 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Paper and Code
Aug 03, 2024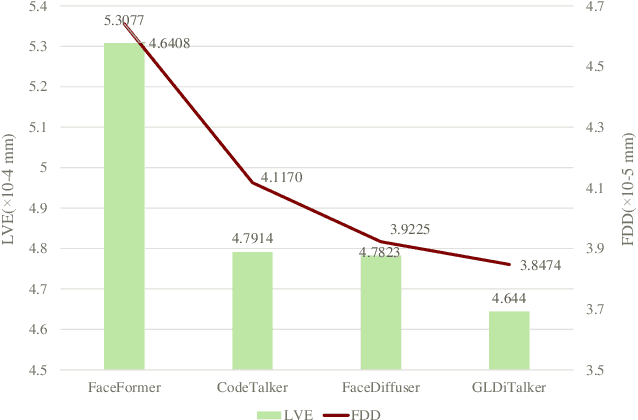
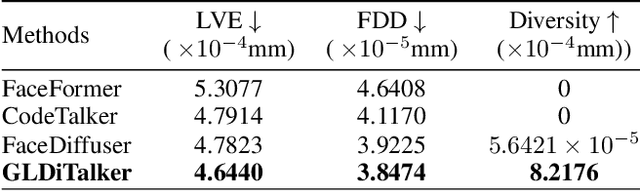
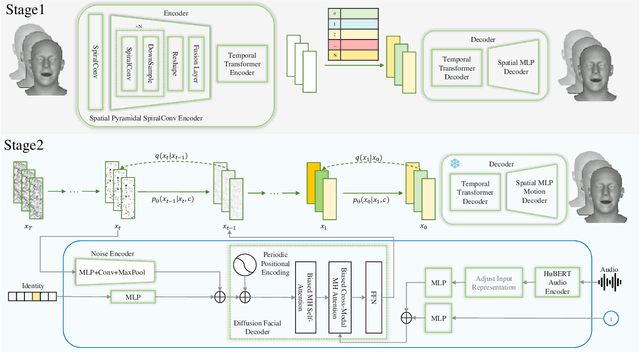
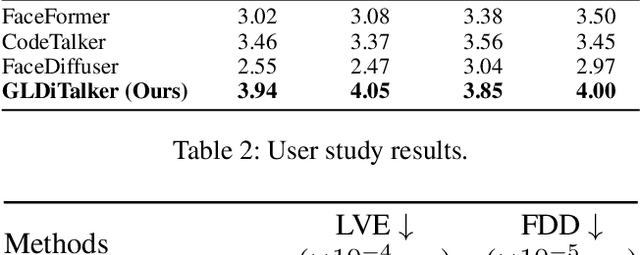
3D speech-driven facial animation generation has received much attention in both industrial applications and academic research. Since the non-verbal facial cues that exist across the face in reality are non-deterministic, the generated results should be diverse. However, most recent methods are deterministic models that cannot learn a many-to-many mapping between audio and facial motion to generate diverse facial animations. To address this problem, we propose GLDiTalker, which introduces a motion prior along with some stochasticity to reduce the uncertainty of cross-modal mapping while increasing non-determinacy of the non-verbal facial cues that reside throughout the face. Particularly, GLDiTalker uses VQ-VAE to map facial motion mesh sequences into latent space in the first stage, and then iteratively adds and removes noise to the latent facial motion features in the second stage. In order to integrate different levels of spatial information, the Spatial Pyramidal SpiralConv Encoder is also designed to extract multi-scale features. Extensive qualitative and quantitative experiments demonstrate that our method achieves the state-of-the-art performance.