 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFace: A Training-Free Approach for Diffusion-Based Video Face Swapping
Feb 08, 2026We present a training-free, plug-and-play method, namely VFace, for high-quality face swapping in videos. It can be seamlessly integrated with image-based face swapping approaches built on diffusion models. First, we introduce a Frequency Spectrum Attention Interpolation technique to facilitate generation and intact key identity characteristics. Second, we achieve Target Structure Guidance via plug-and-play attention injection to better align the structural features from the target frame to the generation. Third, we present a Flow-Guided Attention Temporal Smoothening mechanism that enforces spatiotemporal coherence without modifying the underlying diffusion model to reduce temporal inconsistencies typically encountered in frame-wise generation. Our method requires no additional training or video-specific fine-tuning. Extensive experiments show that our method significantly enhances temporal consistency and visual fidelity, offering a practical and modular solution for video-based face swapping. Our code is available at https://github.com/Sanoojan/VFace.
SpecGuard: Spectral Projection-based Advanced Invisible Watermarking
Oct 08, 2025



Watermarking embeds imperceptible patterns into images for authenticity verification. However, existing methods often lack robustness against various transformations primarily including distortions, image regeneration, and adversarial perturbation, creating real-world challenges. In this work, we introduce SpecGuard, a novel watermarking approach for robust and invisible image watermarking. Unlike prior approaches, we embed the message inside hidden convolution layers by converting from the spatial domain to the frequency domain using spectral projection of a higher frequency band that is decomposed by wavelet projection. Spectral projection employs Fast Fourier Transform approximation to transform spatial data into the frequency domain efficiently. In the encoding phase, a strength factor enhances resilience against diverse attacks, including adversarial, geometric, and regeneration-based distortions, ensuring the preservation of copyrighted information. Meanwhile, the decoder leverages Parseval's theorem to effectively learn and extract the watermark pattern, enabling accurate retrieval under challenging transformations. We evaluate the proposed SpecGuard based on the embedded watermark's invisibility, capacity, and robustness. Comprehensive experiments demonstrate the proposed SpecGuard outperforms the state-of-the-art models. To ensure reproducibility, the full code is released on \href{https://github.com/inzamamulDU/SpecGuard_ICCV_2025}{\textcolor{blue}{\textbf{GitHub}}}.
Robust and Label-Efficient Deep Waste Detection
Aug 26, 2025Effective waste sorting is critical for sustainable recycling, yet AI research in this domain continues to lag behind commercial systems due to limited datasets and reliance on legacy object detectors. In this work, we advance AI-driven waste detection by establishing strong baselines and introducing an ensemble-based semi-supervised learning framework. We first benchmark state-of-the-art Open-Vocabulary Object Detection (OVOD) models on the real-world ZeroWaste dataset, demonstrating that while class-only prompts perform poorly, LLM-optimized prompts significantly enhance zero-shot accuracy. Next, to address domain-specific limitations, we fine-tune modern transformer-based detectors, achieving a new baseline of 51.6 mAP. We then propose a soft pseudo-labeling strategy that fuses ensemble predictions using spatial and consensus-aware weighting, enabling robust semi-supervised training. Applied to the unlabeled ZeroWaste-s subset, our pseudo-annotations achieve performance gains that surpass fully supervised training, underscoring the effectiveness of scalable annotation pipelines. Our work contributes to the research community by establishing rigorous baselines, introducing a robust ensemble-based pseudo-labeling pipeline, generating high-quality annotations for the unlabeled ZeroWaste-s subset, and systematically evaluating OVOD models under real-world waste sorting conditions. Our code is available at: https://github.com/h-abid97/robust-waste-detection.
LoLI-Street: Benchmarking Low-Light Image Enhancement and Beyond
Oct 13, 2024Low-light image enhancement (LLIE) is essential for numerous computer vision tasks, including object detection, tracking, segmentation, and scene understanding. Despite substantial research on improving low-quality images captured in underexposed conditions, clear vision remains critical for autonomous vehicles, which often struggle with low-light scenarios, signifying the need for continuous research. However, paired datasets for LLIE are scarce, particularly for street scenes, limiting the development of robust LLIE methods. Despite using advanced transformers and/or diffusion-based models, current LLIE methods struggle in real-world low-light conditions and lack training on street-scene datasets, limiting their effectiveness for autonomous vehicles. To bridge these gaps, we introduce a new dataset LoLI-Street (Low-Light Images of Streets) with 33k paired low-light and well-exposed images from street scenes in developed cities, covering 19k object classes for object detection. LoLI-Street dataset also features 1,000 real low-light test images for testing LLIE models under real-life conditions. Furthermore, we propose a transformer and diffusion-based LLIE model named "TriFuse". Leveraging the LoLI-Street dataset, we train and evaluate our TriFuse and SOTA models to benchmark on our dataset. Comparing various models, our dataset's generalization feasibility is evident in testing across different mainstream datasets by significantly enhancing images and object detection for practical applications in autonomous driving and surveillance systems. The complete code and dataset is available on https://github.com/tanvirnwu/TriFuse.
Cefdet: Cognitive Effectiveness Network Based on Fuzzy Inference for Action Detection
Oct 08, 2024
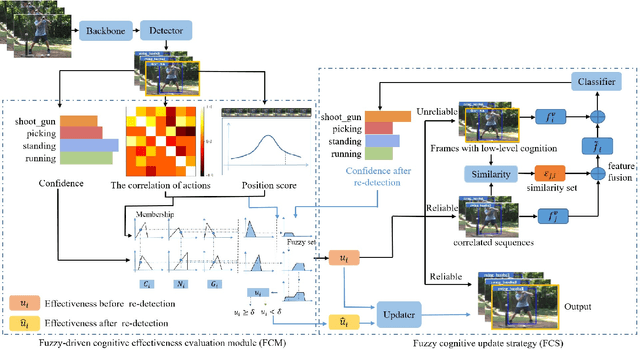
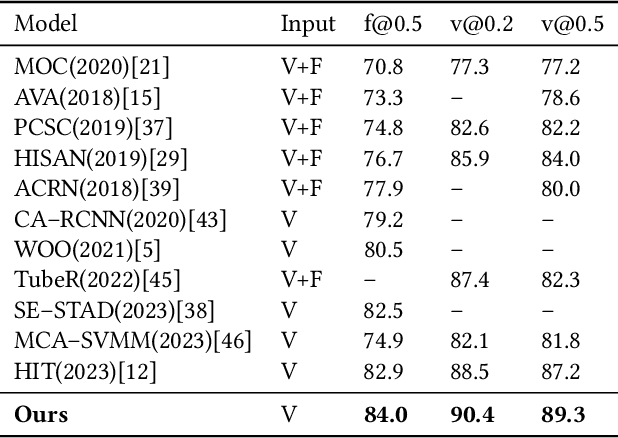
Action detection and understanding provide the foundation for the generation and interaction of multimedia content. However, existing methods mainly focus on constructing complex relational inference networks, overlooking the judgment of detection effectiveness. Moreover, these methods frequently generate detection results with cognitive abnormalities. To solve the above problems, this study proposes a cognitive effectiveness network based on fuzzy inference (Cefdet), which introduces the concept of "cognition-based detection" to simulate human cognition. First, a fuzzy-driven cognitive effectiveness evaluation module (FCM) is established to introduce fuzzy inference into action detection. FCM is combined with human action features to simulate the cognition-based detection process, which clearly locates the position of frames with cognitive abnormalities. Then, a fuzzy cognitive update strategy (FCS) is proposed based on the FCM, which utilizes fuzzy logic to re-detect the cognition-based detection results and effectively update the results with cognitive abnormalities. Experimental results demonstrate that Cefdet exhibits superior performance against several mainstream algorithms on the public datasets, validating its effectiveness and superiority.
HazeSpace2M: A Dataset for Haze Aware Single Image Dehazing
Sep 25, 2024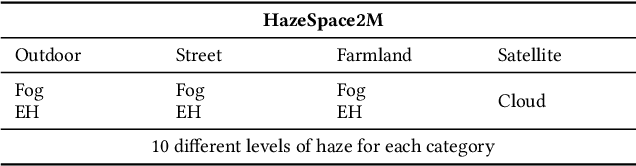
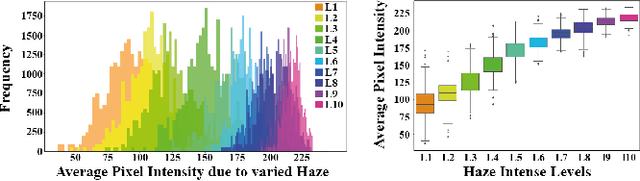
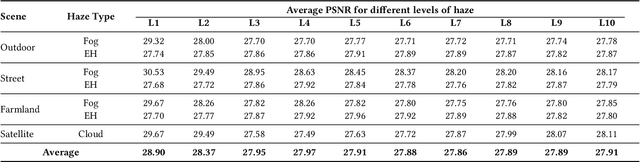
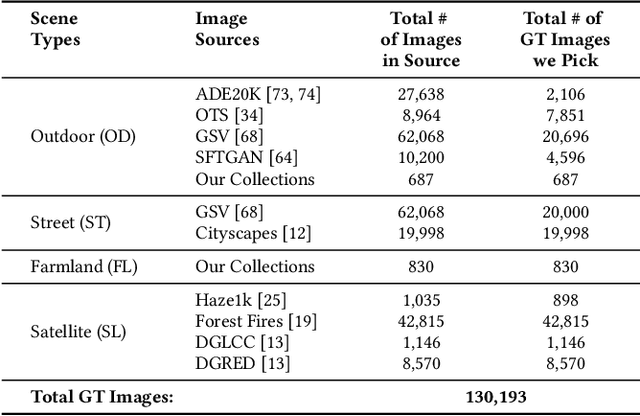
Reducing the atmospheric haze and enhancing image clarity is crucial for computer vision applications. The lack of real-life hazy ground truth images necessitates synthetic datasets, which often lack diverse haze types, impeding effective haze type classification and dehazing algorithm selection. This research introduces the HazeSpace2M dataset, a collection of over 2 million images designed to enhance dehazing through haze type classification. HazeSpace2M includes diverse scenes with 10 haze intensity levels, featuring Fog, Cloud, and Environmental Haze (EH). Using the dataset, we introduce a technique of haze type classification followed by specialized dehazers to clear hazy images. Unlike conventional methods, our approach classifies haze types before applying type-specific dehazing, improving clarity in real-life hazy images. Benchmarking with state-of-the-art (SOTA) models, ResNet50 and AlexNet achieve 92.75\% and 92.50\% accuracy, respectively, against existing synthetic datasets. However, these models achieve only 80% and 70% accuracy, respectively, against our Real Hazy Testset (RHT), highlighting the challenging nature of our HazeSpace2M dataset. Additional experiments show that haze type classification followed by specialized dehazing improves results by 2.41% in PSNR, 17.14% in SSIM, and 10.2\% in MSE over general dehazers. Moreover, when testing with SOTA dehazing models, we found that applying our proposed framework significantly improves their performance. These results underscore the significance of HazeSpace2M and our proposed framework in addressing atmospheric haze in multimedia processing. Complete code and dataset is available on \href{https://github.com/tanvirnwu/HazeSpace2M} {\textcolor{blue}{\textbf{GitHub}}}.
* Accepted by ACM Multimedia 2024
FallDeF5: A Fall Detection Framework Using 5G-based Deep Gated Recurrent Unit Networks
Jun 29, 2021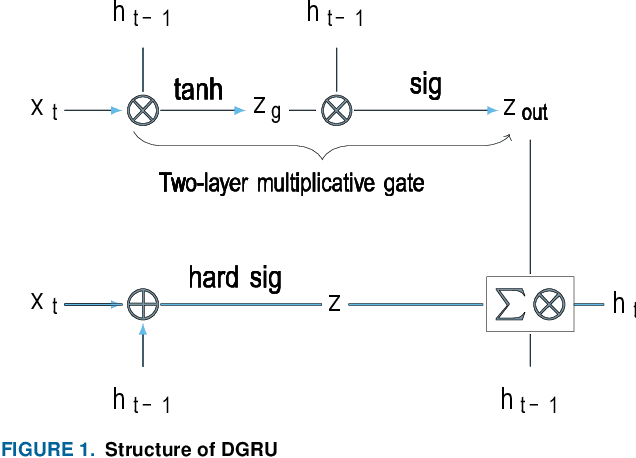
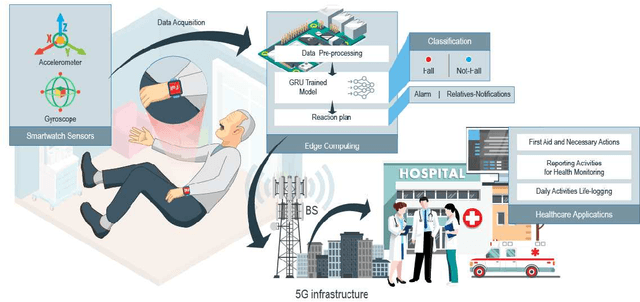
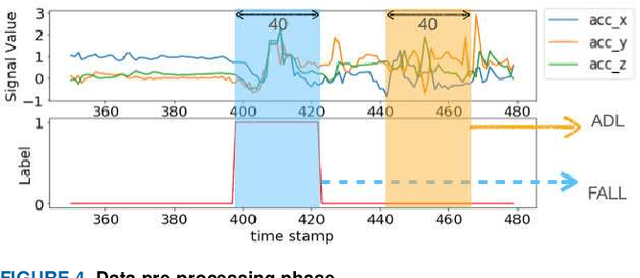
Fall prevalence is high among elderly people, which is challenging due to the severe consequences of falling. This is why rapid assistance is a critical task. Ambient assisted living (AAL) uses recent technologies such as 5G networks and the internet of medical things (IoMT) to address this research area. Edge computing can reduce the cost of cloud communication, including high latency and bandwidth use, by moving conventional healthcare services and applications closer to end-users. Artificial intelligence (AI) techniques such as deep learning (DL) have been used recently for automatic fall detection, as well as supporting healthcare services. However, DL requires a vast amount of data and substantial processing power to improve its performance for the IoMT linked to the traditional edge computing environment. This research proposes an effective fall detection framework based on DL algorithms and mobile edge computing (MEC) within 5G wireless networks, the aim being to empower IoMT-based healthcare applications. We also propose the use of a deep gated recurrent unit (DGRU) neural network to improve the accuracy of existing DL-based fall detection methods. DGRU has the advantage of dealing with time-series IoMT data, and it can reduce the number of parameters and avoid the vanishing gradient problem. The experimental results on two public datasets show that the DGRU model of the proposed framework achieves higher accuracy rates compared to the current related works on the same datasets.
Densely Deformable Efficient Salient Object Detection Network
Feb 12, 2021
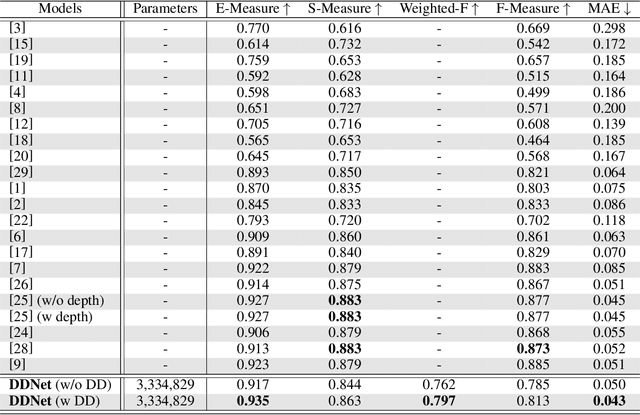

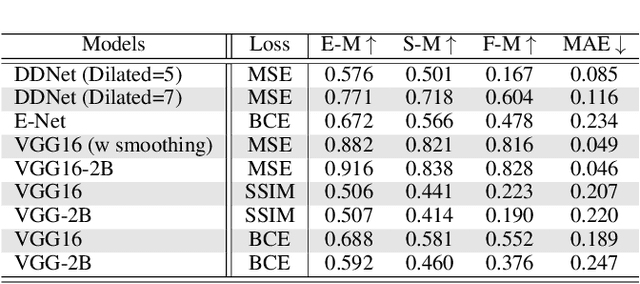
Salient Object Detection (SOD) domain using RGB-D data has lately emerged with some current models' adequately precise results. However, they have restrained generalization abilities and intensive computational complexity. In this paper, inspired by the best background/foreground separation abilities of deformable convolutions, we employ them in our Densely Deformable Network (DDNet) to achieve efficient SOD. The salient regions from densely deformable convolutions are further refined using transposed convolutions to optimally generate the saliency maps. Quantitative and qualitative evaluations using the recent SOD dataset against 22 competing techniques show our method's efficiency and effectiveness. We also offer evaluation using our own created cross-dataset, surveillance-SOD (S-SOD), to check the trained models' validity in terms of their applicability in diverse scenarios. The results indicate that the current models have limited generalization potentials, demanding further research in this direction. Our code and new dataset will be publicly available at https://github.com/tanveer-hussain/EfficientSOD