 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidal Attention for Saliency Detection
Apr 14, 2022

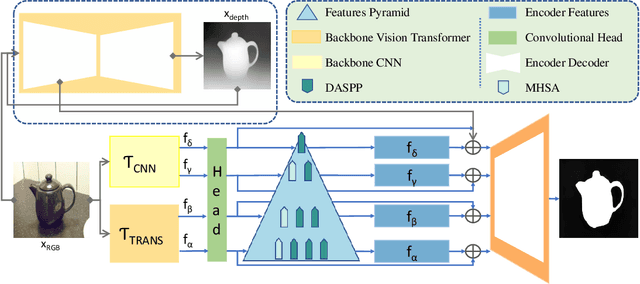
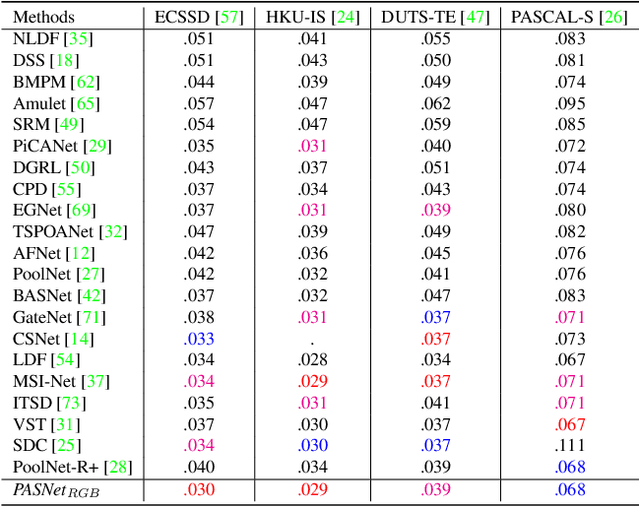
Salient object detection (SOD) extracts meaningful contents from an input image. RGB-based SOD methods lack the complementary depth clues; hence, providing limited performance for complex scenarios. Similarly, RGB-D models process RGB and depth inputs, but the depth data availability during testing may hinder the model's practical applicability. This paper exploits only RGB images, estimates depth from RGB, and leverages the intermediate depth features. We employ a pyramidal attention structure to extract multi-level convolutional-transformer features to process initial stage representations and further enhance the subsequent ones. At each stage, the backbone transformer model produces global receptive fields and computing in parallel to attain fine-grained global predictions refined by our residual convolutional attention decoder for optimal saliency prediction. We report significantly improved performance against 21 and 40 state-of-the-art SOD methods on eight RGB and RGB-D datasets, respectively. Consequently, we present a new SOD perspective of generating RGB-D SOD without acquiring depth data during training and testing and assist RGB methods with depth clues for improved performance. The code and trained models are available at https://github.com/tanveer-hussain/EfficientSOD2
Densely Deformable Efficient Salient Object Detection Network
Feb 12, 2021
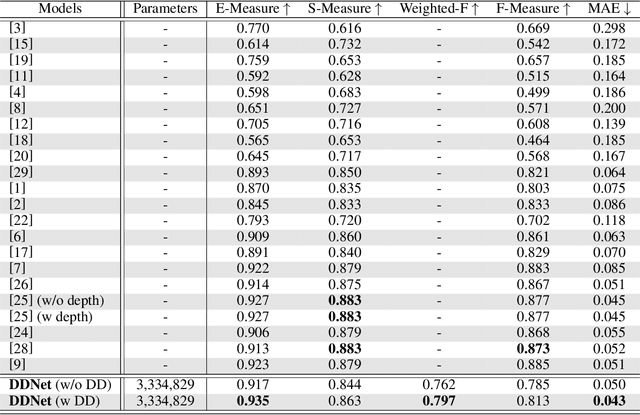

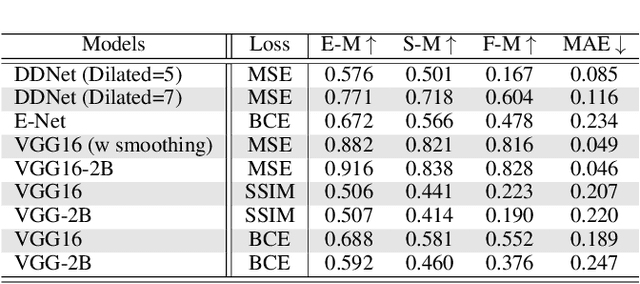
Salient Object Detection (SOD) domain using RGB-D data has lately emerged with some current models' adequately precise results. However, they have restrained generalization abilities and intensive computational complexity. In this paper, inspired by the best background/foreground separation abilities of deformable convolutions, we employ them in our Densely Deformable Network (DDNet) to achieve efficient SOD. The salient regions from densely deformable convolutions are further refined using transposed convolutions to optimally generate the saliency maps. Quantitative and qualitative evaluations using the recent SOD dataset against 22 competing techniques show our method's efficiency and effectiveness. We also offer evaluation using our own created cross-dataset, surveillance-SOD (S-SOD), to check the trained models' validity in terms of their applicability in diverse scenarios. The results indicate that the current models have limited generalization potentials, demanding further research in this direction. Our code and new dataset will be publicly available at https://github.com/tanveer-hussain/EfficientSOD
Divide-and-Conquer based Ensemble to Spot Emotions in Speech using MFCC and Random Forest
Oct 05, 2016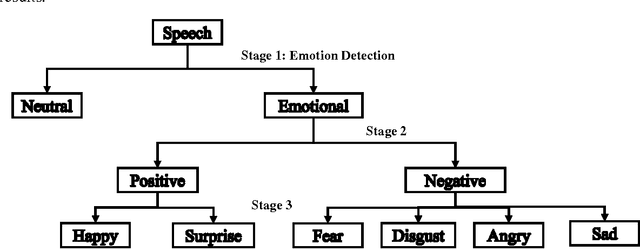
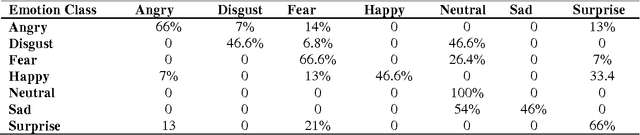
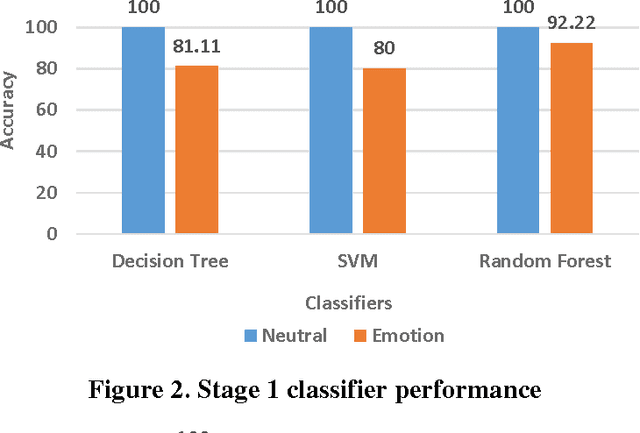
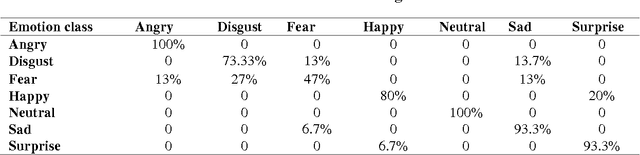
Besides spoken words, speech signals also carry information about speaker gender, age, and emotional state which can be used in a variety of speech analysis applications. In this paper, a divide and conquer strategy for ensemble classification has been proposed to recognize emotions in speech. Intrinsic hierarchy in emotions has been utilized to construct an emotions tree, which assisted in breaking down the emotion recognition task into smaller sub tasks. The proposed framework generates predictions in three phases. Firstly, emotions are detected in the input speech signal by classifying it as neutral or emotional. If the speech is classified as emotional, then in the second phase, it is further classified into positive and negative classes. Finally, individual positive or negative emotions are identified based on the outcomes of the previous stages. Several experiments have been performed on a widely used benchmark dataset. The proposed method was able to achieve improved recognition rates as compared to several other approaches.
Describing Colors, Textures and Shapes for Content Based Image Retrieval - A Survey
Feb 25, 2015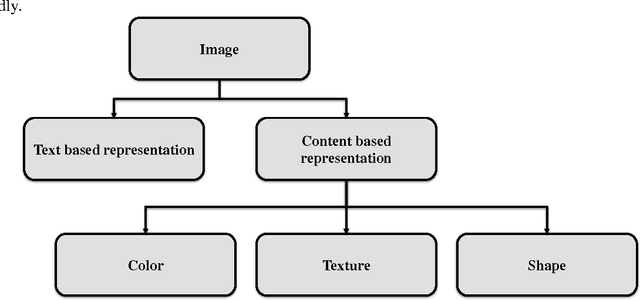
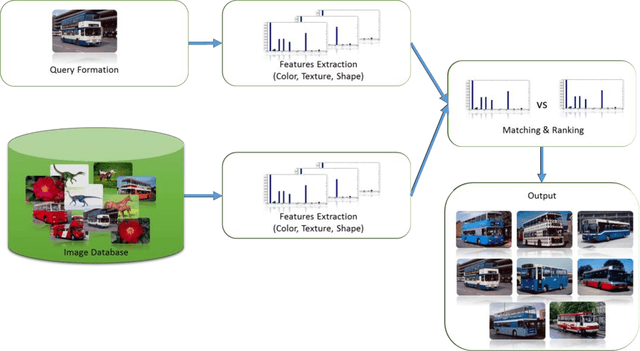
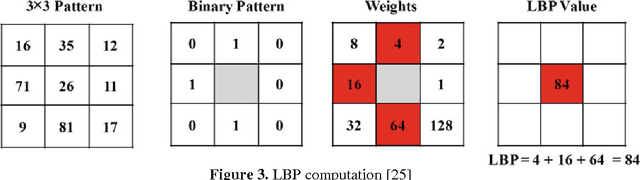
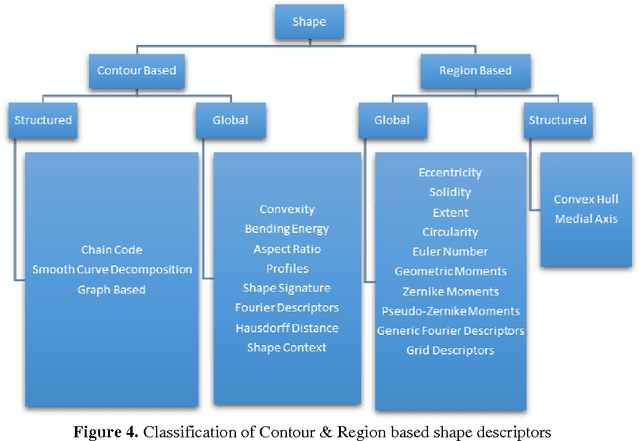
Visual media has always been the most enjoyed way of communication. From the advent of television to the modern day hand held computers, we have witnessed the exponential growth of images around us. Undoubtedly it's a fact that they carry a lot of information in them which needs be utilized in an effective manner. Hence intense need has been felt to efficiently index and store large image collections for effective and on- demand retrieval. For this purpose low-level features extracted from the image contents like color, texture and shape has been used. Content based image retrieval systems employing these features has proven very successful. Image retrieval has promising applications in numerous fields and hence has motivated researchers all over the world. New and improved ways to represent visual content are being developed each day. Tremendous amount of research has been carried out in the last decade. In this paper we will present a detailed overview of some of the powerful color, texture and shape descriptors for content based image retrieval. A comparative analysis will also be carried out for providing an insight into outstanding challenges in this field.