 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent VQA: Exploring Multi-Agent Foundation Models in Zero-Shot Visual Question Answering
Mar 21, 2024



This work explores the zero-shot capabilities of foundation models in Visual Question Answering (VQA) tasks. We propose an adaptive multi-agent system, named Multi-Agent VQA, to overcome the limitations of foundation models in object detection and counting by using specialized agents as tools. Unlike existing approaches, our study focuses on the system's performance without fine-tuning it on specific VQA datasets, making it more practical and robust in the open world. We present preliminary experimental results under zero-shot scenarios and highlight some failure cases, offering new directions for future research.
Any Way You Look At It: Semantic Crossview Localization and Mapping with LiDAR
Mar 16, 2022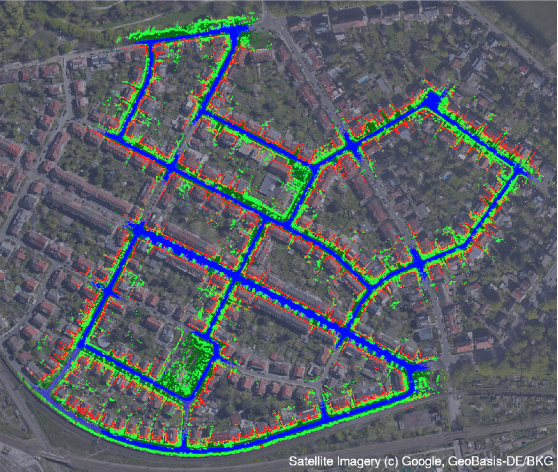
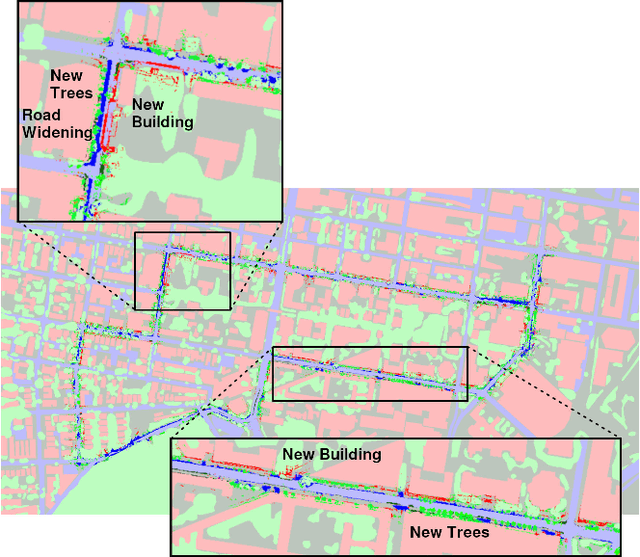
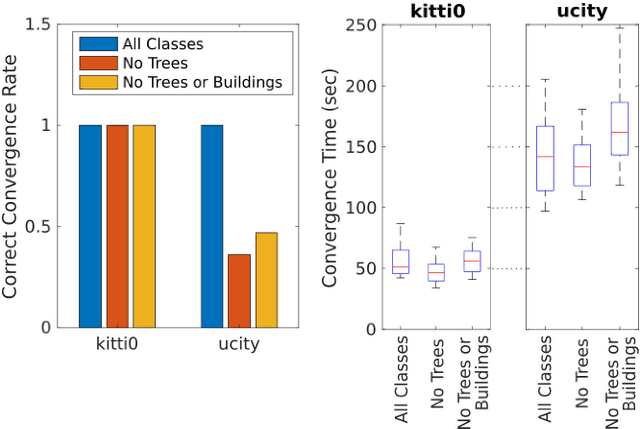
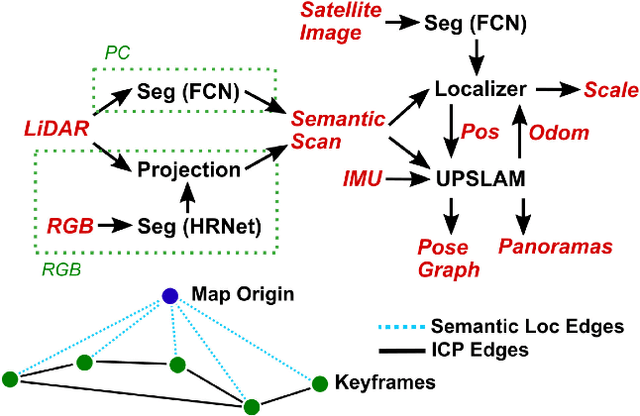
Currently, GPS is by far the most popular global localization method. However, it is not always reliable or accurate in all environments. SLAM methods enable local state estimation but provide no means of registering the local map to a global one, which can be important for inter-robot collaboration or human interaction. In this work, we present a real-time method for utilizing semantics to globally localize a robot using only egocentric 3D semantically labelled LiDAR and IMU as well as top-down RGB images obtained from satellites or aerial robots. Additionally, as it runs, our method builds a globally registered, semantic map of the environment. We validate our method on KITTI as well as our own challenging datasets, and show better than 10 meter accuracy, a high degree of robustness, and the ability to estimate the scale of a top-down map on the fly if it is initially unknown.
* Published in the IEEE Robotics and Automation Letters and presented at the IEEE 2021 International Conference on Robotics and Automation. See https://www.youtube.com/watch?v=_qwAoYK9iGU for accompanying video
DSOL: A Fast Direct Sparse Odometry Scheme
Mar 15, 2022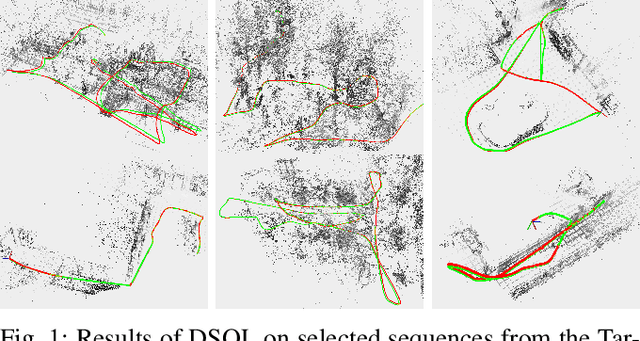


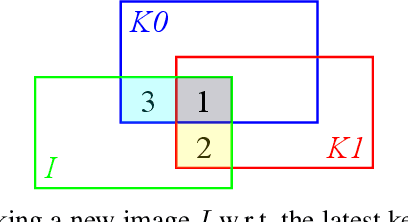
In this paper, we describe Direct Sparse Odometry Lite (DSOL), an improved version of Direct Sparse Odometry (DSO). We propose several algorithmic and implementation enhancements which speed up computation by a significant factor (on average 5x) even on resource constrained platforms. The increase in speed allows us to process images at higher frame rates, which in turn provides better results on rapid motions. Our open-source implementation is available at https://github.com/versatran01/dsol.
LLOL: Low-Latency Odometry for Spinning Lidars
Oct 04, 2021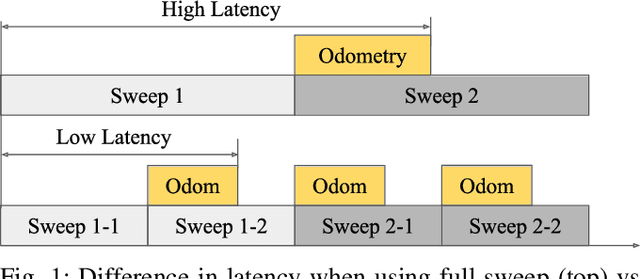



In this paper, we present a low-latency odometry system designed for spinning lidars. Many existing lidar odometry methods wait for an entire sweep from the lidar before processing the data. This introduces a large delay between the first laser firing and its pose estimate. To reduce this latency, we treat the spinning lidar as a streaming sensor and process packets as they arrive. This effectively distributes expensive operations across time, resulting in a very fast and lightweight system with much higher throughput and lower latency. Our open-source implementation is available at \url{https://github.com/versatran01/llol}.
Mine Tunnel Exploration using Multiple Quadrupedal Robots
Sep 20, 2019
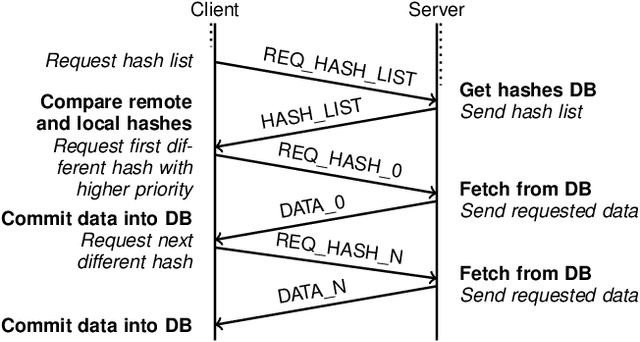
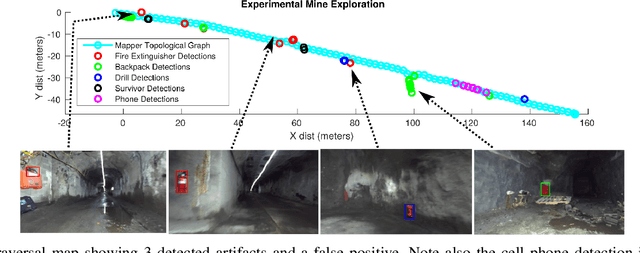
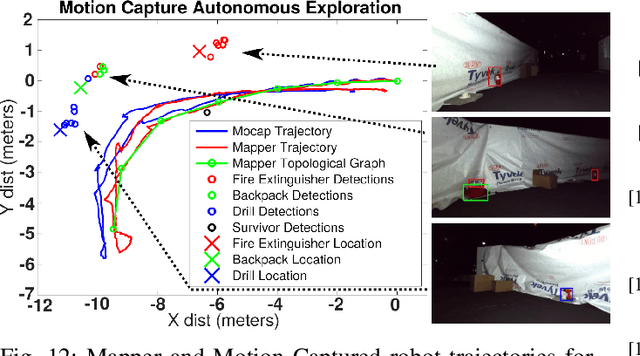
Robotic exploration of underground environments is a particularly challenging problem due to communication, endurance, and traversability constraints which necessitate high degrees of autonomy and agility. These challenges are further enhanced by the need to minimize human intervention for practical applications. While legged robots have the ability to traverse extremely challenging terrain, they also engender further inherent challenges for planning, estimation, and control. In this work, we describe a fully autonomous system for multi-robot mine exploration and mapping using legged quadrupeds, as well as a distributed database mesh networking system for reporting data. In addition, we show results from the DARPA Subterranean Challenge (SubT) Tunnel Circuit demonstrating localization of artifacts after traversals of hundreds of meters. To our knowledge, these experiments represent the first fully autonomous exploration of an unknown GNSS-denied environment undertaken by legged robots.
PST900: RGB-Thermal Calibration, Dataset and Segmentation Network
Sep 20, 2019

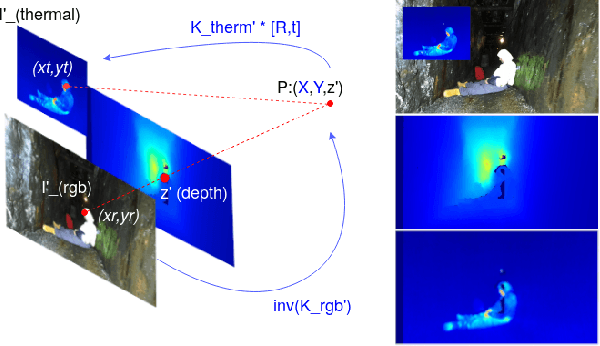

In this work we propose long wave infrared (LWIR) imagery as a viable supporting modality for semantic segmentation using learning-based techniques. We first address the problem of RGB-thermal camera calibration by proposing a passive calibration target and procedure that is both portable and easy to use. Second, we present PST900, a dataset of 894 synchronized and calibrated RGB and Thermal image pairs with per pixel human annotations across four distinct classes from the DARPA Subterranean Challenge. Lastly, we propose a CNN architecture for fast semantic segmentation that combines both RGB and Thermal imagery in a way that leverages RGB imagery independently. We compare our method against the state-of-the-art and show that our method outperforms them in our dataset.
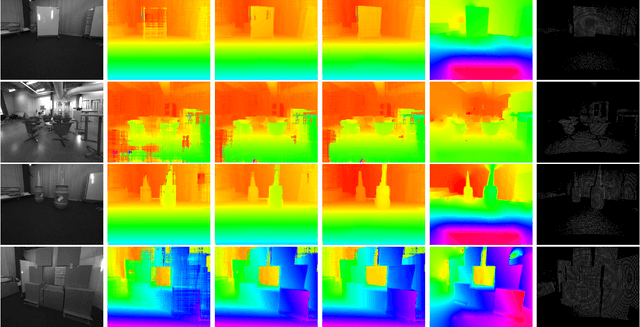
DFineNet: Ego-Motion Estimation and Depth Refinement from Sparse, Noisy Depth Input with RGB Guidance
Apr 10, 2019

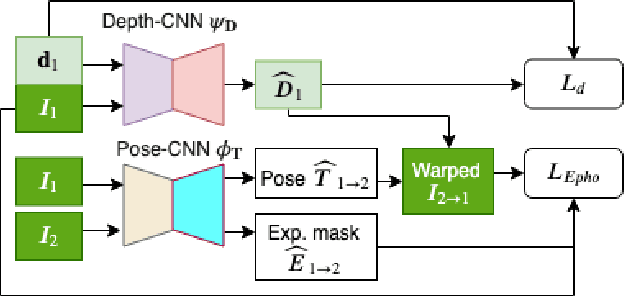

Depth estimation is an important capability for autonomous vehicles to understand and reconstruct 3D environments as well as avoid obstacles during the execution. Accurate depth sensors such as LiDARs are often heavy, expensive and can only provide sparse depth while lighter depth sensors such as stereo cameras are noiser in comparison. We propose an end-to-end learning algorithm that is capable of using sparse, noisy input depth for refinement and depth completion. Our model also produces the camera pose as a byproduct, making it a great solution for autonomous systems. We evaluate our approach on both indoor and outdoor datasets. Empirical results show that our method performs well on the KITTI~\cite{kitti_geiger2012we} dataset when compared to other competing methods, while having superior performance in dealing with sparse, noisy input depth on the TUM~\cite{sturm12iros} dataset.
Monocular Camera Based Fruit Counting and Mapping with Semantic Data Association
Mar 18, 2019



We present a cheap, lightweight, and fast fruit counting pipeline that uses a single monocular camera. Our pipeline that relies only on a monocular camera, achieves counting performance comparable to state-of-the-art fruit counting system that utilizes an expensive sensor suite including LiDAR and GPS/INS on a mango dataset. Our monocular camera pipeline begins with a fruit detection component that uses a deep neural network. It then uses semantic structure from motion (SFM) to convert these detections into fruit counts by estimating landmark locations of the fruit in 3D, and using these landmarks to identify double counting scenarios. There are many benefits of developing a low cost and lightweight fruit counting system, including applicability to agriculture in developing countries, where monetary constraints or unstructured environments necessitate cheaper hardware solutions.
DFuseNet: Deep Fusion of RGB and Sparse Depth Information for Image Guided Dense Depth Completion
Feb 02, 2019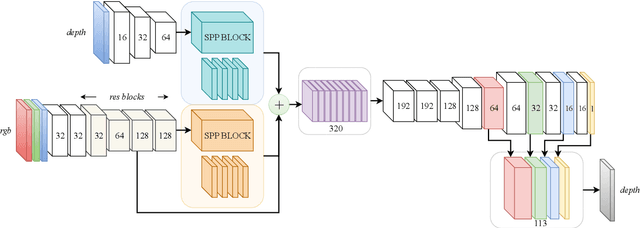


In this paper we propose a convolutional neural network that is designed to upsample a series of sparse range measurements based on the contextual cues gleaned from a high resolution intensity image. Our approach draws inspiration from related work on super-resolution and in-painting. We propose a novel architecture that seeks to pull contextual cues separately from the intensity image and the depth features and then fuse them later in the network. We argue that this approach effectively exploits the relationship between the two modalities and produces accurate results while respecting salient image structures. We present experimental results to demonstrate that our approach is comparable with state of the art methods and generalizes well across multiple datasets.
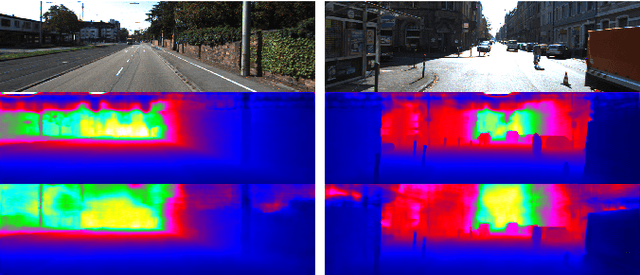
Real Time Dense Depth Estimation by Fusing Stereo with Sparse Depth Measurements
Sep 20, 2018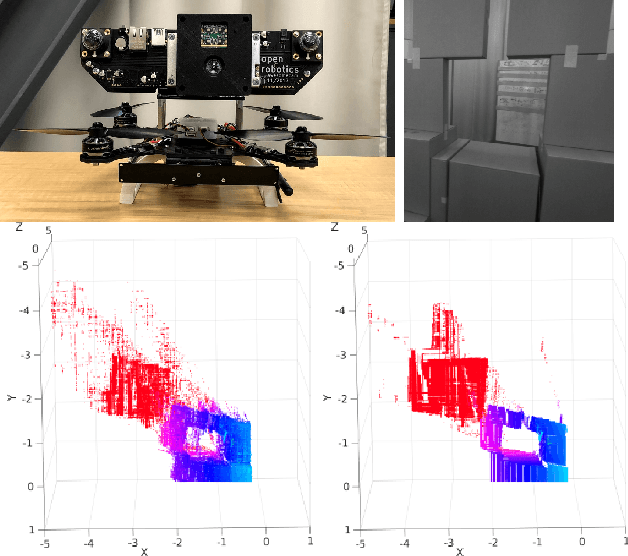
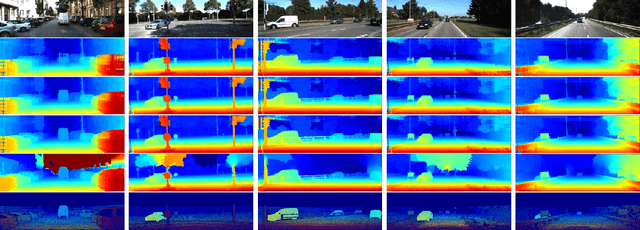
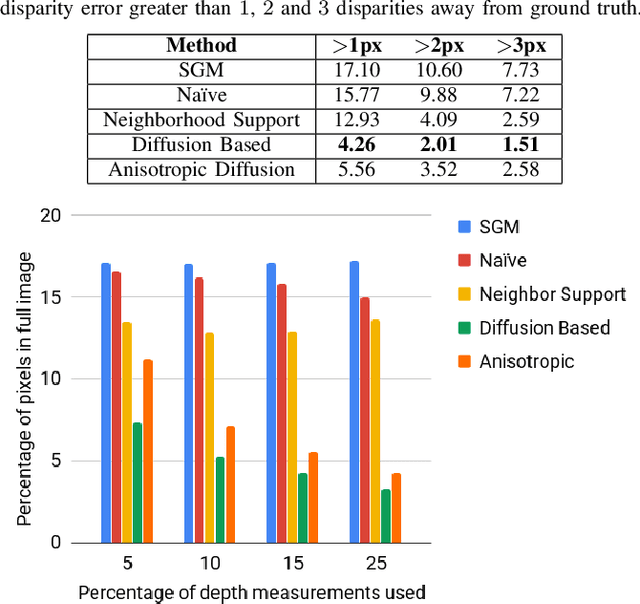
We present an approach to depth estimation that fuses information from a stereo pair with sparse range measurements derived from a LIDAR sensor or a range camera. The goal of this work is to exploit the complementary strengths of the two sensor modalities, the accurate but sparse range measurements and the ambiguous but dense stereo information. These two sources are effectively and efficiently fused by combining ideas from anisotropic diffusion and semi-global matching. We evaluate our approach on the KITTI 2015 and Middlebury 2014 datasets, using randomly sampled ground truth range measurements as our sparse depth input. We achieve significant performance improvements with a small fraction of range measurements on both datasets. We also provide qualitative results from our platform using the PMDTec Monstar sensor. Our entire pipeline runs on an NVIDIA TX-2 platform at 5Hz on 1280x1024 stereo images with 128 disparity levels.