 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Calibrated Memorization Index (MI) for Detecting Training Data Leakage in Generative MRI Models
Feb 13, 2026Image generative models are known to duplicate images from the training data as part of their outputs, which can lead to privacy concerns when used for medical image generation. We propose a calibrated per-sample metric for detecting memorization and duplication of training data. Our metric uses image features extracted using an MRI foundation model, aggregates multi-layer whitened nearest-neighbor similarities, and maps them to a bounded \emph{Overfit/Novelty Index} (ONI) and \emph{Memorization Index} (MI) scores. Across three MRI datasets with controlled duplication percentages and typical image augmentations, our metric robustly detects duplication and provides more consistent metric values across datasets. At the sample level, our metric achieves near-perfect detection of duplicates.
WeatherEdit: Controllable Weather Editing with 4D Gaussian Field
May 26, 2025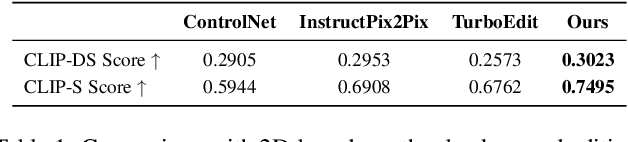
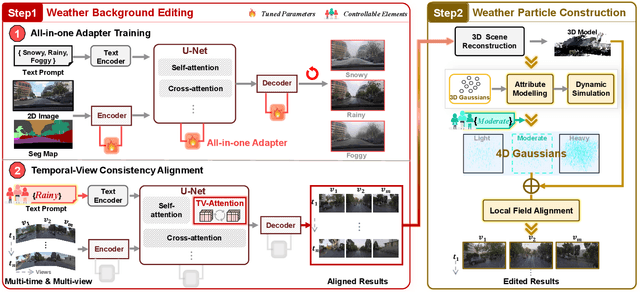


In this work, we present WeatherEdit, a novel weather editing pipeline for generating realistic weather effects with controllable types and severity in 3D scenes. Our approach is structured into two key components: weather background editing and weather particle construction. For weather background editing, we introduce an all-in-one adapter that integrates multiple weather styles into a single pretrained diffusion model, enabling the generation of diverse weather effects in 2D image backgrounds. During inference, we design a Temporal-View (TV-) attention mechanism that follows a specific order to aggregate temporal and spatial information, ensuring consistent editing across multi-frame and multi-view images. To construct the weather particles, we first reconstruct a 3D scene using the edited images and then introduce a dynamic 4D Gaussian field to generate snowflakes, raindrops and fog in the scene. The attributes and dynamics of these particles are precisely controlled through physical-based modelling and simulation, ensuring realistic weather representation and flexible severity adjustments. Finally, we integrate the 4D Gaussian field with the 3D scene to render consistent and highly realistic weather effects. Experiments on multiple driving datasets demonstrate that WeatherEdit can generate diverse weather effects with controllable condition severity, highlighting its potential for autonomous driving simulation in adverse weather. See project page: https://jumponthemoon.github.io/w-edit
WeatherGS: 3D Scene Reconstruction in Adverse Weather Conditions via Gaussian Splatting
Dec 25, 2024



3D Gaussian Splatting (3DGS) has gained significant attention for 3D scene reconstruction, but still suffers from complex outdoor environments, especially under adverse weather. This is because 3DGS treats the artifacts caused by adverse weather as part of the scene and will directly reconstruct them, largely reducing the clarity of the reconstructed scene. To address this challenge, we propose WeatherGS, a 3DGS-based framework for reconstructing clear scenes from multi-view images under different weather conditions. Specifically, we explicitly categorize the multi-weather artifacts into the dense particles and lens occlusions that have very different characters, in which the former are caused by snowflakes and raindrops in the air, and the latter are raised by the precipitation on the camera lens. In light of this, we propose a dense-to-sparse preprocess strategy, which sequentially removes the dense particles by an Atmospheric Effect Filter (AEF) and then extracts the relatively sparse occlusion masks with a Lens Effect Detector (LED). Finally, we train a set of 3D Gaussians by the processed images and generated masks for excluding occluded areas, and accurately recover the underlying clear scene by Gaussian splatting. We conduct a diverse and challenging benchmark to facilitate the evaluation of 3D reconstruction under complex weather scenarios. Extensive experiments on this benchmark demonstrate that our WeatherGS consistently produces high-quality, clean scenes across various weather scenarios, outperforming existing state-of-the-art methods. See project page:https://jumponthemoon.github.io/weather-gs.
WeatherDG: LLM-assisted Procedural Weather Generation for Domain-Generalized Semantic Segmentation
Oct 15, 2024In this work, we propose a novel approach, namely WeatherDG, that can generate realistic, weather-diverse, and driving-screen images based on the cooperation of two foundation models, i.e, Stable Diffusion (SD) and Large Language Model (LLM). Specifically, we first fine-tune the SD with source data, aligning the content and layout of generated samples with real-world driving scenarios. Then, we propose a procedural prompt generation method based on LLM, which can enrich scenario descriptions and help SD automatically generate more diverse, detailed images. In addition, we introduce a balanced generation strategy, which encourages the SD to generate high-quality objects of tailed classes under various weather conditions, such as riders and motorcycles. This segmentation-model-agnostic method can improve the generalization ability of existing models by additionally adapting them with the generated synthetic data. Experiments on three challenging datasets show that our method can significantly improve the segmentation performance of different state-of-the-art models on target domains. Notably, in the setting of ''Cityscapes to ACDC'', our method improves the baseline HRDA by 13.9% in mIoU.
AllWeatherNet:Unified Image enhancement for autonomous driving under adverse weather and lowlight-conditions
Sep 03, 2024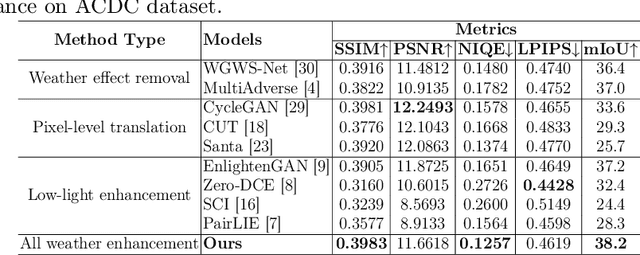

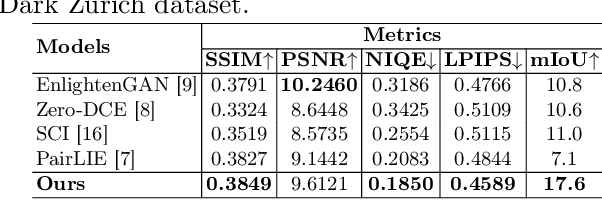
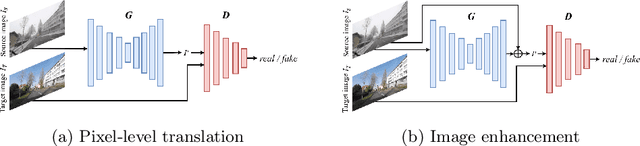
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on only one specific condition, such as removing rain or translating nighttime images into daytime ones. To address these limitations, we propose a method to improve the visual quality and clarity degraded by such adverse conditions. Our method, AllWeather-Net, utilizes a novel hierarchical architecture to enhance images across all adverse conditions. This architecture incorporates information at three semantic levels: scene, object, and texture, by discriminating patches at each level. Furthermore, we introduce a Scaled Illumination-aware Attention Mechanism (SIAM) that guides the learning towards road elements critical for autonomous driving perception. SIAM exhibits robustness, remaining unaffected by changes in weather conditions or environmental scenes. AllWeather-Net effectively transforms images into normal weather and daytime scenes, demonstrating superior image enhancement results and subsequently enhancing the performance of semantic segmentation, with up to a 5.3% improvement in mIoU in the trained domain. We also show our model's generalization ability by applying it to unseen domains without re-training, achieving up to 3.9% mIoU improvement. Code can be accessed at: https://github.com/Jumponthemoon/AllWeatherNet.
Local and Global Contextual Features Fusion for Pedestrian Intention Prediction
May 01, 2023


Autonomous vehicles (AVs) are becoming an indispensable part of future transportation. However, safety challenges and lack of reliability limit their real-world deployment. Towards boosting the appearance of AVs on the roads, the interaction of AVs with pedestrians including "prediction of the pedestrian crossing intention" deserves extensive research. This is a highly challenging task as involves multiple non-linear parameters. In this direction, we extract and analyse spatio-temporal visual features of both pedestrian and traffic contexts. The pedestrian features include body pose and local context features that represent the pedestrian's behaviour. Additionally, to understand the global context, we utilise location, motion, and environmental information using scene parsing technology that represents the pedestrian's surroundings, and may affect the pedestrian's intention. Finally, these multi-modality features are intelligently fused for effective intention prediction learning. The experimental results of the proposed model on the JAAD dataset show a superior result on the combined AUC and F1-score compared to the state-of-the-art.