 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanilla Feature Distillation for Improving the Accuracy-Robustness Trade-Off in Adversarial Training
Jun 05, 2022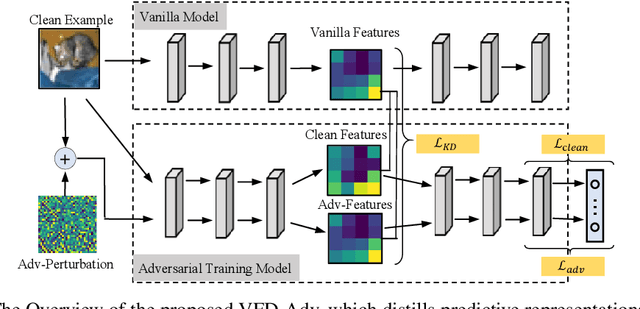
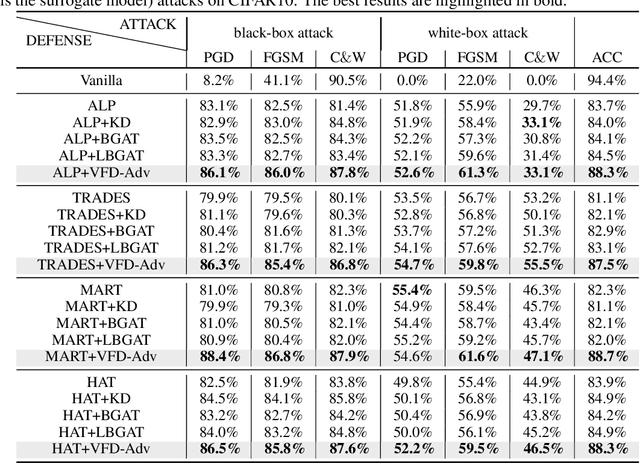
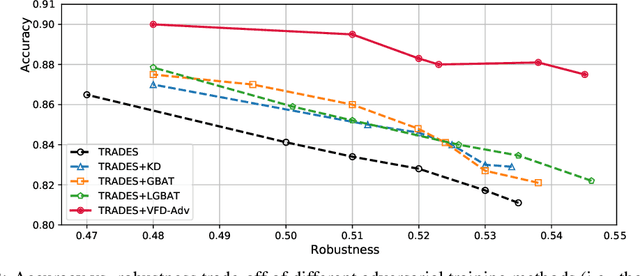
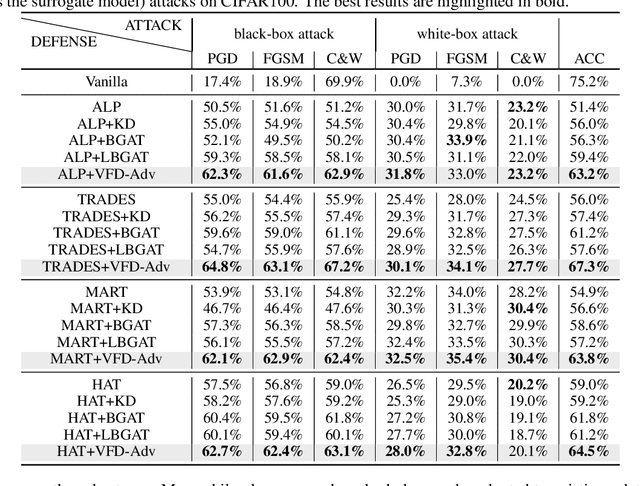
Adversarial training has been widely explored for mitigating attacks against deep models. However, most existing works are still trapped in the dilemma between higher accuracy and stronger robustness since they tend to fit a model towards robust features (not easily tampered with by adversaries) while ignoring those non-robust but highly predictive features. To achieve a better robustness-accuracy trade-off, we propose the Vanilla Feature Distillation Adversarial Training (VFD-Adv), which conducts knowledge distillation from a pre-trained model (optimized towards high accuracy) to guide adversarial training towards higher accuracy, i.e., preserving those non-robust but predictive features. More specifically, both adversarial examples and their clean counterparts are forced to be aligned in the feature space by distilling predictive representations from the pre-trained/clean model, while previous works barely utilize predictive features from clean models. Therefore, the adversarial training model is updated towards maximally preserving the accuracy as gaining robustness. A key advantage of our method is that it can be universally adapted to and boost existing works. Exhaustive experiments on various datasets, classification models, and adversarial training algorithms demonstrate the effectiveness of our proposed method.
Fairness-aware Adversarial Perturbation Towards Bias Mitigation for Deployed Deep Models
Mar 03, 2022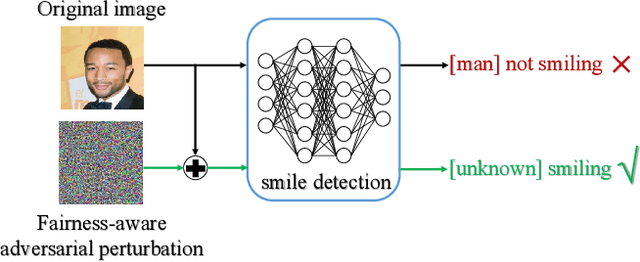

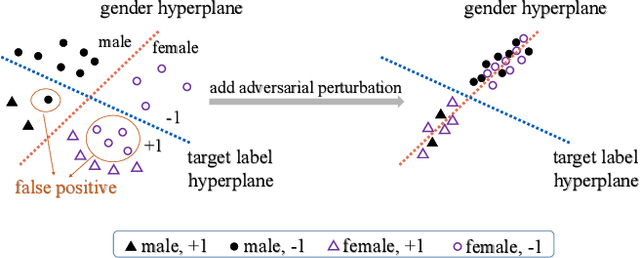
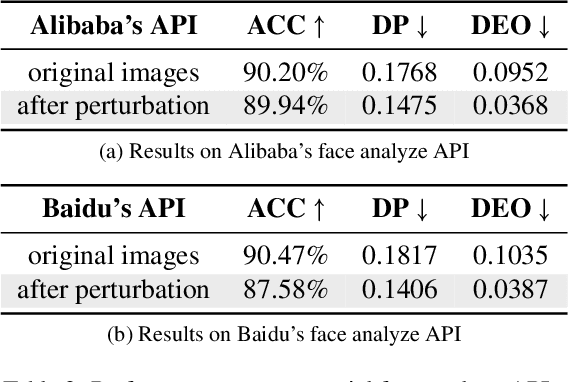
Prioritizing fairness is of central importance in artificial intelligence (AI) systems, especially for those societal applications, e.g., hiring systems should recommend applicants equally from different demographic groups, and risk assessment systems must eliminate racism in criminal justice. Existing efforts towards the ethical development of AI systems have leveraged data science to mitigate biases in the training set or introduced fairness principles into the training process. For a deployed AI system, however, it may not allow for retraining or tuning in practice. By contrast, we propose a more flexible approach, i.e., fairness-aware adversarial perturbation (FAAP), which learns to perturb input data to blind deployed models on fairness-related features, e.g., gender and ethnicity. The key advantage is that FAAP does not modify deployed models in terms of parameters and structures. To achieve this, we design a discriminator to distinguish fairness-related attributes based on latent representations from deployed models. Meanwhile, a perturbation generator is trained against the discriminator, such that no fairness-related features could be extracted from perturbed inputs. Exhaustive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FAAP. In addition, FAAP is validated on real-world commercial deployments (inaccessible to model parameters), which shows the transferability of FAAP, foreseeing the potential of black-box adaptation.