 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Time Series characterization and forecasting of VoIP traffic in real mobile networks
Jul 13, 2023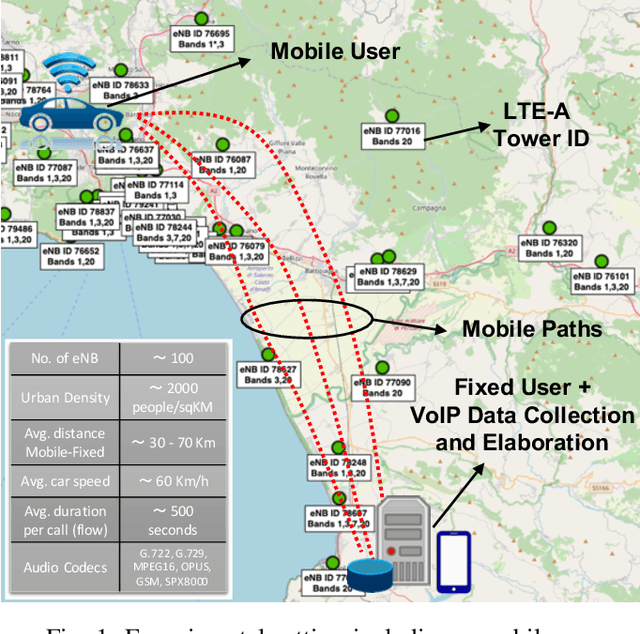
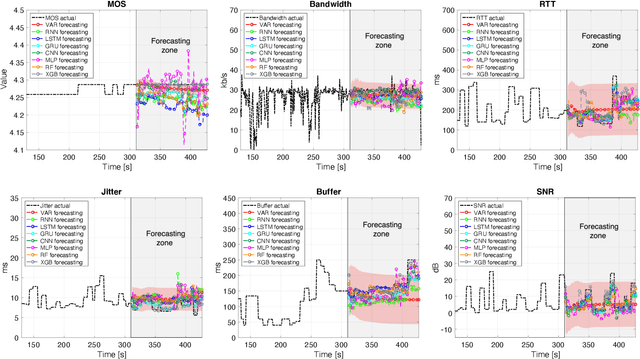
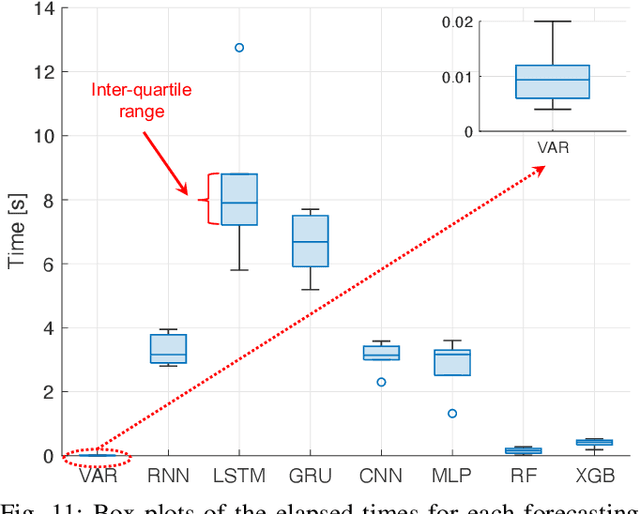
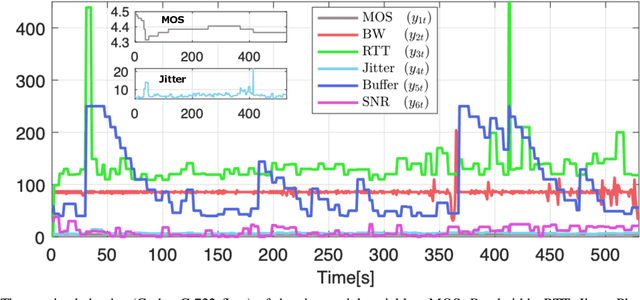
Predicting the behavior of real-time traffic (e.g., VoIP) in mobility scenarios could help the operators to better plan their network infrastructures and to optimize the allocation of resources. Accordingly, in this work the authors propose a forecasting analysis of crucial QoS/QoE descriptors (some of which neglected in the technical literature) of VoIP traffic in a real mobile environment. The problem is formulated in terms of a multivariate time series analysis. Such a formalization allows to discover and model the temporal relationships among various descriptors and to forecast their behaviors for future periods. Techniques such as Vector Autoregressive models and machine learning (deep-based and tree-based) approaches are employed and compared in terms of performance and time complexity, by reframing the multivariate time series problem into a supervised learning one. Moreover, a series of auxiliary analyses (stationarity, orthogonal impulse responses, etc.) are performed to discover the analytical structure of the time series and to provide deep insights about their relationships. The whole theoretical analysis has an experimental counterpart since a set of trials across a real-world LTE-Advanced environment has been performed to collect, post-process and analyze about 600,000 voice packets, organized per flow and differentiated per codec.
Supervised Feature Selection Techniques in Network Intrusion Detection: a Critical Review
Apr 11, 2021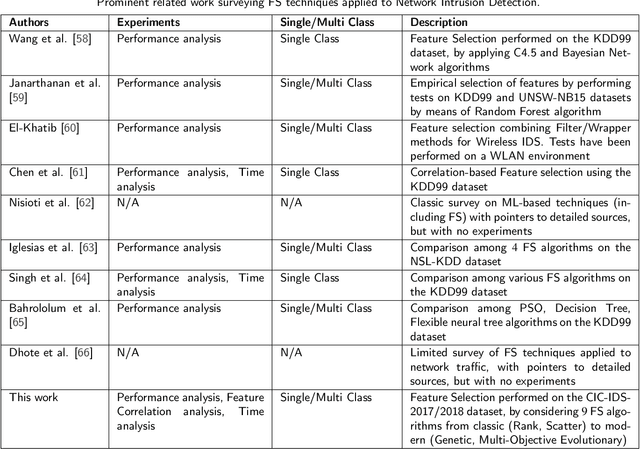
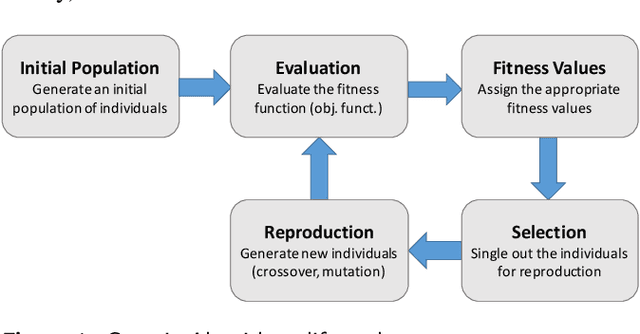
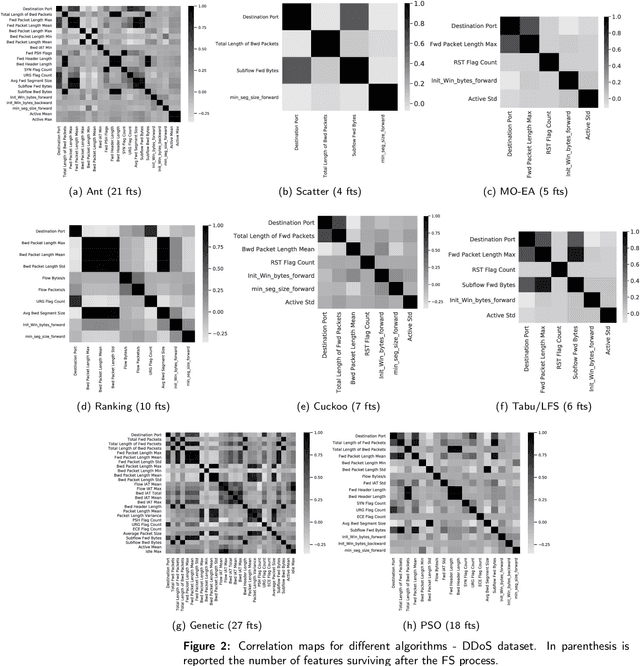
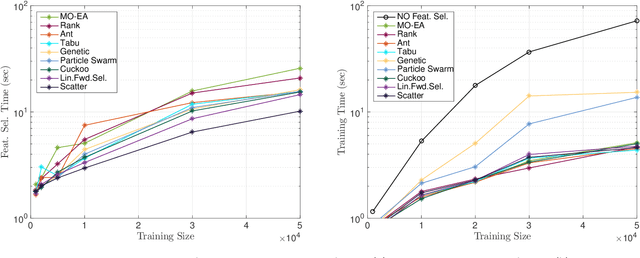
Machine Learning (ML) techniques are becoming an invaluable support for network intrusion detection, especially in revealing anomalous flows, which often hide cyber-threats. Typically, ML algorithms are exploited to classify/recognize data traffic on the basis of statistical features such as inter-arrival times, packets length distribution, mean number of flows, etc. Dealing with the vast diversity and number of features that typically characterize data traffic is a hard problem. This results in the following issues: i) the presence of so many features leads to lengthy training processes (particularly when features are highly correlated), while prediction accuracy does not proportionally improve; ii) some of the features may introduce bias during the classification process, particularly those that have scarce relation with the data traffic to be classified. To this end, by reducing the feature space and retaining only the most significant features, Feature Selection (FS) becomes a crucial pre-processing step in network management and, specifically, for the purposes of network intrusion detection. In this review paper, we complement other surveys in multiple ways: i) evaluating more recent datasets (updated w.r.t. obsolete KDD 99) by means of a designed-from-scratch Python-based procedure; ii) providing a synopsis of most credited FS approaches in the field of intrusion detection, including Multi-Objective Evolutionary techniques; iii) assessing various experimental analyses such as feature correlation, time complexity, and performance. Our comparisons offer useful guidelines to network/security managers who are considering the incorporation of ML concepts into network intrusion detection, where trade-offs between performance and resource consumption are crucial.
Experimental Review of Neural-based approaches for Network Intrusion Management
Sep 18, 2020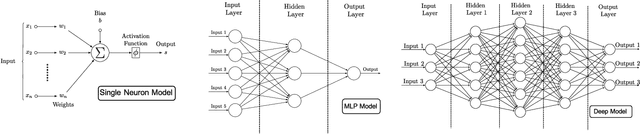
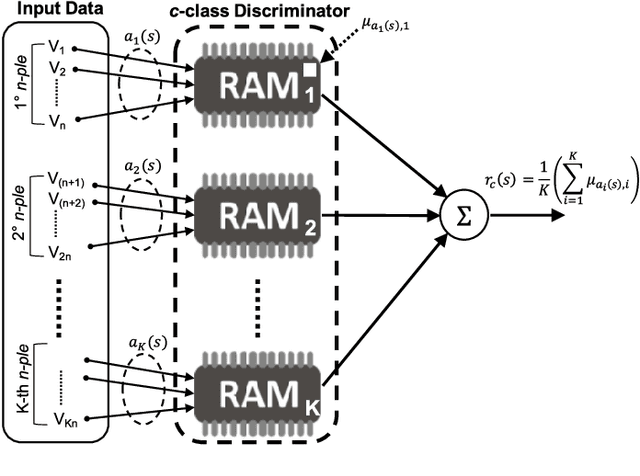
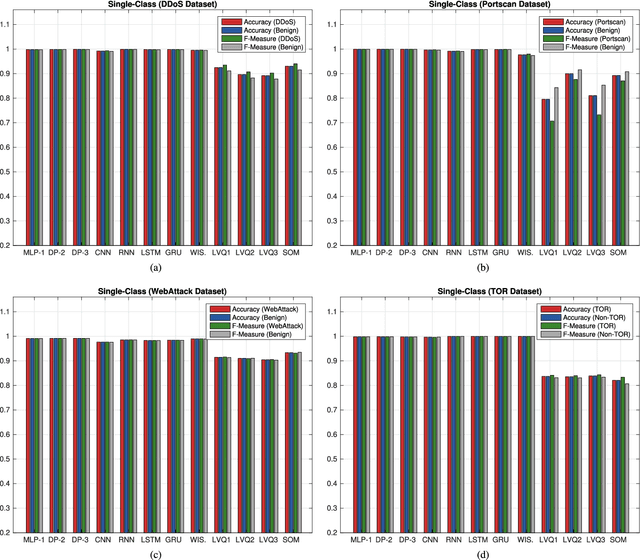
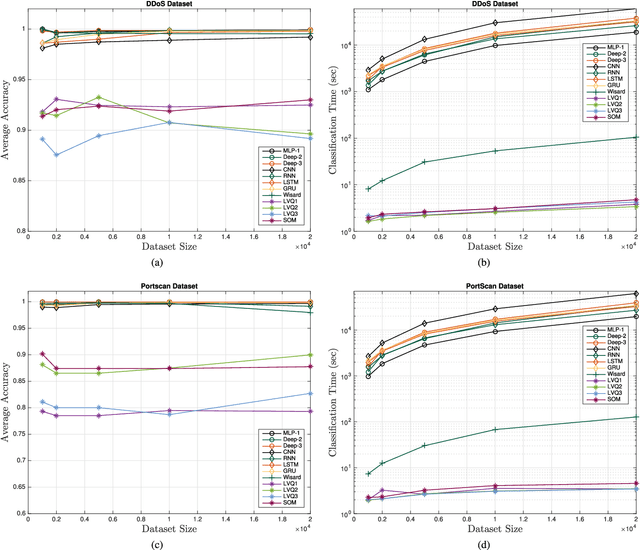
The use of Machine Learning (ML) techniques in Intrusion Detection Systems (IDS) has taken a prominent role in the network security management field, due to the substantial number of sophisticated attacks that often pass undetected through classic IDSs. These are typically aimed at recognising attacks based on a specific signature, or at detecting anomalous events. However, deterministic, rule-based methods often fail to differentiate particular (rarer) network conditions (as in peak traffic during specific network situations) from actual cyber attacks. In this paper we provide an experimental-based review of neural-based methods applied to intrusion detection issues. Specifically, we i) offer a complete view of the most prominent neural-based techniques relevant to intrusion detection, including deep-based approaches or weightless neural networks, which feature surprising outcomes; ii) evaluate novel datasets (updated w.r.t. the obsolete KDD99 set) through a designed-from-scratch Python-based routine; iii) perform experimental analyses including time complexity and performance (accuracy and F-measure), considering both single-class and multi-class problems, and identifying trade-offs between resource consumption and performance. Our evaluation quantifies the value of neural networks, particularly when state-of-the-art datasets are used to train the models. This leads to interesting guidelines for security managers and computer network practitioners who are looking at the incorporation of neural-based ML into IDS.