 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegTalker: Segmentation-based Talking Face Generation with Mask-guided Local Editing
Sep 05, 2024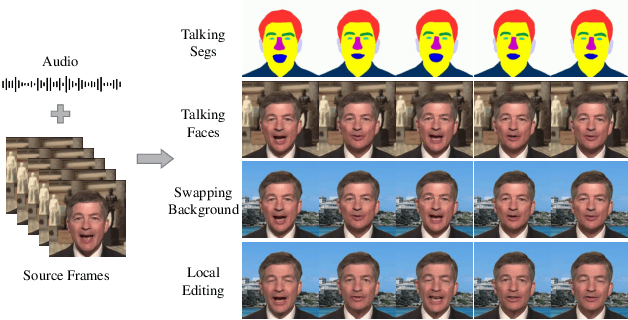
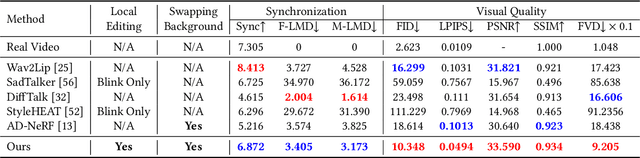
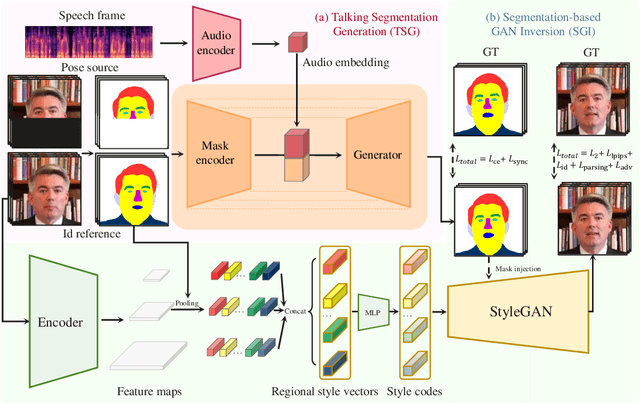
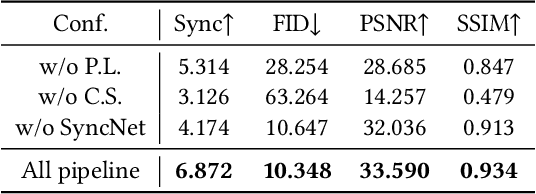
Audio-driven talking face generation aims to synthesize video with lip movements synchronized to input audio. However, current generative techniques face challenges in preserving intricate regional textures (skin, teeth). To address the aforementioned challenges, we propose a novel framework called SegTalker to decouple lip movements and image textures by introducing segmentation as intermediate representation. Specifically, given the mask of image employed by a parsing network, we first leverage the speech to drive the mask and generate talking segmentation. Then we disentangle semantic regions of image into style codes using a mask-guided encoder. Ultimately, we inject the previously generated talking segmentation and style codes into a mask-guided StyleGAN to synthesize video frame. In this way, most of textures are fully preserved. Moreover, our approach can inherently achieve background separation and facilitate mask-guided facial local editing. In particular, by editing the mask and swapping the region textures from a given reference image (e.g. hair, lip, eyebrows), our approach enables facial editing seamlessly when generating talking face video. Experiments demonstrate that our proposed approach can effectively preserve texture details and generate temporally consistent video while remaining competitive in lip synchronization. Quantitative and qualitative results on the HDTF and MEAD datasets illustrate the superior performance of our method over existing methods.
Landmark-guided Diffusion Model for High-fidelity and Temporally Coherent Talking Head Generation
Aug 03, 2024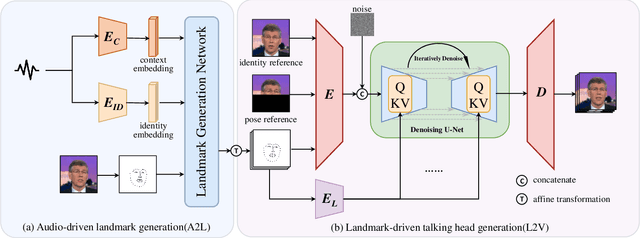

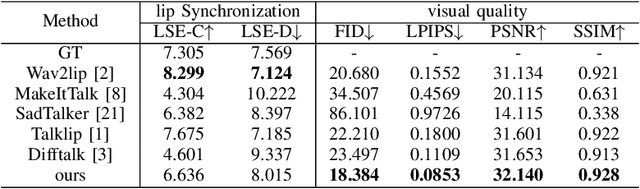
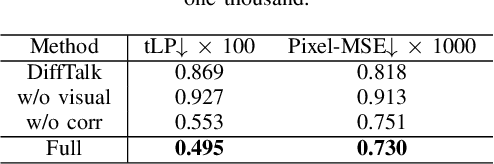
Audio-driven talking head generation is a significant and challenging task applicable to various fields such as virtual avatars, film production, and online conferences. However, the existing GAN-based models emphasize generating well-synchronized lip shapes but overlook the visual quality of generated frames, while diffusion-based models prioritize generating high-quality frames but neglect lip shape matching, resulting in jittery mouth movements. To address the aforementioned problems, we introduce a two-stage diffusion-based model. The first stage involves generating synchronized facial landmarks based on the given speech. In the second stage, these generated landmarks serve as a condition in the denoising process, aiming to optimize mouth jitter issues and generate high-fidelity, well-synchronized, and temporally coherent talking head videos. Extensive experiments demonstrate that our model yields the best performance.
GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Aug 03, 2024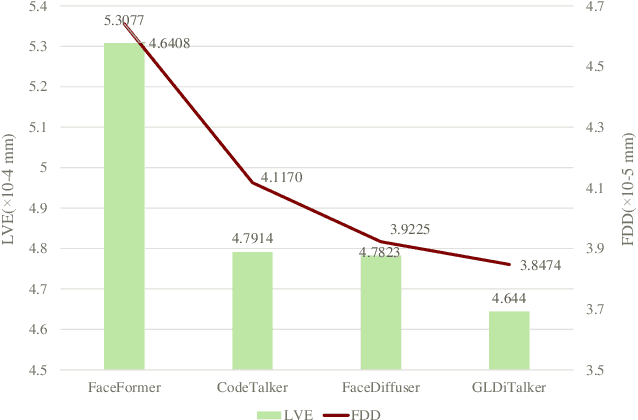
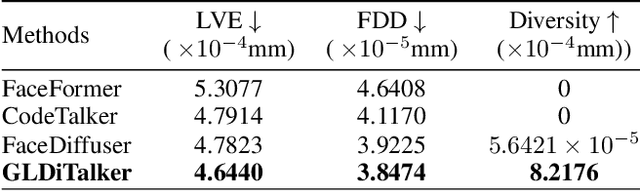
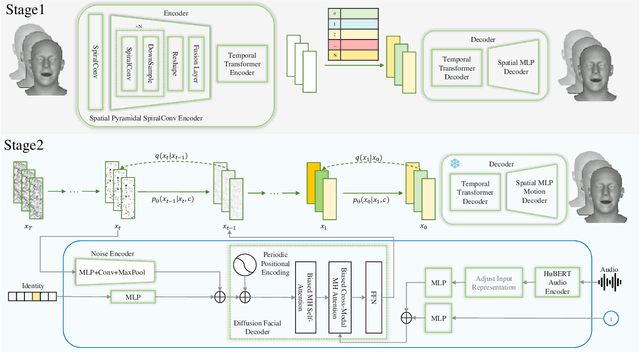
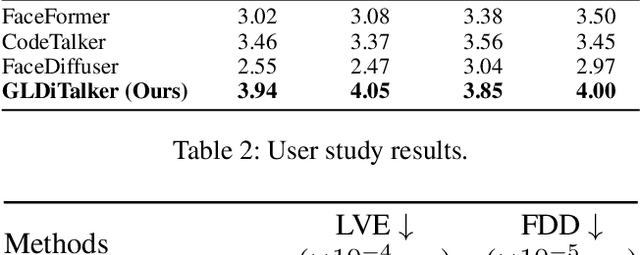
3D speech-driven facial animation generation has received much attention in both industrial applications and academic research. Since the non-verbal facial cues that exist across the face in reality are non-deterministic, the generated results should be diverse. However, most recent methods are deterministic models that cannot learn a many-to-many mapping between audio and facial motion to generate diverse facial animations. To address this problem, we propose GLDiTalker, which introduces a motion prior along with some stochasticity to reduce the uncertainty of cross-modal mapping while increasing non-determinacy of the non-verbal facial cues that reside throughout the face. Particularly, GLDiTalker uses VQ-VAE to map facial motion mesh sequences into latent space in the first stage, and then iteratively adds and removes noise to the latent facial motion features in the second stage. In order to integrate different levels of spatial information, the Spatial Pyramidal SpiralConv Encoder is also designed to extract multi-scale features. Extensive qualitative and quantitative experiments demonstrate that our method achieves the state-of-the-art performance.