 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAtlas: Navigating Long-Form Video in Logarithmic Compute
Mar 18, 2026Extending language models to video introduces two challenges: representation, where existing methods rely on lossy approximations, and long-context, where caption- or agent-based pipelines collapse video into text and lose visual fidelity. To overcome this, we introduce \textbf{VideoAtlas}, a task-agnostic environment to represent video as a hierarchical grid that is simultaneously lossless, navigable, scalable, caption- and preprocessing-free. An overview of the video is available at a glance, and any region can be recursively zoomed into, with the same visual representation used uniformly for the video, intermediate investigations, and the agent's memory, eliminating lossy text conversion end-to-end. This hierarchical structure ensures access depth grows only logarithmically with video length. For long-context, Recursive Language Models (RLMs) recently offered a powerful solution for long text, but extending them to visual domain requires a structured environment to recurse into, which \textbf{VideoAtlas} provides. \textbf{VideoAtlas} as a Markov Decision Process unlocks Video-RLM: a parallel Master-Worker architecture where a Master coordinates global exploration while Workers concurrently drill into assigned regions to accumulate lossless visual evidence. We demonstrate three key findings: (1)~logarithmic compute growth with video duration, further amplified by a 30-60\% multimodal cache hit rate arising from the grid's structural reuse. (2)~environment budgeting, where bounding the maximum exploration depth provides a principled compute-accuracy hyperparameter. (3)~emergent adaptive compute allocation that scales with question granularity. When scaling from 1-hour to 10-hour benchmarks, Video-RLM remains the most duration-robust method with minimal accuracy degradation, demonstrating that structured environment navigation is a viable and scalable paradigm for video understanding.
Multimodal Lengthy Videos Retrieval Framework and Evaluation Metric
Apr 06, 2025
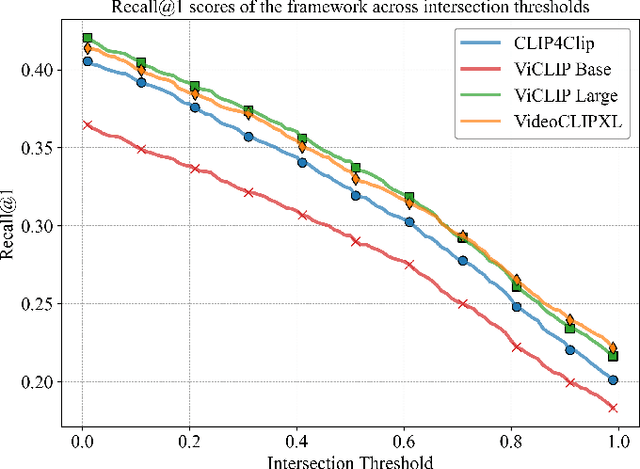


Precise video retrieval requires multi-modal correlations to handle unseen vocabulary and scenes, becoming more complex for lengthy videos where models must perform effectively without prior training on a specific dataset. We introduce a unified framework that combines a visual matching stream and an aural matching stream with a unique subtitles-based video segmentation approach. Additionally, the aural stream includes a complementary audio-based two-stage retrieval mechanism that enhances performance on long-duration videos. Considering the complex nature of retrieval from lengthy videos and its corresponding evaluation, we introduce a new retrieval evaluation method specifically designed for long-video retrieval to support further research. We conducted experiments on the YouCook2 benchmark, showing promising retrieval performance.
AllWeatherNet:Unified Image enhancement for autonomous driving under adverse weather and lowlight-conditions
Sep 03, 2024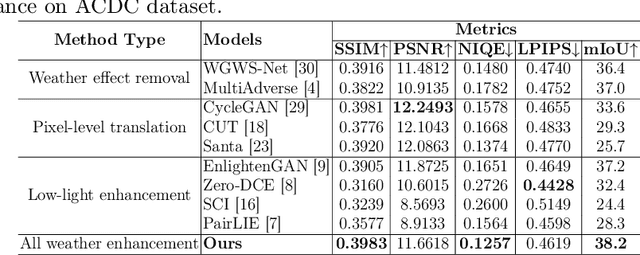

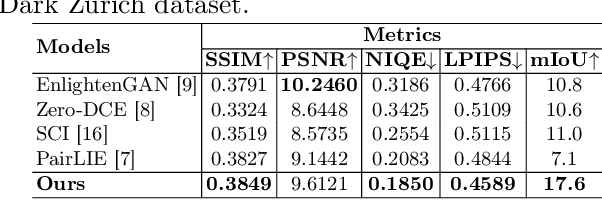
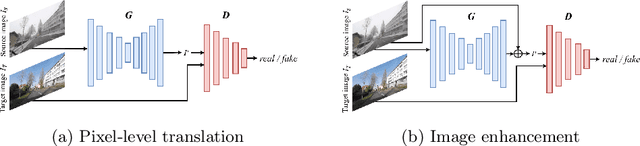
Adverse conditions like snow, rain, nighttime, and fog, pose challenges for autonomous driving perception systems. Existing methods have limited effectiveness in improving essential computer vision tasks, such as semantic segmentation, and often focus on only one specific condition, such as removing rain or translating nighttime images into daytime ones. To address these limitations, we propose a method to improve the visual quality and clarity degraded by such adverse conditions. Our method, AllWeather-Net, utilizes a novel hierarchical architecture to enhance images across all adverse conditions. This architecture incorporates information at three semantic levels: scene, object, and texture, by discriminating patches at each level. Furthermore, we introduce a Scaled Illumination-aware Attention Mechanism (SIAM) that guides the learning towards road elements critical for autonomous driving perception. SIAM exhibits robustness, remaining unaffected by changes in weather conditions or environmental scenes. AllWeather-Net effectively transforms images into normal weather and daytime scenes, demonstrating superior image enhancement results and subsequently enhancing the performance of semantic segmentation, with up to a 5.3% improvement in mIoU in the trained domain. We also show our model's generalization ability by applying it to unseen domains without re-training, achieving up to 3.9% mIoU improvement. Code can be accessed at: https://github.com/Jumponthemoon/AllWeatherNet.
Local and Global Contextual Features Fusion for Pedestrian Intention Prediction
May 01, 2023


Autonomous vehicles (AVs) are becoming an indispensable part of future transportation. However, safety challenges and lack of reliability limit their real-world deployment. Towards boosting the appearance of AVs on the roads, the interaction of AVs with pedestrians including "prediction of the pedestrian crossing intention" deserves extensive research. This is a highly challenging task as involves multiple non-linear parameters. In this direction, we extract and analyse spatio-temporal visual features of both pedestrian and traffic contexts. The pedestrian features include body pose and local context features that represent the pedestrian's behaviour. Additionally, to understand the global context, we utilise location, motion, and environmental information using scene parsing technology that represents the pedestrian's surroundings, and may affect the pedestrian's intention. Finally, these multi-modality features are intelligently fused for effective intention prediction learning. The experimental results of the proposed model on the JAAD dataset show a superior result on the combined AUC and F1-score compared to the state-of-the-art.
Pyramidal Attention for Saliency Detection
Apr 14, 2022

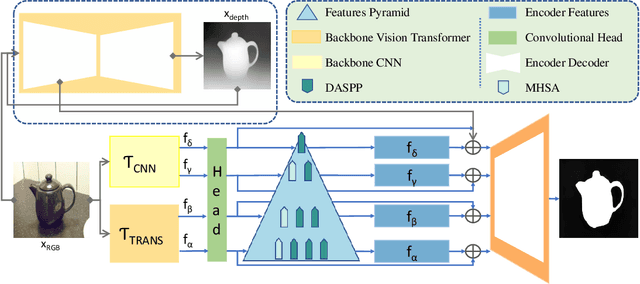
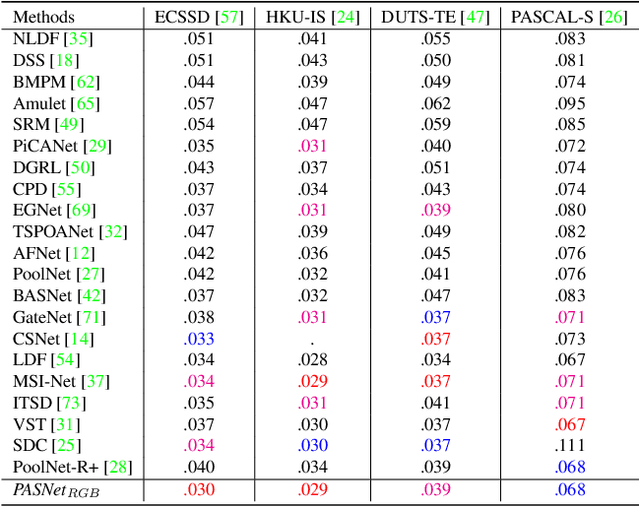
Salient object detection (SOD) extracts meaningful contents from an input image. RGB-based SOD methods lack the complementary depth clues; hence, providing limited performance for complex scenarios. Similarly, RGB-D models process RGB and depth inputs, but the depth data availability during testing may hinder the model's practical applicability. This paper exploits only RGB images, estimates depth from RGB, and leverages the intermediate depth features. We employ a pyramidal attention structure to extract multi-level convolutional-transformer features to process initial stage representations and further enhance the subsequent ones. At each stage, the backbone transformer model produces global receptive fields and computing in parallel to attain fine-grained global predictions refined by our residual convolutional attention decoder for optimal saliency prediction. We report significantly improved performance against 21 and 40 state-of-the-art SOD methods on eight RGB and RGB-D datasets, respectively. Consequently, we present a new SOD perspective of generating RGB-D SOD without acquiring depth data during training and testing and assist RGB methods with depth clues for improved performance. The code and trained models are available at https://github.com/tanveer-hussain/EfficientSOD2
Densely Deformable Efficient Salient Object Detection Network
Feb 12, 2021
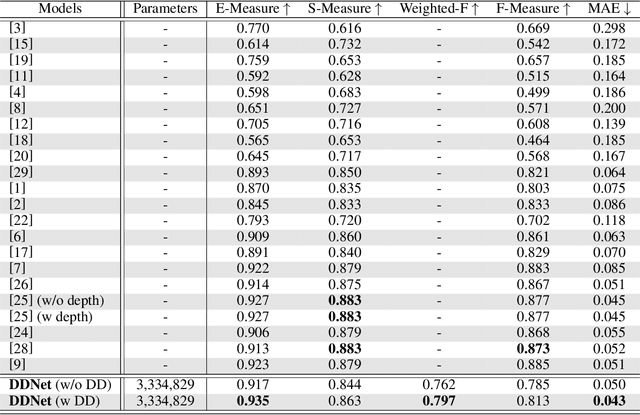

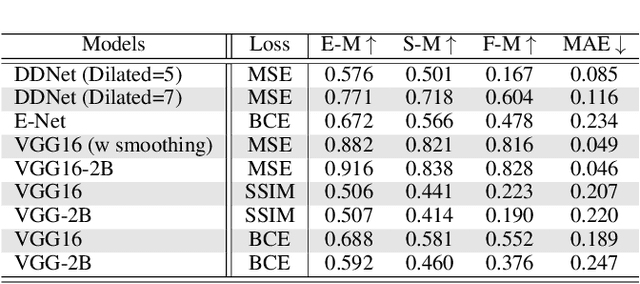
Salient Object Detection (SOD) domain using RGB-D data has lately emerged with some current models' adequately precise results. However, they have restrained generalization abilities and intensive computational complexity. In this paper, inspired by the best background/foreground separation abilities of deformable convolutions, we employ them in our Densely Deformable Network (DDNet) to achieve efficient SOD. The salient regions from densely deformable convolutions are further refined using transposed convolutions to optimally generate the saliency maps. Quantitative and qualitative evaluations using the recent SOD dataset against 22 competing techniques show our method's efficiency and effectiveness. We also offer evaluation using our own created cross-dataset, surveillance-SOD (S-SOD), to check the trained models' validity in terms of their applicability in diverse scenarios. The results indicate that the current models have limited generalization potentials, demanding further research in this direction. Our code and new dataset will be publicly available at https://github.com/tanveer-hussain/EfficientSOD