 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
Feb 13, 2026We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.
MMARD: Improving the Min-Max Optimization Process in Adversarial Robustness Distillation
Mar 09, 2025Adversarial Robustness Distillation (ARD) is a promising task to boost the robustness of small-capacity models with the guidance of the pre-trained robust teacher. The ARD can be summarized as a min-max optimization process, i.e., synthesizing adversarial examples (inner) & training the student (outer). Although competitive robustness performance, existing ARD methods still have issues. In the inner process, the synthetic training examples are far from the teacher's decision boundary leading to important robust information missing. In the outer process, the student model is decoupled from learning natural and robust scenarios, leading to the robustness saturation, i.e., student performance is highly susceptible to customized teacher selection. To tackle these issues, this paper proposes a general Min-Max optimization Adversarial Robustness Distillation (MMARD) method. For the inner process, we introduce the teacher's robust predictions, which drive the training examples closer to the teacher's decision boundary to explore more robust knowledge. For the outer process, we propose a structured information modeling method based on triangular relationships to measure the mutual information of the model in natural and robust scenarios and enhance the model's ability to understand multi-scenario mapping relationships. Experiments show our MMARD achieves state-of-the-art performance on multiple benchmarks. Besides, MMARD is plug-and-play and convenient to combine with existing methods.
Self-Cooperation Knowledge Distillation for Novel Class Discovery
Jul 02, 2024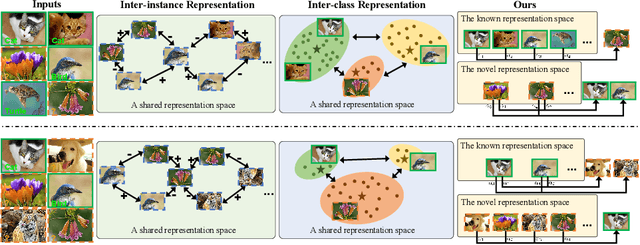

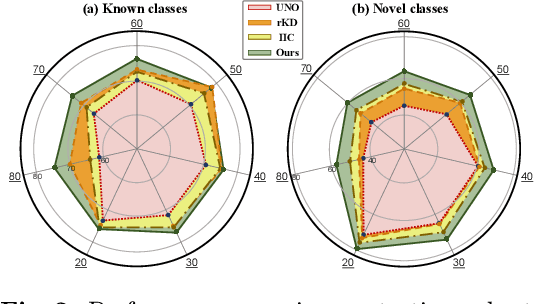
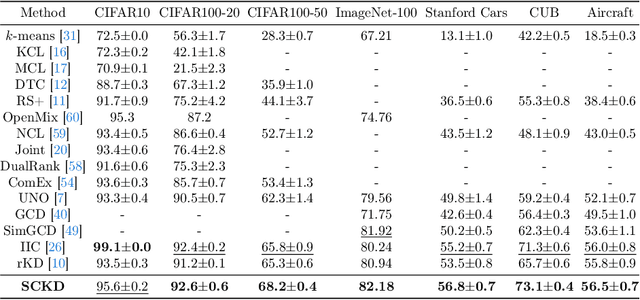
Novel Class Discovery (NCD) aims to discover unknown and novel classes in an unlabeled set by leveraging knowledge already learned about known classes. Existing works focus on instance-level or class-level knowledge representation and build a shared representation space to achieve performance improvements. However, a long-neglected issue is the potential imbalanced number of samples from known and novel classes, pushing the model towards dominant classes. Therefore, these methods suffer from a challenging trade-off between reviewing known classes and discovering novel classes. Based on this observation, we propose a Self-Cooperation Knowledge Distillation (SCKD) method to utilize each training sample (whether known or novel, labeled or unlabeled) for both review and discovery. Specifically, the model's feature representations of known and novel classes are used to construct two disjoint representation spaces. Through spatial mutual information, we design a self-cooperation learning to encourage model learning from the two feature representation spaces from itself. Extensive experiments on six datasets demonstrate that our method can achieve significant performance improvements, achieving state-of-the-art performance.
De-confounded Data-free Knowledge Distillation for Handling Distribution Shifts
Mar 28, 2024



Data-Free Knowledge Distillation (DFKD) is a promising task to train high-performance small models to enhance actual deployment without relying on the original training data. Existing methods commonly avoid relying on private data by utilizing synthetic or sampled data. However, a long-overlooked issue is that the severe distribution shifts between their substitution and original data, which manifests as huge differences in the quality of images and class proportions. The harmful shifts are essentially the confounder that significantly causes performance bottlenecks. To tackle the issue, this paper proposes a novel perspective with causal inference to disentangle the student models from the impact of such shifts. By designing a customized causal graph, we first reveal the causalities among the variables in the DFKD task. Subsequently, we propose a Knowledge Distillation Causal Intervention (KDCI) framework based on the backdoor adjustment to de-confound the confounder. KDCI can be flexibly combined with most existing state-of-the-art baselines. Experiments in combination with six representative DFKD methods demonstrate the effectiveness of our KDCI, which can obviously help existing methods under almost all settings, \textit{e.g.}, improving the baseline by up to 15.54\% accuracy on the CIFAR-100 dataset.
Hierarchical Visual Policy Learning for Long-Horizon Robot Manipulation in Densely Cluttered Scenes
Dec 05, 2023In this work, we focus on addressing the long-horizon manipulation tasks in densely cluttered scenes. Such tasks require policies to effectively manage severe occlusions among objects and continually produce actions based on visual observations. We propose a vision-based Hierarchical policy for Cluttered-scene Long-horizon Manipulation (HCLM). It employs a high-level policy and three options to select and instantiate three parameterized action primitives: push, pick, and place. We first train the pick and place options by behavior cloning (BC). Subsequently, we use hierarchical reinforcement learning (HRL) to train the high-level policy and push option. During HRL, we propose a Spatially Extended Q-update (SEQ) to augment the updates for the push option and a Two-Stage Update Scheme (TSUS) to alleviate the non-stationary transition problem in updating the high-level policy. We demonstrate that HCLM significantly outperforms baseline methods in terms of success rate and efficiency in diverse tasks. We also highlight our method's ability to generalize to more cluttered environments with more additional blocks.
On the Importance of Spatial Relations for Few-shot Action Recognition
Aug 14, 2023Deep learning has achieved great success in video recognition, yet still struggles to recognize novel actions when faced with only a few examples. To tackle this challenge, few-shot action recognition methods have been proposed to transfer knowledge from a source dataset to a novel target dataset with only one or a few labeled videos. However, existing methods mainly focus on modeling the temporal relations between the query and support videos while ignoring the spatial relations. In this paper, we find that the spatial misalignment between objects also occurs in videos, notably more common than the temporal inconsistency. We are thus motivated to investigate the importance of spatial relations and propose a more accurate few-shot action recognition method that leverages both spatial and temporal information. Particularly, a novel Spatial Alignment Cross Transformer (SA-CT) which learns to re-adjust the spatial relations and incorporates the temporal information is contributed. Experiments reveal that, even without using any temporal information, the performance of SA-CT is comparable to temporal based methods on 3/4 benchmarks. To further incorporate the temporal information, we propose a simple yet effective Temporal Mixer module. The Temporal Mixer enhances the video representation and improves the performance of the full SA-CT model, achieving very competitive results. In this work, we also exploit large-scale pretrained models for few-shot action recognition, providing useful insights for this research direction.
Sampling to Distill: Knowledge Transfer from Open-World Data
Jul 31, 2023Data-Free Knowledge Distillation (DFKD) is a novel task that aims to train high-performance student models using only the teacher network without original training data. Despite encouraging results, existing DFKD methods rely heavily on generation modules with high computational costs. Meanwhile, they ignore the fact that the generated and original data exist domain shifts due to the lack of supervision information. Moreover, knowledge is transferred through each example, ignoring the implicit relationship among multiple examples. To this end, we propose a novel Open-world Data Sampling Distillation (ODSD) method without a redundant generation process. First, we try to sample open-world data close to the original data's distribution by an adaptive sampling module. Then, we introduce a low-noise representation to alleviate the domain shifts and build a structured relationship of multiple data examples to exploit data knowledge. Extensive experiments on CIFAR-10, CIFAR-100, NYUv2, and ImageNet show that our ODSD method achieves state-of-the-art performance. Especially, we improve 1.50\%-9.59\% accuracy on the ImageNet dataset compared with the existing results.
Model Robustness Meets Data Privacy: Adversarial Robustness Distillation without Original Data
Mar 21, 2023
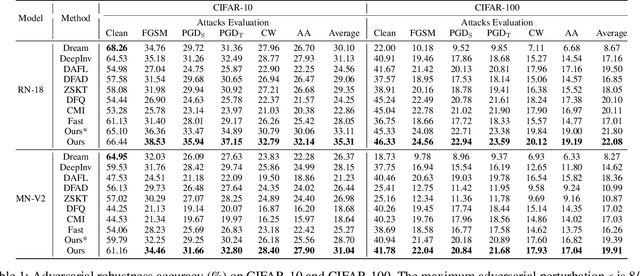


Large-scale deep learning models have achieved great performance based on large-scale datasets. Moreover, the existing Adversarial Training (AT) can further improve the robustness of these large models. However, these large models are difficult to deploy to mobile devices, and the effect of AT on small models is very limited. In addition, the data privacy issue (e.g., face data and diagnosis report) may lead to the original data being unavailable, which relies on data-free knowledge distillation technology for training. To tackle these issues, we propose a challenging novel task called Data-Free Adversarial Robustness Distillation (DFARD), which tries to train small, easily deployable, robust models without relying on the original data. We find the combination of existing techniques resulted in degraded model performance due to fixed training objectives and scarce information content. First, an interactive strategy is designed for more efficient knowledge transfer to find more suitable training objectives at each epoch. Then, we explore an adaptive balance method to suppress information loss and obtain more data information than previous methods. Experiments show that our method improves baseline performance on the novel task.
Adversarial Contrastive Distillation with Adaptive Denoising
Feb 23, 2023


Adversarial Robustness Distillation (ARD) is a novel method to boost the robustness of small models. Unlike general adversarial training, its robust knowledge transfer can be less easily restricted by the model capacity. However, the teacher model that provides the robustness of knowledge does not always make correct predictions, interfering with the student's robust performances. Besides, in the previous ARD methods, the robustness comes entirely from one-to-one imitation, ignoring the relationship between examples. To this end, we propose a novel structured ARD method called Contrastive Relationship DeNoise Distillation (CRDND). We design an adaptive compensation module to model the instability of the teacher. Moreover, we utilize the contrastive relationship to explore implicit robustness knowledge among multiple examples. Experimental results on multiple attack benchmarks show CRDND can transfer robust knowledge efficiently and achieves state-of-the-art performances.
Explicit and Implicit Knowledge Distillation via Unlabeled Data
Feb 23, 2023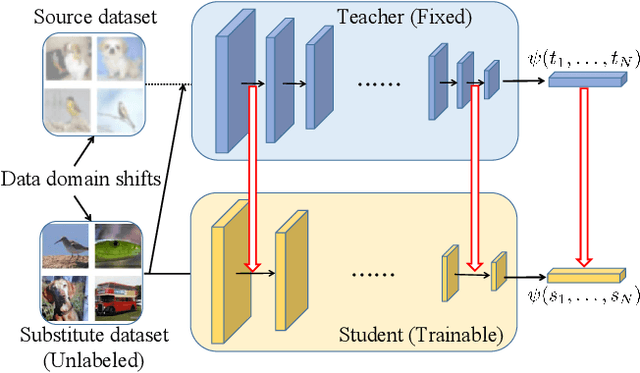
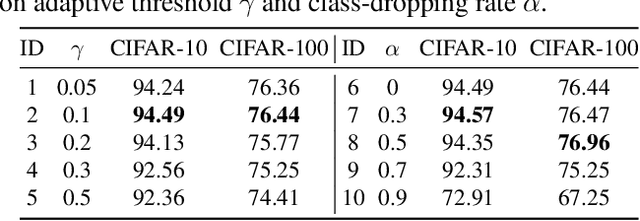
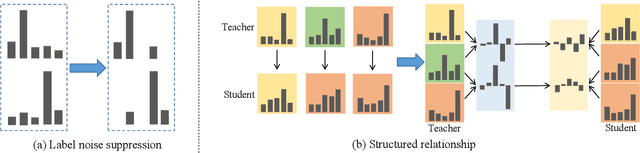
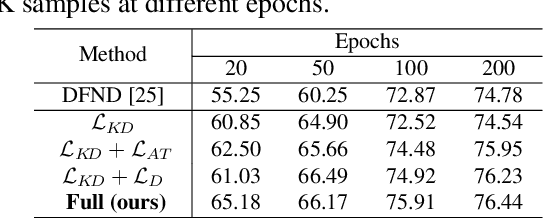
Data-free knowledge distillation is a challenging model lightweight task for scenarios in which the original dataset is not available. Previous methods require a lot of extra computational costs to update one or more generators and their naive imitate-learning lead to lower distillation efficiency. Based on these observations, we first propose an efficient unlabeled sample selection method to replace high computational generators and focus on improving the training efficiency of the selected samples. Then, a class-dropping mechanism is designed to suppress the label noise caused by the data domain shifts. Finally, we propose a distillation method that incorporates explicit features and implicit structured relations to improve the effect of distillation. Experimental results show that our method can quickly converge and obtain higher accuracy than other state-of-the-art methods.