 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Convex Optimization in Federated Learning via Variance Reduction and Adaptive Learning
Dec 16, 2024



This paper proposes a novel federated algorithm that leverages momentum-based variance reduction with adaptive learning to address non-convex settings across heterogeneous data. We intend to minimize communication and computation overhead, thereby fostering a sustainable federated learning system. We aim to overcome challenges related to gradient variance, which hinders the model's efficiency, and the slow convergence resulting from learning rate adjustments with heterogeneous data. The experimental results on the image classification tasks with heterogeneous data reveal the effectiveness of our suggested algorithms in non-convex settings with an improved communication complexity of $\mathcal{O}(\epsilon^{-1})$ to converge to an $\epsilon$-stationary point - compared to the existing communication complexity $\mathcal{O}(\epsilon^{-2})$ of most prior works. The proposed federated version maintains the trade-off between the convergence rate, number of communication rounds, and test accuracy while mitigating the client drift in heterogeneous settings. The experimental results demonstrate the efficiency of our algorithms in image classification tasks (MNIST, CIFAR-10) with heterogeneous data.
Anomalous Client Detection in Federated Learning
Nov 03, 2024Federated learning (FL), with the growing IoT and edge computing, is seen as a promising solution for applications that are latency- and privacy-aware. However, due to the widespread dispersion of data across many clients, it is challenging to monitor client anomalies caused by malfunctioning devices or unexpected events. The majority of FL solutions now in use concentrate on the classification problem, ignoring situations in which anomaly detection may also necessitate privacy preservation and effectiveness. The system in federated learning is unable to manage the potentially flawed behavior of its clients completely. These behaviors include sharing arbitrary parameter values and causing a delay in convergence since clients are chosen at random without knowing the malfunctioning behavior of the client. Client selection is crucial in terms of the efficiency of the federated learning framework. The challenges such as client drift and handling slow clients with low computational capability are well-studied in FL. However, the detection of anomalous clients either for security or for overall performance in the FL frameworks is hardly studied in the literature. In this paper, we propose an anomaly client detection algorithm to overcome malicious client attacks and client drift in FL frameworks. Instead of random client selection, our proposed method utilizes anomaly client detection to remove clients from the FL framework, thereby enhancing the security and efficiency of the overall system. This proposed method improves the global model convergence in almost 50\% fewer communication rounds compared with widely used random client selection using the MNIST dataset.
An advanced data fabric architecture leveraging homomorphic encryption and federated learning
Feb 15, 2024

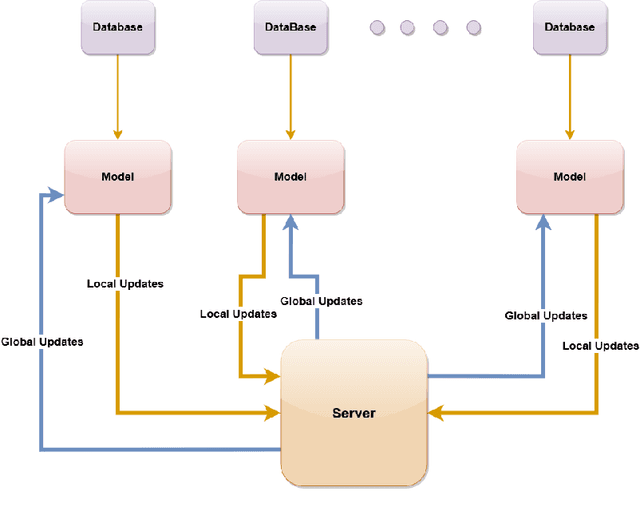

Data fabric is an automated and AI-driven data fusion approach to accomplish data management unification without moving data to a centralized location for solving complex data problems. In a Federated learning architecture, the global model is trained based on the learned parameters of several local models that eliminate the necessity of moving data to a centralized repository for machine learning. This paper introduces a secure approach for medical image analysis using federated learning and partially homomorphic encryption within a distributed data fabric architecture. With this method, multiple parties can collaborate in training a machine-learning model without exchanging raw data but using the learned or fused features. The approach complies with laws and regulations such as HIPAA and GDPR, ensuring the privacy and security of the data. The study demonstrates the method's effectiveness through a case study on pituitary tumor classification, achieving a significant level of accuracy. However, the primary focus of the study is on the development and evaluation of federated learning and partially homomorphic encryption as tools for secure medical image analysis. The results highlight the potential of these techniques to be applied to other privacy-sensitive domains and contribute to the growing body of research on secure and privacy-preserving machine learning.
FallDeF5: A Fall Detection Framework Using 5G-based Deep Gated Recurrent Unit Networks
Jun 29, 2021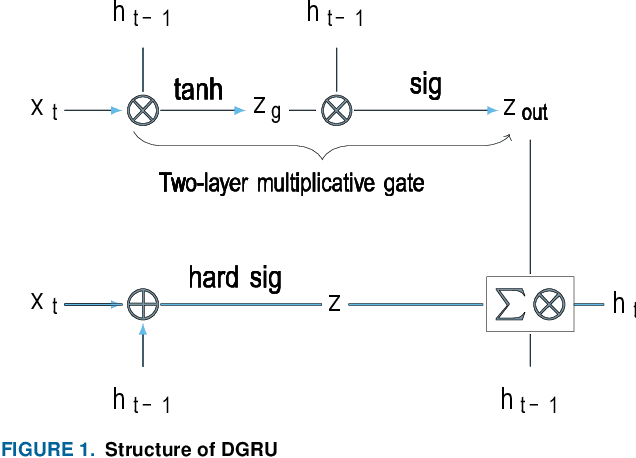
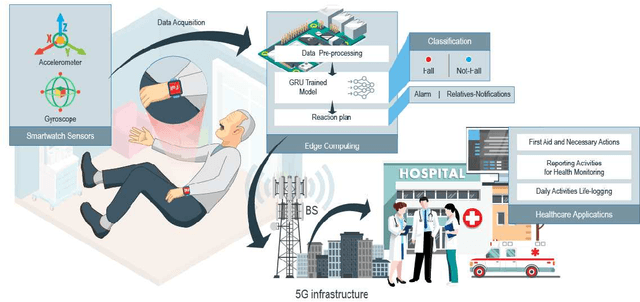
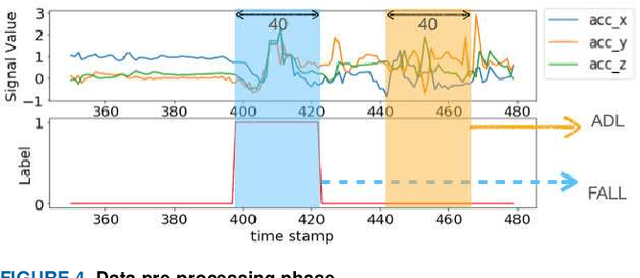
Fall prevalence is high among elderly people, which is challenging due to the severe consequences of falling. This is why rapid assistance is a critical task. Ambient assisted living (AAL) uses recent technologies such as 5G networks and the internet of medical things (IoMT) to address this research area. Edge computing can reduce the cost of cloud communication, including high latency and bandwidth use, by moving conventional healthcare services and applications closer to end-users. Artificial intelligence (AI) techniques such as deep learning (DL) have been used recently for automatic fall detection, as well as supporting healthcare services. However, DL requires a vast amount of data and substantial processing power to improve its performance for the IoMT linked to the traditional edge computing environment. This research proposes an effective fall detection framework based on DL algorithms and mobile edge computing (MEC) within 5G wireless networks, the aim being to empower IoMT-based healthcare applications. We also propose the use of a deep gated recurrent unit (DGRU) neural network to improve the accuracy of existing DL-based fall detection methods. DGRU has the advantage of dealing with time-series IoMT data, and it can reduce the number of parameters and avoid the vanishing gradient problem. The experimental results on two public datasets show that the DGRU model of the proposed framework achieves higher accuracy rates compared to the current related works on the same datasets.
Cloud based Scalable Object Recognition from Video Streams using Orientation Fusion and Convolutional Neural Networks
Jun 19, 2021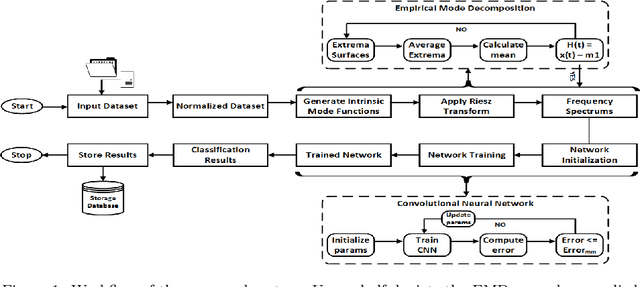
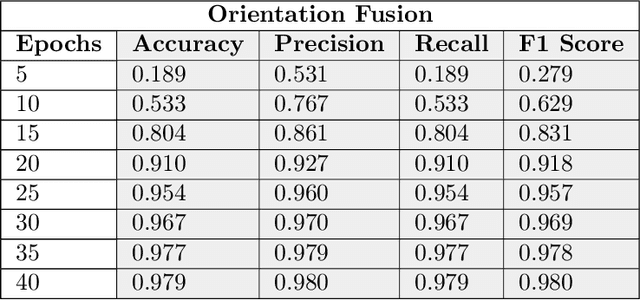
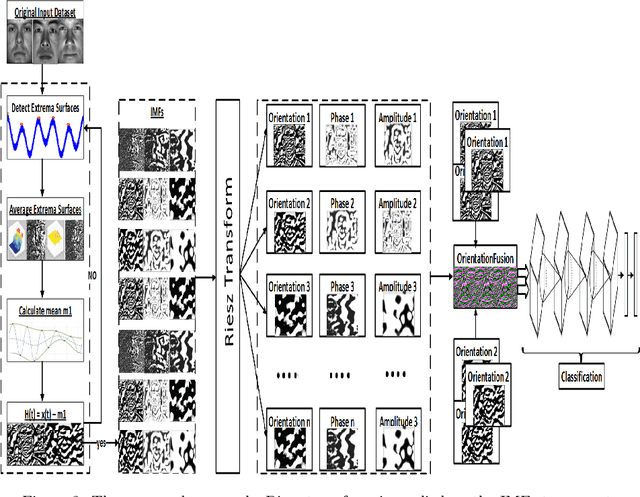

Object recognition from live video streams comes with numerous challenges such as the variation in illumination conditions and poses. Convolutional neural networks (CNNs) have been widely used to perform intelligent visual object recognition. Yet, CNNs still suffer from severe accuracy degradation, particularly on illumination-variant datasets. To address this problem, we propose a new CNN method based on orientation fusion for visual object recognition. The proposed cloud-based video analytics system pioneers the use of bi-dimensional empirical mode decomposition to split a video frame into intrinsic mode functions (IMFs). We further propose these IMFs to endure Reisz transform to produce monogenic object components, which are in turn used for the training of CNNs. Past works have demonstrated how the object orientation component may be used to pursue accuracy levels as high as 93\%. Herein we demonstrate how a feature-fusion strategy of the orientation components leads to further improving visual recognition accuracy to 97\%. We also assess the scalability of our method, looking at both the number and the size of the video streams under scrutiny. We carry out extensive experimentation on the publicly available Yale dataset, including also a self generated video datasets, finding significant improvements (both in accuracy and scale), in comparison to AlexNet, LeNet and SE-ResNeXt, which are the three most commonly used deep learning models for visual object recognition and classification.
Supervised Feature Selection Techniques in Network Intrusion Detection: a Critical Review
Apr 11, 2021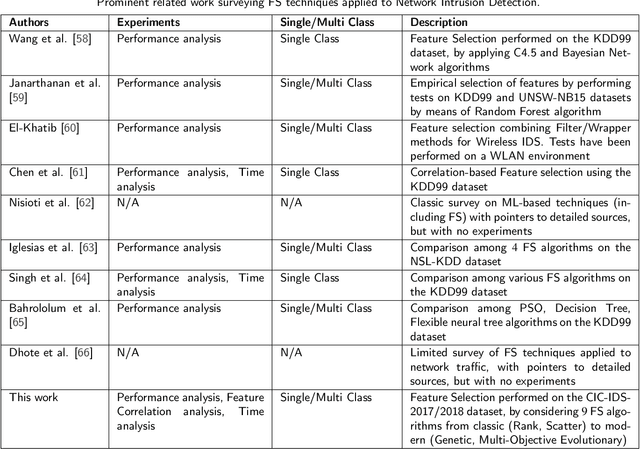
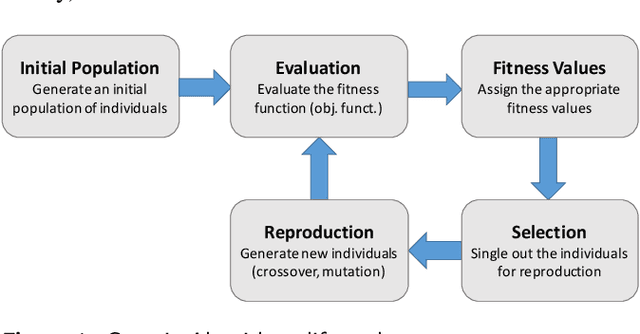
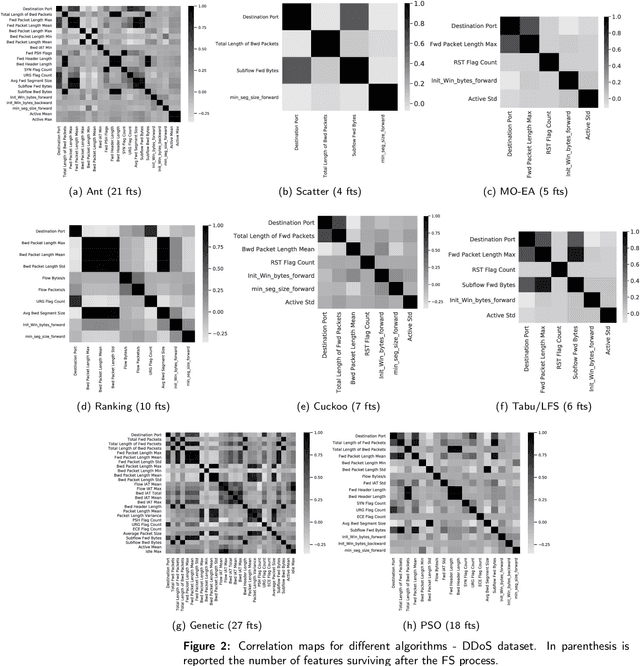
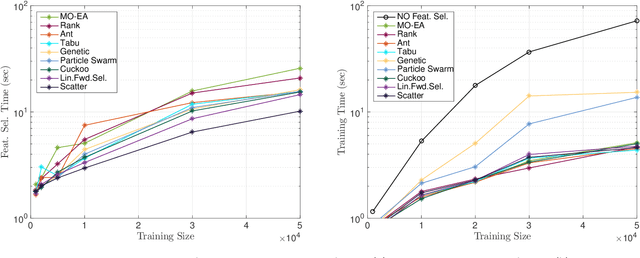
Machine Learning (ML) techniques are becoming an invaluable support for network intrusion detection, especially in revealing anomalous flows, which often hide cyber-threats. Typically, ML algorithms are exploited to classify/recognize data traffic on the basis of statistical features such as inter-arrival times, packets length distribution, mean number of flows, etc. Dealing with the vast diversity and number of features that typically characterize data traffic is a hard problem. This results in the following issues: i) the presence of so many features leads to lengthy training processes (particularly when features are highly correlated), while prediction accuracy does not proportionally improve; ii) some of the features may introduce bias during the classification process, particularly those that have scarce relation with the data traffic to be classified. To this end, by reducing the feature space and retaining only the most significant features, Feature Selection (FS) becomes a crucial pre-processing step in network management and, specifically, for the purposes of network intrusion detection. In this review paper, we complement other surveys in multiple ways: i) evaluating more recent datasets (updated w.r.t. obsolete KDD 99) by means of a designed-from-scratch Python-based procedure; ii) providing a synopsis of most credited FS approaches in the field of intrusion detection, including Multi-Objective Evolutionary techniques; iii) assessing various experimental analyses such as feature correlation, time complexity, and performance. Our comparisons offer useful guidelines to network/security managers who are considering the incorporation of ML concepts into network intrusion detection, where trade-offs between performance and resource consumption are crucial.
An Experimental-based Review of Image Enhancement and Image Restoration Methods for Underwater Imaging
Jul 07, 2019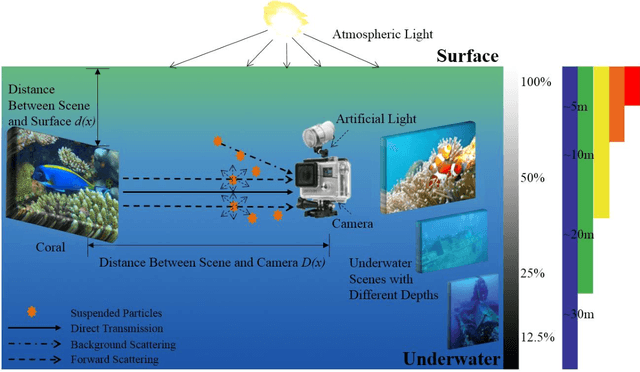

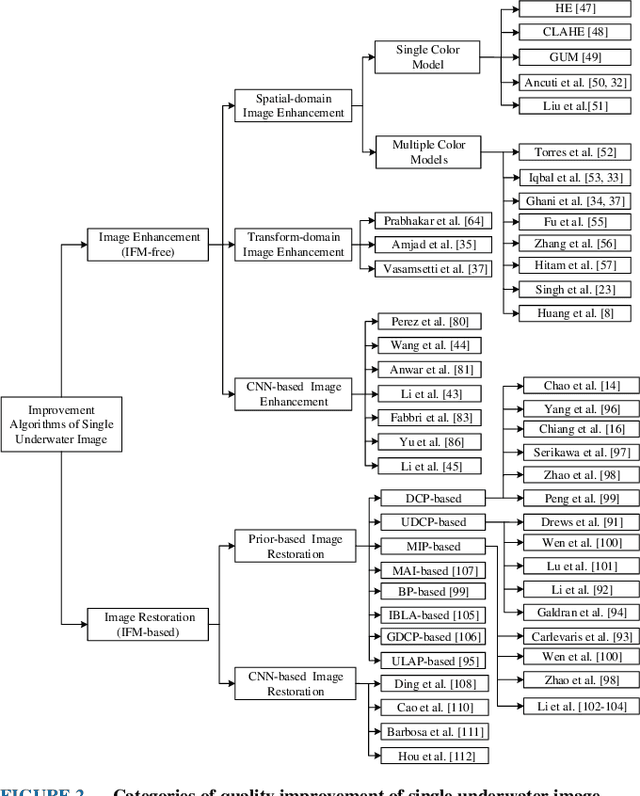
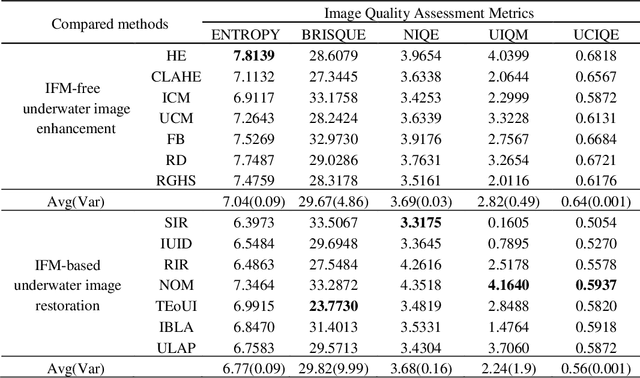
Underwater images play a key role in ocean exploration, but often suffer from severe quality degradation due to light absorption and scattering in water medium. Although major breakthroughs have been made recently in the general area of image enhancement and restoration, the applicability of new methods for improving the quality of underwater images has not specifically been captured. In this paper, we review the image enhancement and restoration methods that tackle typical underwater image impairments, including some extreme degradations and distortions. Firstly, we introduce the key causes of quality reduction in underwater images, in terms of the underwater image formation model (IFM). Then, we review underwater restoration methods, considering both the IFM-free and the IFM-based approaches. Next, we present an experimental-based comparative evaluation of state-of-the-art IFM-free and IFM-based methods, considering also the prior-based parameter estimation algorithms of the IFM-based methods, using both subjective and objective analysis (the used code is freely available at https://github.com/wangyanckxx/Single-Underwater-Image-Enhancement-and-Color-Restoration). Starting from this study, we pinpoint the key shortcomings of existing methods, drawing recommendations for future research in this area. Our review of underwater image enhancement and restoration provides researchers with the necessary background to appreciate challenges and opportunities in this important field.