 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidal Attention for Saliency Detection
Paper and Code


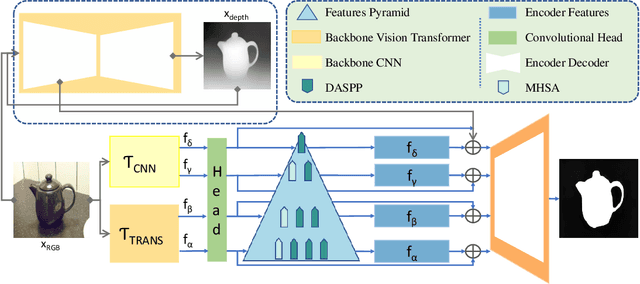
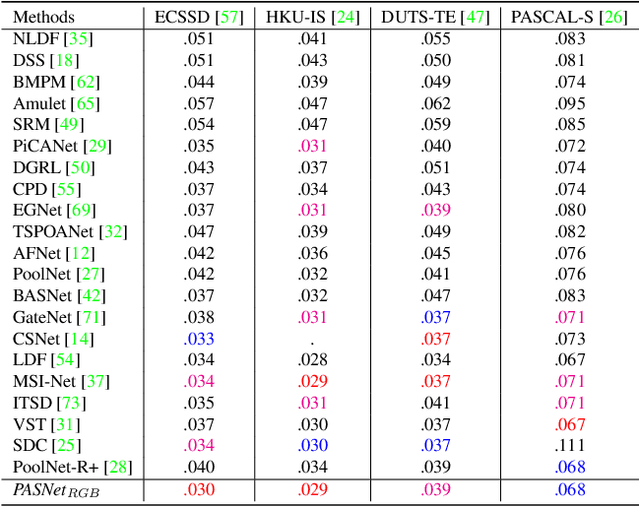
Salient object detection (SOD) extracts meaningful contents from an input image. RGB-based SOD methods lack the complementary depth clues; hence, providing limited performance for complex scenarios. Similarly, RGB-D models process RGB and depth inputs, but the depth data availability during testing may hinder the model's practical applicability. This paper exploits only RGB images, estimates depth from RGB, and leverages the intermediate depth features. We employ a pyramidal attention structure to extract multi-level convolutional-transformer features to process initial stage representations and further enhance the subsequent ones. At each stage, the backbone transformer model produces global receptive fields and computing in parallel to attain fine-grained global predictions refined by our residual convolutional attention decoder for optimal saliency prediction. We report significantly improved performance against 21 and 40 state-of-the-art SOD methods on eight RGB and RGB-D datasets, respectively. Consequently, we present a new SOD perspective of generating RGB-D SOD without acquiring depth data during training and testing and assist RGB methods with depth clues for improved performance. The code and trained models are available at https://github.com/tanveer-hussain/EfficientSOD2