 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep g-Pricing for CSI 300 Index Options with Volatility Trajectories and Market Sentiment
Jan 15, 2026Option pricing in real markets faces fundamental challenges. The Black--Scholes--Merton (BSM) model assumes constant volatility and uses a linear generator $g(t,x,y,z)=-ry$, while lacking explicit behavioral factors, resulting in systematic departures from observed dynamics. This paper extends the BSM model by learning a nonlinear generator within a deep Forward--Backward Stochastic Differential Equation (FBSDE) framework. We propose a dual-network architecture where the value network $u_θ$ learns option prices and the generator network $g_φ$ characterizes the pricing mechanism, with the hedging strategy $Z_t=σ_t X_t \nabla_x u_θ$ obtained via automatic differentiation. The framework adopts forward recursion from a learnable initial condition $Y_0=u_θ(0,\cdot)$, naturally accommodating volatility trajectory and sentiment features. Empirical results on CSI 300 index options show that our method reduces Mean Absolute Error (MAE) by 32.2\% and Mean Absolute Percentage Error (MAPE) by 35.3\% compared with BSM. Interpretability analysis indicates that architectural improvements are effective across all option types, while the information advantage is asymmetric between calls and puts. Specifically, call option improvements are primarily driven by sentiment features, whereas put options show more balanced contributions from volatility trajectory and sentiment features. This finding aligns with economic intuition regarding option pricing mechanisms.
Haibu Mathematical-Medical Intelligent Agent:Enhancing Large Language Model Reliability in Medical Tasks via Verifiable Reasoning Chains
Oct 09, 2025Large Language Models (LLMs) show promise in medicine but are prone to factual and logical errors, which is unacceptable in this high-stakes field. To address this, we introduce the "Haibu Mathematical-Medical Intelligent Agent" (MMIA), an LLM-driven architecture that ensures reliability through a formally verifiable reasoning process. MMIA recursively breaks down complex medical tasks into atomic, evidence-based steps. This entire reasoning chain is then automatically audited for logical coherence and evidence traceability, similar to theorem proving. A key innovation is MMIA's "bootstrapping" mode, which stores validated reasoning chains as "theorems." Subsequent tasks can then be efficiently solved using Retrieval-Augmented Generation (RAG), shifting from costly first-principles reasoning to a low-cost verification model. We validated MMIA across four healthcare administration domains, including DRG/DIP audits and medical insurance adjudication, using expert-validated benchmarks. Results showed MMIA achieved an error detection rate exceeding 98% with a false positive rate below 1%, significantly outperforming baseline LLMs. Furthermore, the RAG matching mode is projected to reduce average processing costs by approximately 85% as the knowledge base matures. In conclusion, MMIA's verifiable reasoning framework is a significant step toward creating trustworthy, transparent, and cost-effective AI systems, making LLM technology viable for critical applications in medicine.
SENTRA: Selected-Next-Token Transformer for LLM Text Detection
Sep 15, 2025LLMs are becoming increasingly capable and widespread. Consequently, the potential and reality of their misuse is also growing. In this work, we address the problem of detecting LLM-generated text that is not explicitly declared as such. We present a novel, general-purpose, and supervised LLM text detector, SElected-Next-Token tRAnsformer (SENTRA). SENTRA is a Transformer-based encoder leveraging selected-next-token-probability sequences and utilizing contrastive pre-training on large amounts of unlabeled data. Our experiments on three popular public datasets across 24 domains of text demonstrate SENTRA is a general-purpose classifier that significantly outperforms popular baselines in the out-of-domain setting.
HAIBU-ReMUD: Reasoning Multimodal Ultrasound Dataset and Model Bridging to General Specific Domains
Jun 09, 2025Multimodal large language models (MLLMs) have shown great potential in general domains but perform poorly in some specific domains due to a lack of domain-specific data, such as image-text data or vedio-text data. In some specific domains, there is abundant graphic and textual data scattered around, but lacks standardized arrangement. In the field of medical ultrasound, there are ultrasonic diagnostic books, ultrasonic clinical guidelines, ultrasonic diagnostic reports, and so on. However, these ultrasonic materials are often saved in the forms of PDF, images, etc., and cannot be directly used for the training of MLLMs. This paper proposes a novel image-text reasoning supervised fine-tuning data generation pipeline to create specific domain quadruplets (image, question, thinking trace, and answer) from domain-specific materials. A medical ultrasound domain dataset ReMUD is established, containing over 45,000 reasoning and non-reasoning supervised fine-tuning Question Answering (QA) and Visual Question Answering (VQA) data. The ReMUD-7B model, fine-tuned on Qwen2.5-VL-7B-Instruct, outperforms general-domain MLLMs in medical ultrasound field. To facilitate research, the ReMUD dataset, data generation codebase, and ReMUD-7B parameters will be released at https://github.com/ShiDaizi/ReMUD, addressing the data shortage issue in specific domain MLLMs.
On the Importance of Spatial Relations for Few-shot Action Recognition
Aug 14, 2023Deep learning has achieved great success in video recognition, yet still struggles to recognize novel actions when faced with only a few examples. To tackle this challenge, few-shot action recognition methods have been proposed to transfer knowledge from a source dataset to a novel target dataset with only one or a few labeled videos. However, existing methods mainly focus on modeling the temporal relations between the query and support videos while ignoring the spatial relations. In this paper, we find that the spatial misalignment between objects also occurs in videos, notably more common than the temporal inconsistency. We are thus motivated to investigate the importance of spatial relations and propose a more accurate few-shot action recognition method that leverages both spatial and temporal information. Particularly, a novel Spatial Alignment Cross Transformer (SA-CT) which learns to re-adjust the spatial relations and incorporates the temporal information is contributed. Experiments reveal that, even without using any temporal information, the performance of SA-CT is comparable to temporal based methods on 3/4 benchmarks. To further incorporate the temporal information, we propose a simple yet effective Temporal Mixer module. The Temporal Mixer enhances the video representation and improves the performance of the full SA-CT model, achieving very competitive results. In this work, we also exploit large-scale pretrained models for few-shot action recognition, providing useful insights for this research direction.
A real-time spatiotemporal AI model analyzes skill in open surgical videos
Dec 14, 2021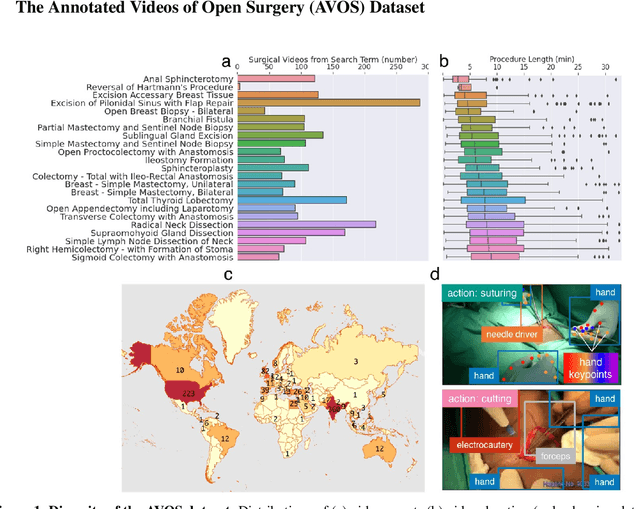
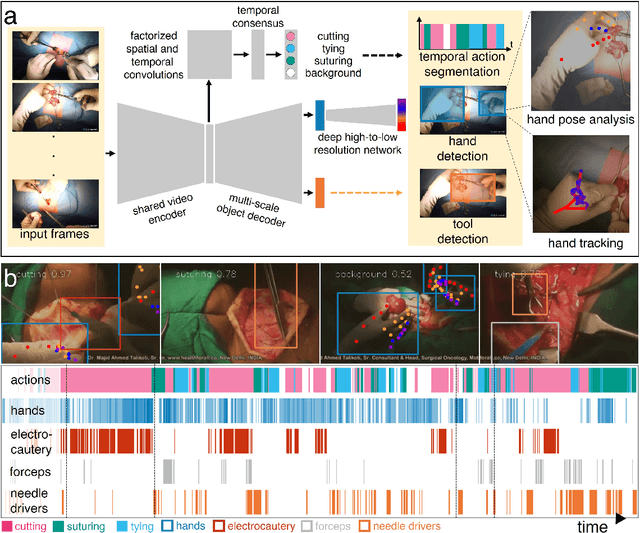
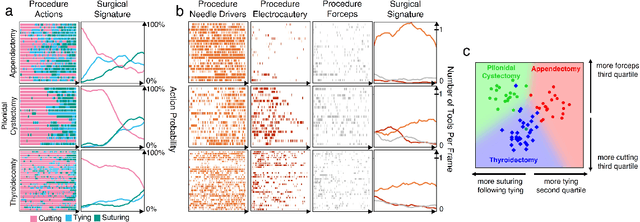
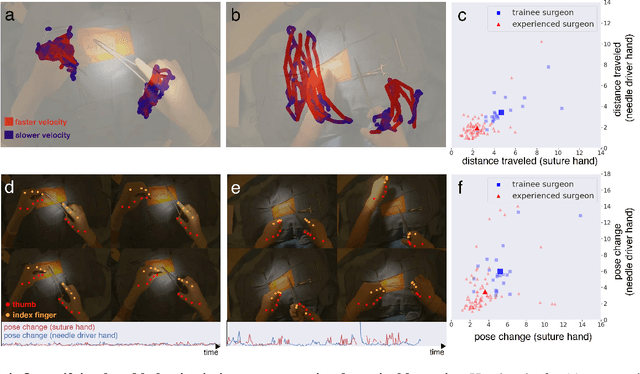
Open procedures represent the dominant form of surgery worldwide. Artificial intelligence (AI) has the potential to optimize surgical practice and improve patient outcomes, but efforts have focused primarily on minimally invasive techniques. Our work overcomes existing data limitations for training AI models by curating, from YouTube, the largest dataset of open surgical videos to date: 1997 videos from 23 surgical procedures uploaded from 50 countries. Using this dataset, we developed a multi-task AI model capable of real-time understanding of surgical behaviors, hands, and tools - the building blocks of procedural flow and surgeon skill. We show that our model generalizes across diverse surgery types and environments. Illustrating this generalizability, we directly applied our YouTube-trained model to analyze open surgeries prospectively collected at an academic medical center and identified kinematic descriptors of surgical skill related to efficiency of hand motion. Our Annotated Videos of Open Surgery (AVOS) dataset and trained model will be made available for further development of surgical AI.
DFineNet: Ego-Motion Estimation and Depth Refinement from Sparse, Noisy Depth Input with RGB Guidance
Apr 10, 2019

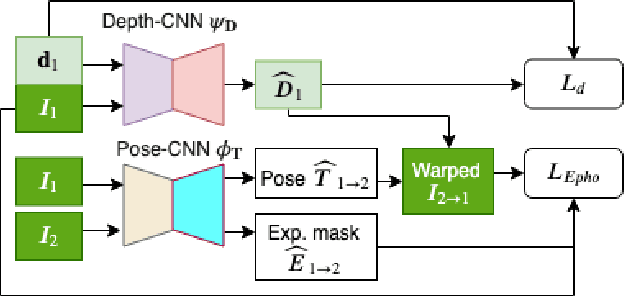

Depth estimation is an important capability for autonomous vehicles to understand and reconstruct 3D environments as well as avoid obstacles during the execution. Accurate depth sensors such as LiDARs are often heavy, expensive and can only provide sparse depth while lighter depth sensors such as stereo cameras are noiser in comparison. We propose an end-to-end learning algorithm that is capable of using sparse, noisy input depth for refinement and depth completion. Our model also produces the camera pose as a byproduct, making it a great solution for autonomous systems. We evaluate our approach on both indoor and outdoor datasets. Empirical results show that our method performs well on the KITTI~\cite{kitti_geiger2012we} dataset when compared to other competing methods, while having superior performance in dealing with sparse, noisy input depth on the TUM~\cite{sturm12iros} dataset.
Multiview Supervision By Registration
Nov 27, 2018



This paper presents a semi-supervised learning framework to train a keypoint pose detector using multiview image streams given the limited number of labeled data (typically <4%). We leverage the complementary relationship between multiview geometry and visual tracking to provide three types of supervisionary signals for the unlabeled data: (1) pose detection in one view can be used to supervise that of the other view as they must satisfy the epipolar constraint; (2) pose detection must be temporally coherent in accordance with its optical flow; (3) the occluded keypoint from one view must be consistently invisible from the near views. We formulate the theory of multiview supervision by registration and design a new end-to-end neural network that integrates these supervisionary signals in a differentiable fashion to incorporate the large unlabeled data in pose detector training. The key innovation of the network is the ability to reason about the visibility/occlusion, which is indicative of the degenerate case of detection and tracking. Our resulting pose detector shows considerable outperformance comparing the state-of-the-art pose detectors in terms of accuracy (keypoint detection) and precision (3D reconstruction). We validate our approach with challenging realworld data including the pose detection of non-human species such as monkeys and dogs.