 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(MGS)$^2$-Net: Unifying Micro-Geometric Scale and Macro-Geometric Structure for Cross-View Geo-Localization
Feb 11, 2026Cross-view geo-localization (CVGL) is pivotal for GNSS-denied UAV navigation but remains brittle under the drastic geometric misalignment between oblique aerial views and orthographic satellite references. Existing methods predominantly operate within a 2D manifold, neglecting the underlying 3D geometry where view-dependent vertical facades (macro-structure) and scale variations (micro-scale) severely corrupt feature alignment. To bridge this gap, we propose (MGS)$^2$, a geometry-grounded framework. The core of our innovation is the Macro-Geometric Structure Filtering (MGSF) module. Unlike pixel-wise matching sensitive to noise, MGSF leverages dilated geometric gradients to physically filter out high-frequency facade artifacts while enhancing the view-invariant horizontal plane, directly addressing the domain shift. To guarantee robust input for this structural filtering, we explicitly incorporate a Micro-Geometric Scale Adaptation (MGSA) module. MGSA utilizes depth priors to dynamically rectify scale discrepancies via multi-branch feature fusion. Furthermore, a Geometric-Appearance Contrastive Distillation (GACD) loss is designed to strictly discriminate against oblique occlusions. Extensive experiments demonstrate that (MGS)$^2$ achieves state-of-the-art performance, recording a Recall@1 of 97.5\% on University-1652 and 97.02\% on SUES-200. Furthermore, the framework exhibits superior cross-dataset generalization against geometric ambiguity. The code is available at: \href{https://github.com/GabrielLi1473/MGS-Net}{https://github.com/GabrielLi1473/MGS-Net}.
A Unified Study of LoRA Variants: Taxonomy, Review, Codebase, and Empirical Evaluation
Jan 30, 2026Low-Rank Adaptation (LoRA) is a fundamental parameter-efficient fine-tuning method that balances efficiency and performance in large-scale neural networks. However, the proliferation of LoRA variants has led to fragmentation in methodology, theory, code, and evaluation. To this end, this work presents the first unified study of LoRA variants, offering a systematic taxonomy, unified theoretical review, structured codebase, and standardized empirical assessment. First, we categorize LoRA variants along four principal axes: rank, optimization dynamics, initialization, and integration with Mixture-of-Experts. Then, we review their relationships and evolution within a common theoretical framework focused on low-rank update dynamics. Further, we introduce LoRAFactory, a modular codebase that implements variants through a unified interface, supporting plug-and-play experimentation and fine-grained analysis. Last, using this codebase, we conduct a large-scale evaluation across natural language generation, natural language understanding, and image classification tasks, systematically exploring key hyperparameters. Our results uncover several findings, notably: LoRA and its variants exhibit pronounced sensitivity to the choices of learning rate compared to other hyperparameters; moreover, with proper hyperparameter configurations, LoRA consistently matches or surpasses the performance of most of its variants.
LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
Dec 30, 2025The transition from static Large Language Models (LLMs) to self-improving agents is hindered by the lack of structured reasoning in traditional evolutionary approaches. Existing methods often struggle with premature convergence and inefficient exploration in high-dimensional code spaces. To address these challenges, we introduce LoongFlow, a self-evolving agent framework that achieves state-of-the-art solution quality with significantly reduced computational costs. Unlike "blind" mutation operators, LoongFlow integrates LLMs into a cognitive "Plan-Execute-Summarize" (PES) paradigm, effectively mapping the evolutionary search to a reasoning-heavy process. To sustain long-term architectural coherence, we incorporate a hybrid evolutionary memory system. By synergizing Multi-Island models with MAP-Elites and adaptive Boltzmann selection, this system theoretically balances the exploration-exploitation trade-off, maintaining diverse behavioral niches to prevent optimization stagnation. We instantiate LoongFlow with a General Agent for algorithmic discovery and an ML Agent for pipeline optimization. Extensive evaluations on the AlphaEvolve benchmark and Kaggle competitions demonstrate that LoongFlow outperforms leading baselines (e.g., OpenEvolve, ShinkaEvolve) by up to 60% in evolutionary efficiency while discovering superior solutions. LoongFlow marks a substantial step forward in autonomous scientific discovery, enabling the generation of expert-level solutions with reduced computational overhead.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
SegTalker: Segmentation-based Talking Face Generation with Mask-guided Local Editing
Sep 05, 2024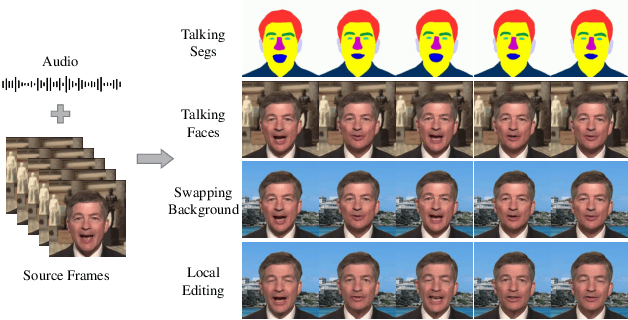
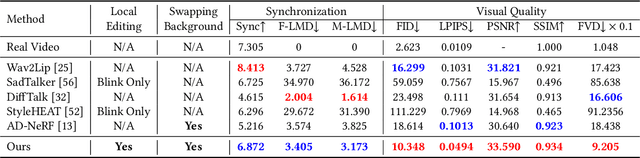
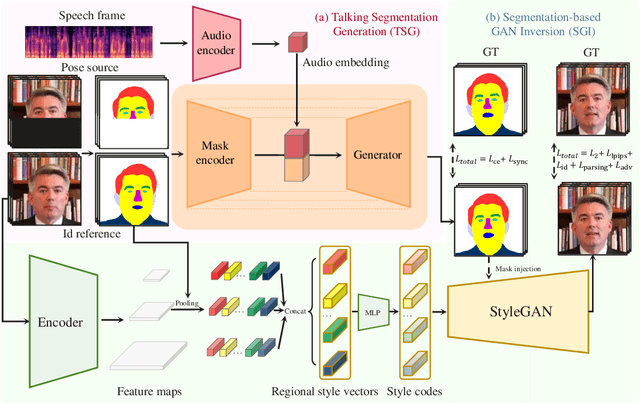
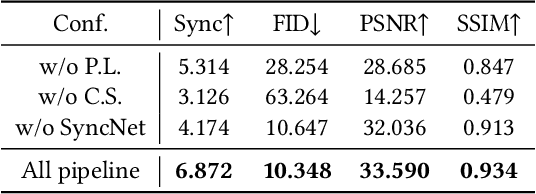
Audio-driven talking face generation aims to synthesize video with lip movements synchronized to input audio. However, current generative techniques face challenges in preserving intricate regional textures (skin, teeth). To address the aforementioned challenges, we propose a novel framework called SegTalker to decouple lip movements and image textures by introducing segmentation as intermediate representation. Specifically, given the mask of image employed by a parsing network, we first leverage the speech to drive the mask and generate talking segmentation. Then we disentangle semantic regions of image into style codes using a mask-guided encoder. Ultimately, we inject the previously generated talking segmentation and style codes into a mask-guided StyleGAN to synthesize video frame. In this way, most of textures are fully preserved. Moreover, our approach can inherently achieve background separation and facilitate mask-guided facial local editing. In particular, by editing the mask and swapping the region textures from a given reference image (e.g. hair, lip, eyebrows), our approach enables facial editing seamlessly when generating talking face video. Experiments demonstrate that our proposed approach can effectively preserve texture details and generate temporally consistent video while remaining competitive in lip synchronization. Quantitative and qualitative results on the HDTF and MEAD datasets illustrate the superior performance of our method over existing methods.
Landmark-guided Diffusion Model for High-fidelity and Temporally Coherent Talking Head Generation
Aug 03, 2024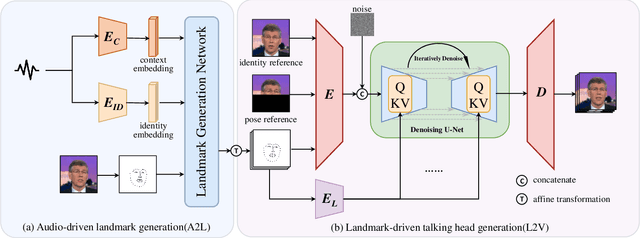

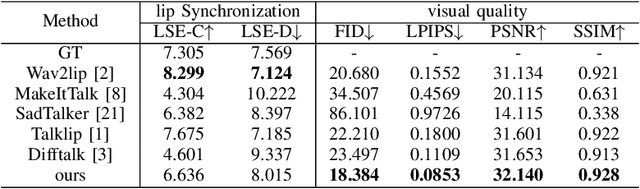
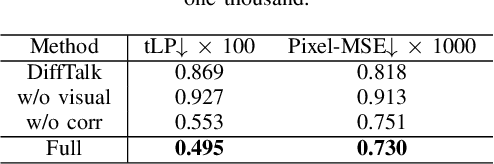
Audio-driven talking head generation is a significant and challenging task applicable to various fields such as virtual avatars, film production, and online conferences. However, the existing GAN-based models emphasize generating well-synchronized lip shapes but overlook the visual quality of generated frames, while diffusion-based models prioritize generating high-quality frames but neglect lip shape matching, resulting in jittery mouth movements. To address the aforementioned problems, we introduce a two-stage diffusion-based model. The first stage involves generating synchronized facial landmarks based on the given speech. In the second stage, these generated landmarks serve as a condition in the denoising process, aiming to optimize mouth jitter issues and generate high-fidelity, well-synchronized, and temporally coherent talking head videos. Extensive experiments demonstrate that our model yields the best performance.
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Jun 06, 2024



Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
Multi-Channel Multi-Step Spectrum Prediction Using Transformer and Stacked Bi-LSTM
May 29, 2024



Spectrum prediction is considered as a key technology to assist spectrum decision. Despite the great efforts that have been put on the construction of spectrum prediction, achieving accurate spectrum prediction emphasizes the need for more advanced solutions. In this paper, we propose a new multichannel multi-step spectrum prediction method using Transformer and stacked bidirectional LSTM (Bi- LSTM), named TSB. Specifically, we use multi-head attention and stacked Bi-LSTM to build a new Transformer based on encoder-decoder architecture. The self-attention mechanism composed of multiple layers of multi-head attention can continuously attend to all positions of the multichannel spectrum sequences. The stacked Bi-LSTM can learn these focused coding features by multi-head attention layer by layer. The advantage of this fusion mode is that it can deeply capture the long-term dependence of multichannel spectrum data. We have conducted extensive experiments on a dataset generated by a real simulation platform. The results show that the proposed algorithm performs better than the baselines.
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024
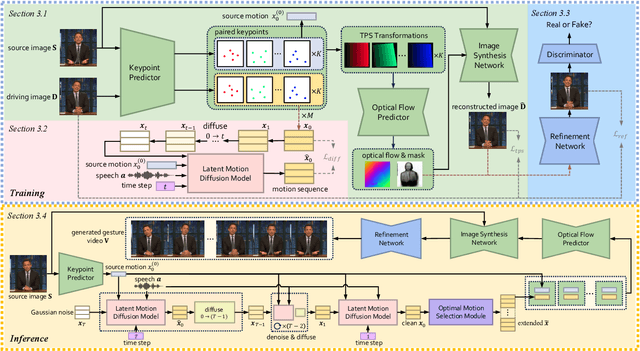

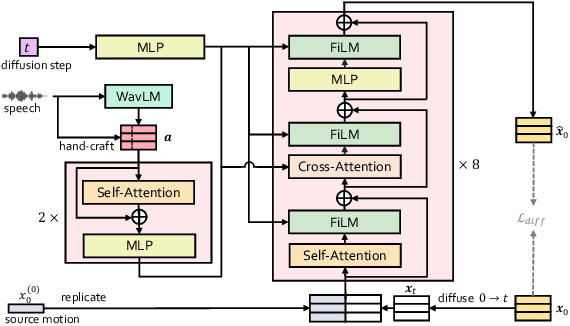
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
Syllable based DNN-HMM Cantonese Speech to Text System
Feb 13, 2024This paper reports our work on building up a Cantonese Speech-to-Text (STT) system with a syllable based acoustic model. This is a part of an effort in building a STT system to aid dyslexic students who have cognitive deficiency in writing skills but have no problem expressing their ideas through speech. For Cantonese speech recognition, the basic unit of acoustic models can either be the conventional Initial-Final (IF) syllables, or the Onset-Nucleus-Coda (ONC) syllables where finals are further split into nucleus and coda to reflect the intra-syllable variations in Cantonese. By using the Kaldi toolkit, our system is trained using the stochastic gradient descent optimization model with the aid of GPUs for the hybrid Deep Neural Network and Hidden Markov Model (DNN-HMM) with and without I-vector based speaker adaptive training technique. The input features of the same Gaussian Mixture Model with speaker adaptive training (GMM-SAT) to DNN are used in all cases. Experiments show that the ONC-based syllable acoustic modeling with I-vector based DNN-HMM achieves the best performance with the word error rate (WER) of 9.66% and the real time factor (RTF) of 1.38812.