 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandmark-guided Diffusion Model for High-fidelity and Temporally Coherent Talking Head Generation
Paper and Code
Aug 03, 2024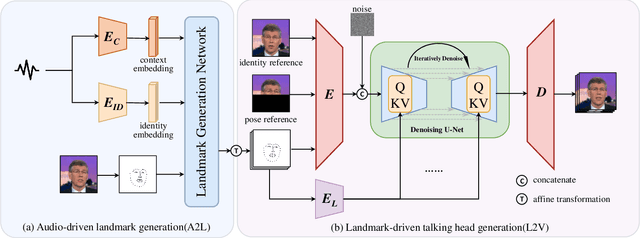

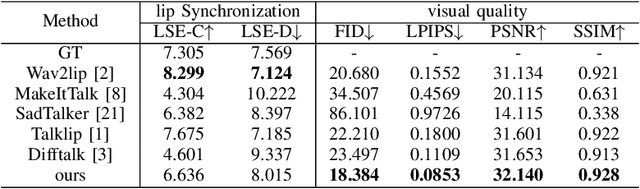
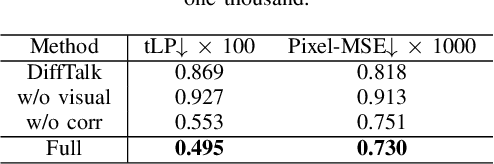
Audio-driven talking head generation is a significant and challenging task applicable to various fields such as virtual avatars, film production, and online conferences. However, the existing GAN-based models emphasize generating well-synchronized lip shapes but overlook the visual quality of generated frames, while diffusion-based models prioritize generating high-quality frames but neglect lip shape matching, resulting in jittery mouth movements. To address the aforementioned problems, we introduce a two-stage diffusion-based model. The first stage involves generating synchronized facial landmarks based on the given speech. In the second stage, these generated landmarks serve as a condition in the denoising process, aiming to optimize mouth jitter issues and generate high-fidelity, well-synchronized, and temporally coherent talking head videos. Extensive experiments demonstrate that our model yields the best performance.