 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Deep Dispersed Watermarking with Synchronization and Fusion
Oct 23, 2023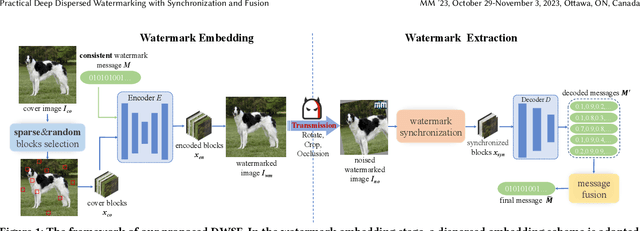

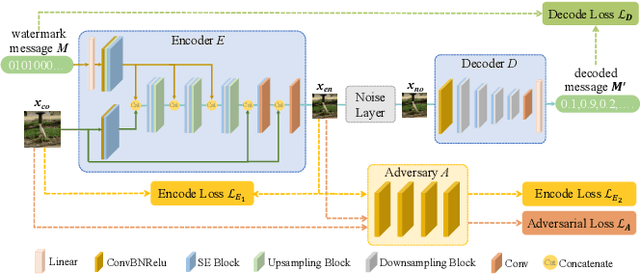
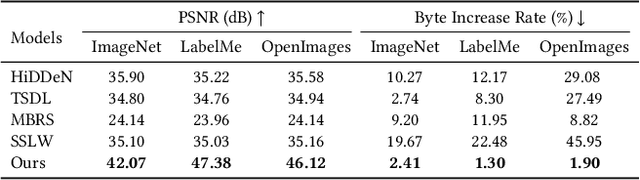
Deep learning based blind watermarking works have gradually emerged and achieved impressive performance. However, previous deep watermarking studies mainly focus on fixed low-resolution images while paying less attention to arbitrary resolution images, especially widespread high-resolution images nowadays. Moreover, most works usually demonstrate robustness against typical non-geometric attacks (\textit{e.g.}, JPEG compression) but ignore common geometric attacks (\textit{e.g.}, Rotate) and more challenging combined attacks. To overcome the above limitations, we propose a practical deep \textbf{D}ispersed \textbf{W}atermarking with \textbf{S}ynchronization and \textbf{F}usion, called \textbf{\proposed}. Specifically, given an arbitrary-resolution cover image, we adopt a dispersed embedding scheme which sparsely and randomly selects several fixed small-size cover blocks to embed a consistent watermark message by a well-trained encoder. In the extraction stage, we first design a watermark synchronization module to locate and rectify the encoded blocks in the noised watermarked image. We then utilize a decoder to obtain messages embedded in these blocks, and propose a message fusion strategy based on similarity to make full use of the consistency among messages, thus determining a reliable message. Extensive experiments conducted on different datasets convincingly demonstrate the effectiveness of our proposed {\proposed}. Compared with state-of-the-art approaches, our blind watermarking can achieve better performance: averagely improve the bit accuracy by 5.28\% and 5.93\% against single and combined attacks, respectively, and show less file size increment and better visual quality. Our code is available at https://github.com/bytedance/DWSF.
Vanilla Feature Distillation for Improving the Accuracy-Robustness Trade-Off in Adversarial Training
Jun 05, 2022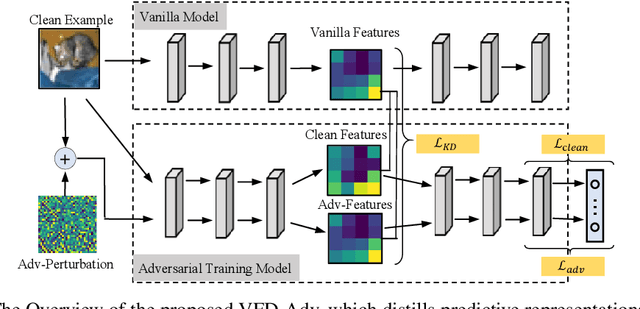
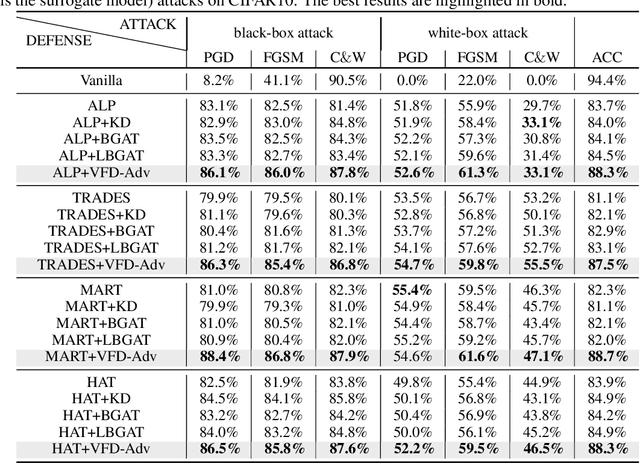
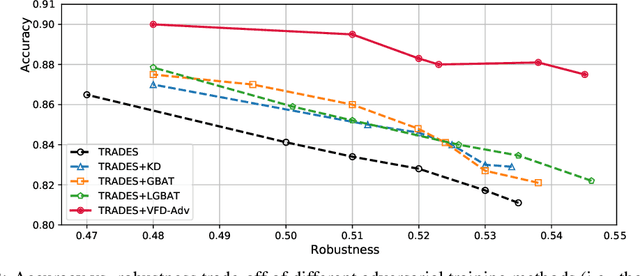
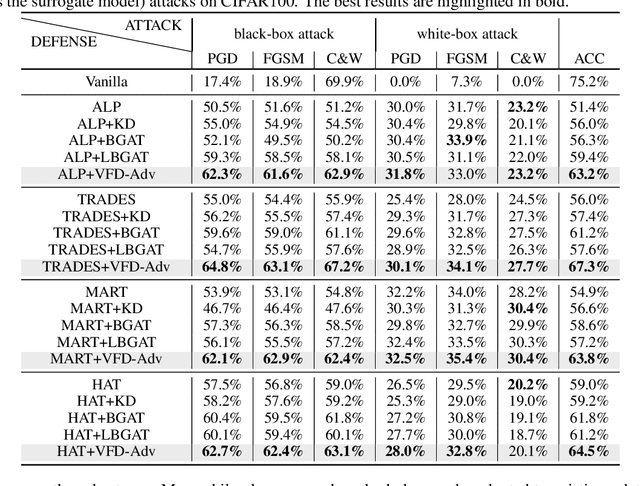
Adversarial training has been widely explored for mitigating attacks against deep models. However, most existing works are still trapped in the dilemma between higher accuracy and stronger robustness since they tend to fit a model towards robust features (not easily tampered with by adversaries) while ignoring those non-robust but highly predictive features. To achieve a better robustness-accuracy trade-off, we propose the Vanilla Feature Distillation Adversarial Training (VFD-Adv), which conducts knowledge distillation from a pre-trained model (optimized towards high accuracy) to guide adversarial training towards higher accuracy, i.e., preserving those non-robust but predictive features. More specifically, both adversarial examples and their clean counterparts are forced to be aligned in the feature space by distilling predictive representations from the pre-trained/clean model, while previous works barely utilize predictive features from clean models. Therefore, the adversarial training model is updated towards maximally preserving the accuracy as gaining robustness. A key advantage of our method is that it can be universally adapted to and boost existing works. Exhaustive experiments on various datasets, classification models, and adversarial training algorithms demonstrate the effectiveness of our proposed method.
Feature Importance-aware Transferable Adversarial Attacks
Aug 22, 2021
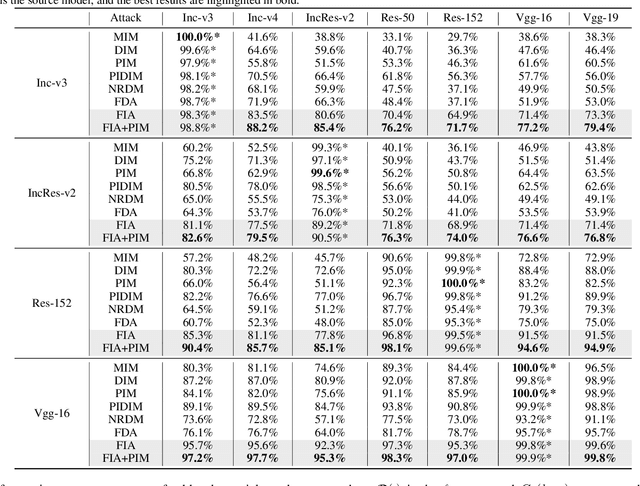
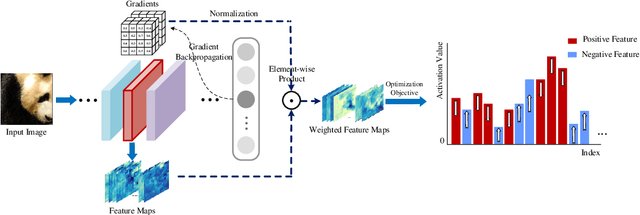
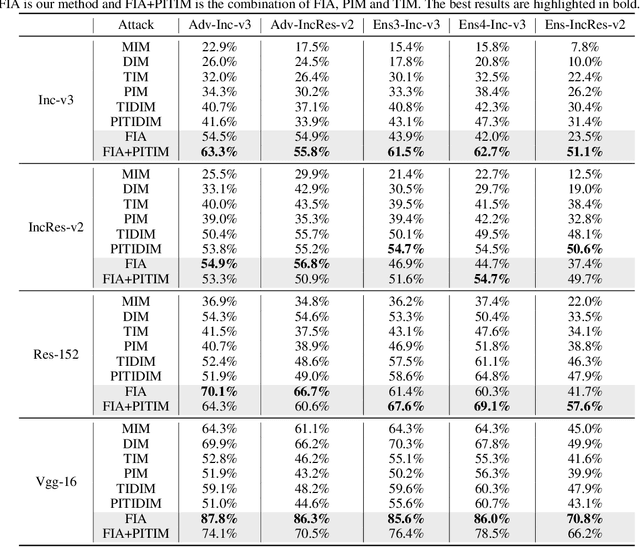
Transferability of adversarial examples is of central importance for attacking an unknown model, which facilitates adversarial attacks in more practical scenarios, e.g., black-box attacks. Existing transferable attacks tend to craft adversarial examples by indiscriminately distorting features to degrade prediction accuracy in a source model without aware of intrinsic features of objects in the images. We argue that such brute-force degradation would introduce model-specific local optimum into adversarial examples, thus limiting the transferability. By contrast, we propose the Feature Importance-aware Attack (FIA), which disrupts important object-aware features that dominate model decisions consistently. More specifically, we obtain feature importance by introducing the aggregate gradient, which averages the gradients with respect to feature maps of the source model, computed on a batch of random transforms of the original clean image. The gradients will be highly correlated to objects of interest, and such correlation presents invariance across different models. Besides, the random transforms will preserve intrinsic features of objects and suppress model-specific information. Finally, the feature importance guides to search for adversarial examples towards disrupting critical features, achieving stronger transferability. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FIA, i.e., improving the success rate by 9.5% against normally trained models and 12.8% against defense models as compared to the state-of-the-art transferable attacks. Code is available at: https://github.com/hcguoO0/FIA