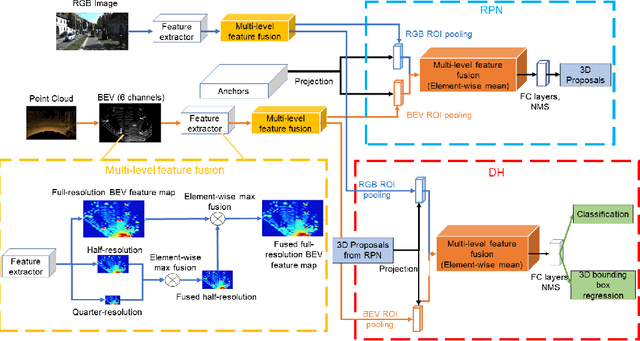
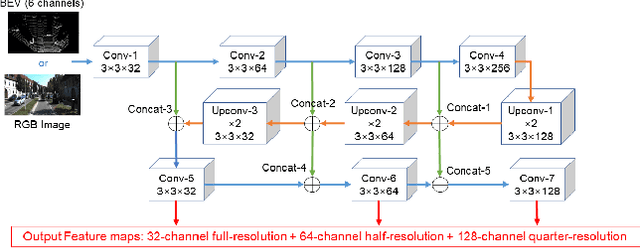

Aiming at highly accurate object detection for connected and automated vehicles (CAVs), this paper presents a Deep Neural Network based 3D object detection model that leverages a three-stage feature extractor by developing a novel LIDAR-Camera fusion scheme. The proposed feature extractor extracts high-level features from two input sensory modalities and recovers the important features discarded during the convolutional process. The novel fusion scheme effectively fuses features across sensory modalities and convolutional layers to find the best representative global features. The fused features are shared by a two-stage network: the region proposal network (RPN) and the detection head (DH). The RPN generates high-recall proposals, and the DH produces final detection results. The experimental results show the proposed model outperforms more recent research on the KITTI 2D and 3D detection benchmark, particularly for distant and highly occluded instances.
Multi-Module G2P Converter for Persian Focusing on Relations between Words
Aug 02, 2022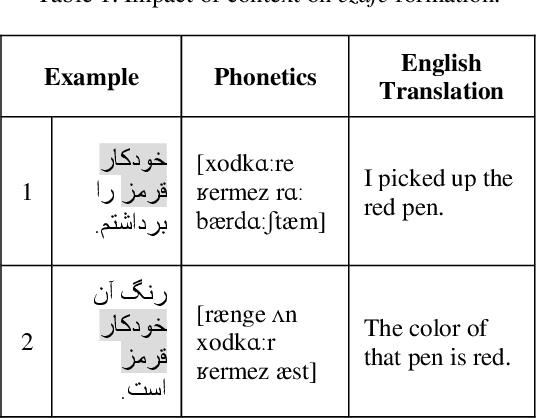
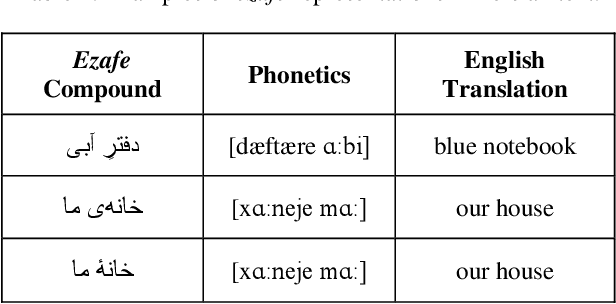
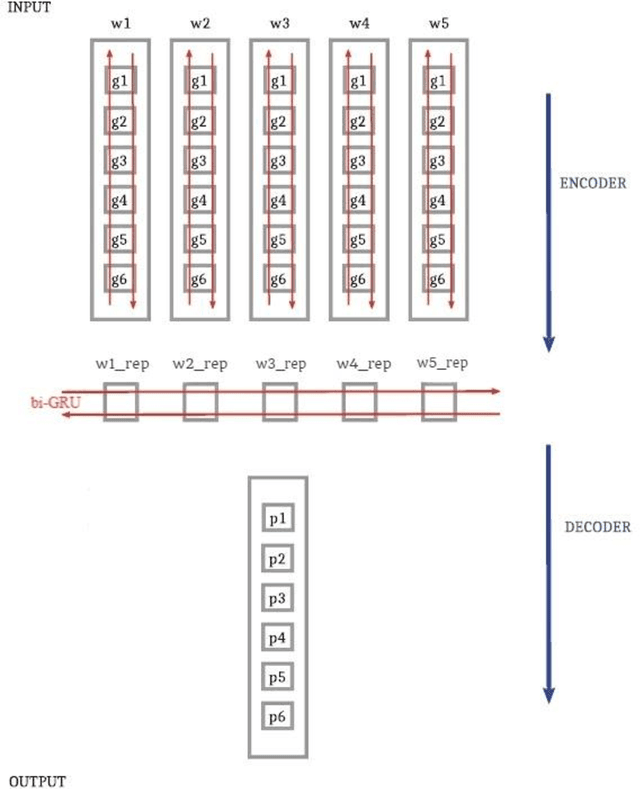
In this paper, we investigate the application of end-to-end and multi-module frameworks for G2P conversion for the Persian language. The results demonstrate that our proposed multi-module G2P system outperforms our end-to-end systems in terms of accuracy and speed. The system consists of a pronunciation dictionary as our look-up table, along with separate models to handle homographs, OOVs and ezafe in Persian created using GRU and Transformer architectures. The system is sequence-level rather than word-level, which allows it to effectively capture the unwritten relations between words (cross-word information) necessary for homograph disambiguation and ezafe recognition without the need for any pre-processing. After evaluation, our system achieved a 94.48% word-level accuracy, outperforming the previous G2P systems for Persian.