 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpin: An Efficient Secure Computation Framework with GPU Acceleration
Feb 04, 2024



Accuracy and efficiency remain challenges for multi-party computation (MPC) frameworks. Spin is a GPU-accelerated MPC framework that supports multiple computation parties and a dishonest majority adversarial setup. We propose optimized protocols for non-linear functions that are critical for machine learning, as well as several novel optimizations specific to attention that is the fundamental unit of Transformer models, allowing Spin to perform non-trivial CNNs training and Transformer inference without sacrificing security. At the backend level, Spin leverages GPU, CPU, and RDMA-enabled smart network cards for acceleration. Comprehensive evaluations demonstrate that Spin can be up to $2\times$ faster than the state-of-the-art for deep neural network training. For inference on a Transformer model with 18.9 million parameters, our attention-specific optimizations enable Spin to achieve better efficiency, less communication, and better accuracy.
Neural Bounding
Oct 10, 2023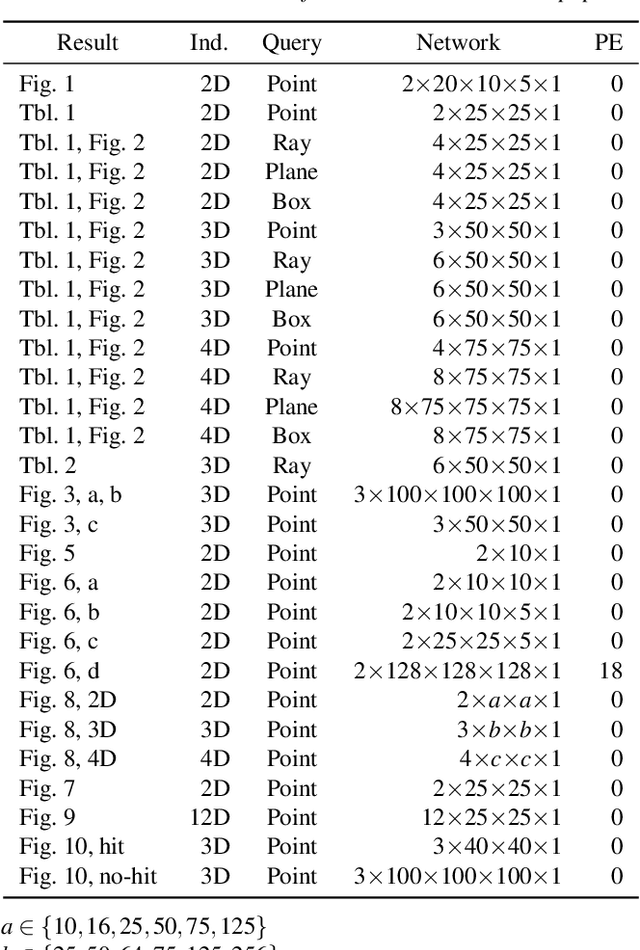
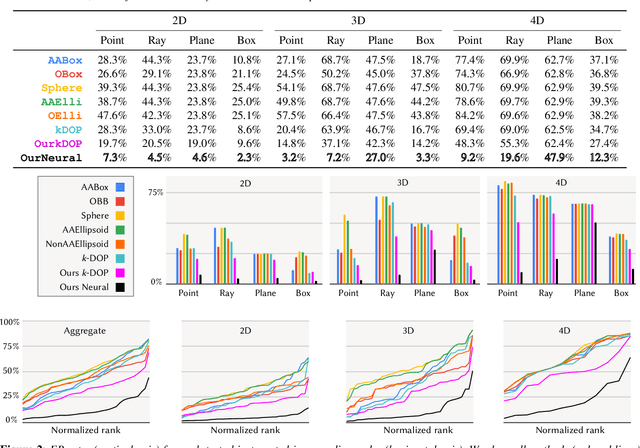
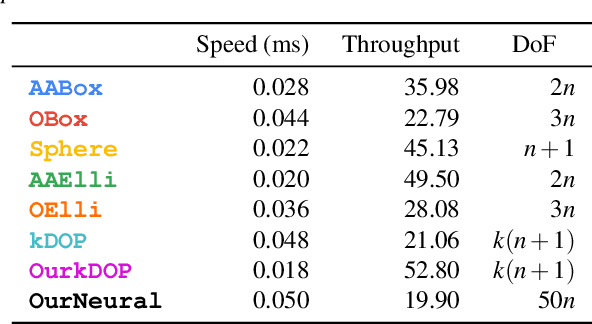

Bounding volumes are an established concept in computer graphics and vision tasks but have seen little change since their early inception. In this work, we study the use of neural networks as bounding volumes. Our key observation is that bounding, which so far has primarily been considered a problem of computational geometry, can be redefined as a problem of learning to classify space into free and empty. This learning-based approach is particularly advantageous in high-dimensional spaces, such as animated scenes with complex queries, where neural networks are known to excel. However, unlocking neural bounding requires a twist: allowing -- but also limiting -- false positives, while ensuring that the number of false negatives is strictly zero. We enable such tight and conservative results using a dynamically-weighted asymmetric loss function. Our results show that our neural bounding produces up to an order of magnitude fewer false positives than traditional methods.
LLOL: Low-Latency Odometry for Spinning Lidars
Oct 04, 2021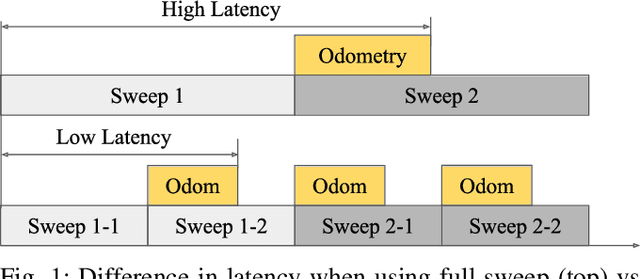



In this paper, we present a low-latency odometry system designed for spinning lidars. Many existing lidar odometry methods wait for an entire sweep from the lidar before processing the data. This introduces a large delay between the first laser firing and its pose estimate. To reduce this latency, we treat the spinning lidar as a streaming sensor and process packets as they arrive. This effectively distributes expensive operations across time, resulting in a very fast and lightweight system with much higher throughput and lower latency. Our open-source implementation is available at \url{https://github.com/versatran01/llol}.
Feature Importance-aware Transferable Adversarial Attacks
Aug 22, 2021
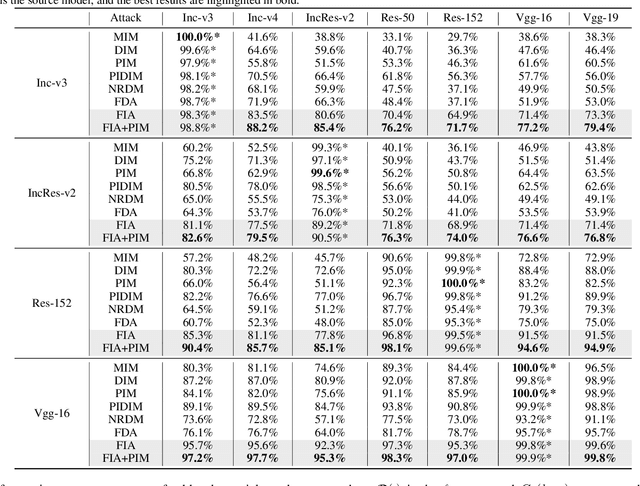
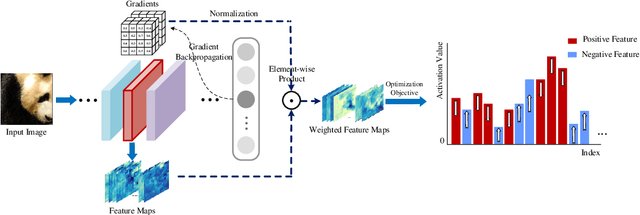
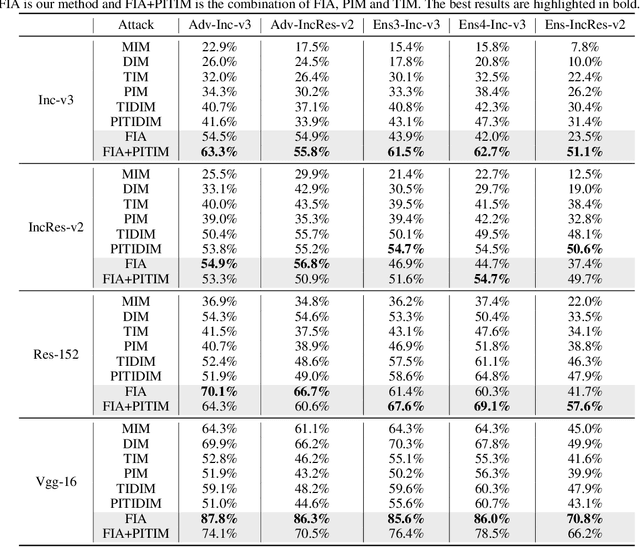
Transferability of adversarial examples is of central importance for attacking an unknown model, which facilitates adversarial attacks in more practical scenarios, e.g., black-box attacks. Existing transferable attacks tend to craft adversarial examples by indiscriminately distorting features to degrade prediction accuracy in a source model without aware of intrinsic features of objects in the images. We argue that such brute-force degradation would introduce model-specific local optimum into adversarial examples, thus limiting the transferability. By contrast, we propose the Feature Importance-aware Attack (FIA), which disrupts important object-aware features that dominate model decisions consistently. More specifically, we obtain feature importance by introducing the aggregate gradient, which averages the gradients with respect to feature maps of the source model, computed on a batch of random transforms of the original clean image. The gradients will be highly correlated to objects of interest, and such correlation presents invariance across different models. Besides, the random transforms will preserve intrinsic features of objects and suppress model-specific information. Finally, the feature importance guides to search for adversarial examples towards disrupting critical features, achieving stronger transferability. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FIA, i.e., improving the success rate by 9.5% against normally trained models and 12.8% against defense models as compared to the state-of-the-art transferable attacks. Code is available at: https://github.com/hcguoO0/FIA
Bayesian Deep Basis Fitting for Depth Completion with Uncertainty
Mar 29, 2021

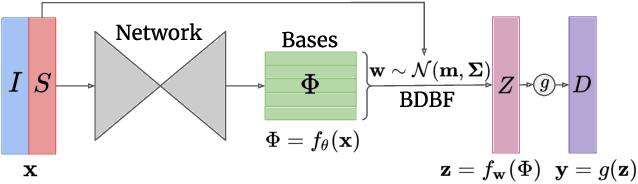

In this work we investigate the problem of uncertainty estimation for image-guided depth completion. We extend Deep Basis Fitting (DBF) for depth completion within a Bayesian evidence framework to provide calibrated per-pixel variance. The DBF approach frames the depth completion problem in terms of a network that produces a set of low-dimensional depth bases and a differentiable least squares fitting module that computes the basis weights using the sparse depths. By adopting a Bayesian treatment, our Bayesian Deep Basis Fitting (BDBF) approach is able to 1) predict high-quality uncertainty estimates and 2) enable depth completion with few or no sparse measurements. We conduct controlled experiments to compare BDBF against commonly used techniques for uncertainty estimation under various scenarios. Results show that our method produces better uncertainty estimates with accurate depth prediction.
TLIO: Tight Learned Inertial Odometry
Jul 10, 2020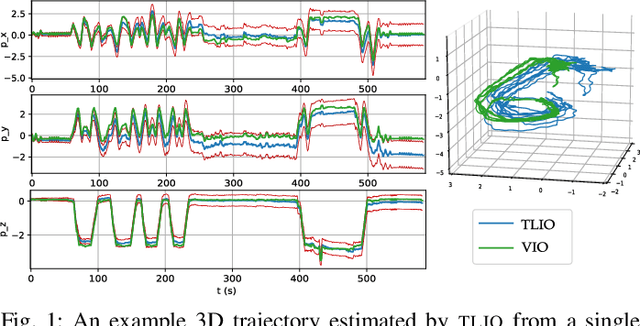
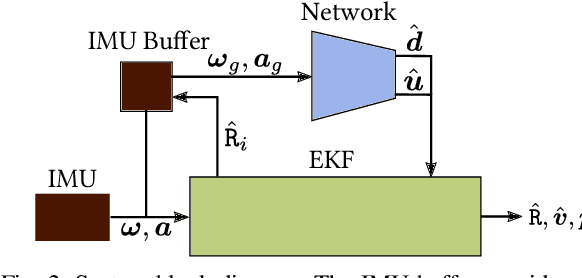
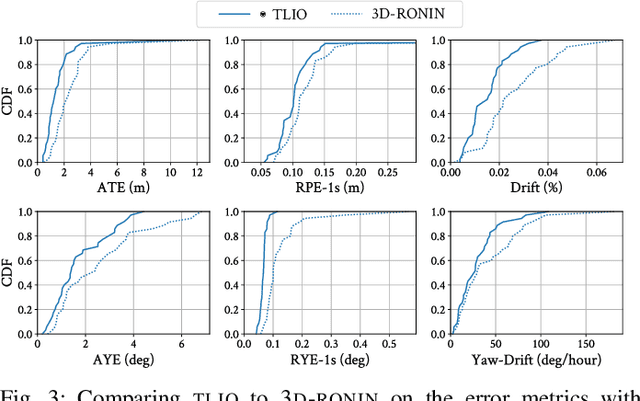
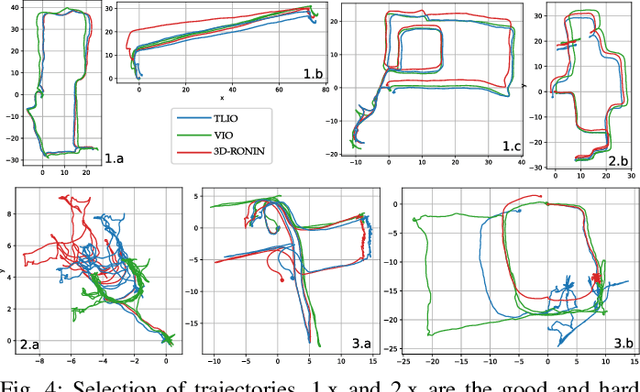
In this work we propose a tightly-coupled Extended Kalman Filter framework for IMU-only state estimation. Strap-down IMU measurements provide relative state estimates based on IMU kinematic motion model. However the integration of measurements is sensitive to sensor bias and noise, causing significant drift within seconds. Recent research by Yan et al. (RoNIN) and Chen et al. (IONet) showed the capability of using trained neural networks to obtain accurate 2D displacement estimates from segments of IMU data and obtained good position estimates from concatenating them. This paper demonstrates a network that regresses 3D displacement estimates and its uncertainty, giving us the ability to tightly fuse the relative state measurement into a stochastic cloning EKF to solve for pose, velocity and sensor biases. We show that our network, trained with pedestrian data from a headset, can produce statistically consistent measurement and uncertainty to be used as the update step in the filter, and the tightly-coupled system outperforms velocity integration approaches in position estimates, and AHRS attitude filter in orientation estimates.
Nuclear Environments Inspection with Micro Aerial Vehicles: Algorithms and Experiments
Mar 14, 2019



In this work, we address the estimation, planning, control and mapping problems to allow a small quadrotor to autonomously inspect the interior of hazardous damaged nuclear sites. These algorithms run onboard on a computationally limited CPU. We investigate the effect of varying illumination on the system performance. To the best of our knowledge, this is the first fully autonomous system of this size and scale applied to inspect the interior of a full scale mock-up of a Primary Containment Vessel (PCV). The proposed solution opens up new ways to inspect nuclear reactors and to support nuclear decommissioning, which is well known to be a dangerous, long and tedious process. Experimental results with varying illumination conditions show the ability to navigate a full scale mock-up PCV pedestal and create a map of the environment, while concurrently avoiding obstacles.
Robustness Meets Deep Learning: An End-to-End Hybrid Pipeline for Unsupervised Learning of Egomotion
Dec 21, 2018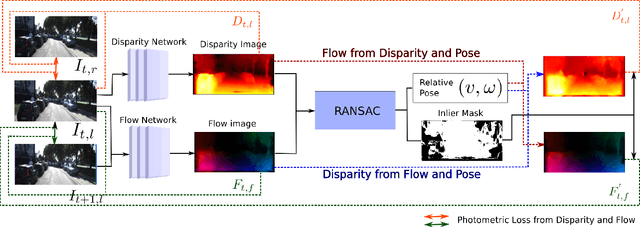

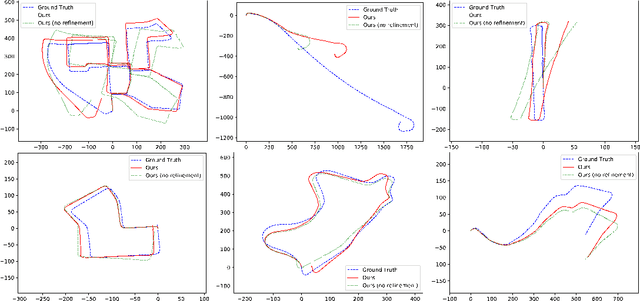

In this work, we propose a method that combines unsupervised deep learning predictions for optical flow and monocular disparity with a model based optimization procedure for camera pose. Given the flow and disparity predictions from the network, we apply a RANSAC outlier rejection scheme to find an inlier set of flows and disparities, which we use to solve for the camera pose in a least squares fashion. We show that this pipeline is fully differentiable, allowing us to combine the pose with the network outputs as an additional unsupervised training loss to further refine the predicted flows and disparities. This method not only allows us to directly regress pose from the network outputs, but also automatically segments away pixels that do not fit the rigid scene assumptions that many unsupervised structure from motion methods apply, such as on independently moving objects. We evaluate our method on the KITTI dataset, and demonstrate state of the art results, even in the presence of challenging independently moving objects.