 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DHMR: Monocular 3D Hand Mesh Recovery
May 26, 2025Monocular 3D hand mesh recovery is challenging due to high degrees of freedom of hands, 2D-to-3D ambiguity and self-occlusion. Most existing methods are either inefficient or less straightforward for predicting the position of 3D mesh vertices. Thus, we propose a new pipeline called Monocular 3D Hand Mesh Recovery (M3DHMR) to directly estimate the positions of hand mesh vertices. M3DHMR provides 2D cues for 3D tasks from a single image and uses a new spiral decoder consist of several Dynamic Spiral Convolution (DSC) Layers and a Region of Interest (ROI) Layer. On the one hand, DSC Layers adaptively adjust the weights based on the vertex positions and extract the vertex features in both spatial and channel dimensions. On the other hand, ROI Layer utilizes the physical information and refines mesh vertices in each predefined hand region separately. Extensive experiments on popular dataset FreiHAND demonstrate that M3DHMR significantly outperforms state-of-the-art real-time methods.
RecDreamer: Consistent Text-to-3D Generation via Uniform Score Distillation
Feb 18, 2025Current text-to-3D generation methods based on score distillation often suffer from geometric inconsistencies, leading to repeated patterns across different poses of 3D assets. This issue, known as the Multi-Face Janus problem, arises because existing methods struggle to maintain consistency across varying poses and are biased toward a canonical pose. While recent work has improved pose control and approximation, these efforts are still limited by this inherent bias, which skews the guidance during generation. To address this, we propose a solution called RecDreamer, which reshapes the underlying data distribution to achieve a more consistent pose representation. The core idea behind our method is to rectify the prior distribution, ensuring that pose variation is uniformly distributed rather than biased toward a canonical form. By modifying the prescribed distribution through an auxiliary function, we can reconstruct the density of the distribution to ensure compliance with specific marginal constraints. In particular, we ensure that the marginal distribution of poses follows a uniform distribution, thereby eliminating the biases introduced by the prior knowledge. We incorporate this rectified data distribution into existing score distillation algorithms, a process we refer to as uniform score distillation. To efficiently compute the posterior distribution required for the auxiliary function, RecDreamer introduces a training-free classifier that estimates pose categories in a plug-and-play manner. Additionally, we utilize various approximation techniques for noisy states, significantly improving system performance. Our experimental results demonstrate that RecDreamer effectively mitigates the Multi-Face Janus problem, leading to more consistent 3D asset generation across different poses.
EmoFace: Emotion-Content Disentangled Speech-Driven 3D Talking Face with Mesh Attention
Aug 21, 2024
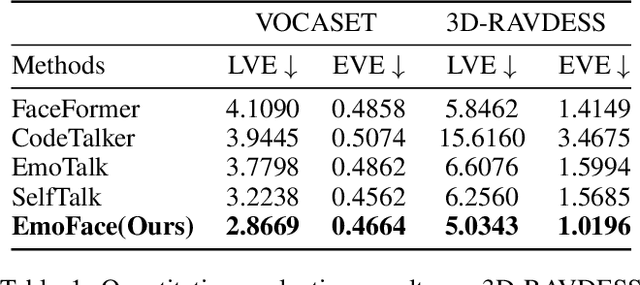
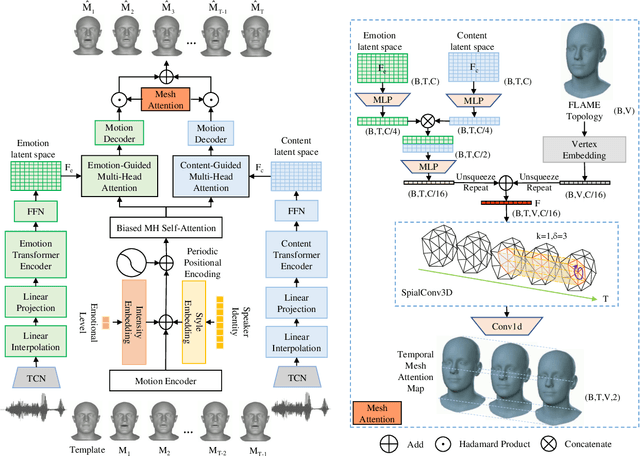

The creation of increasingly vivid 3D virtual digital humans has become a hot topic in recent years. Currently, most speech-driven work focuses on training models to learn the relationship between phonemes and visemes to achieve more realistic lips. However, they fail to capture the correlations between emotions and facial expressions effectively. To solve this problem, we propose a new model, termed EmoFace. EmoFace employs a novel Mesh Attention mechanism, which helps to learn potential feature dependencies between mesh vertices in time and space. We also adopt, for the first time to our knowledge, an effective self-growing training scheme that combines teacher-forcing and scheduled sampling in a 3D face animation task. Additionally, since EmoFace is an autoregressive model, there is no requirement that the first frame of the training data must be a silent frame, which greatly reduces the data limitations and contributes to solve the current dilemma of insufficient datasets. Comprehensive quantitative and qualitative evaluations on our proposed high-quality reconstructed 3D emotional facial animation dataset, 3D-RAVDESS ($5.0343\times 10^{-5}$mm for LVE and $1.0196\times 10^{-5}$mm for EVE), and publicly available dataset VOCASET ($2.8669\times 10^{-5}$mm for LVE and $0.4664\times 10^{-5}$mm for EVE), demonstrate that our algorithm achieves state-of-the-art performance.
GLDiTalker: Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer
Aug 03, 2024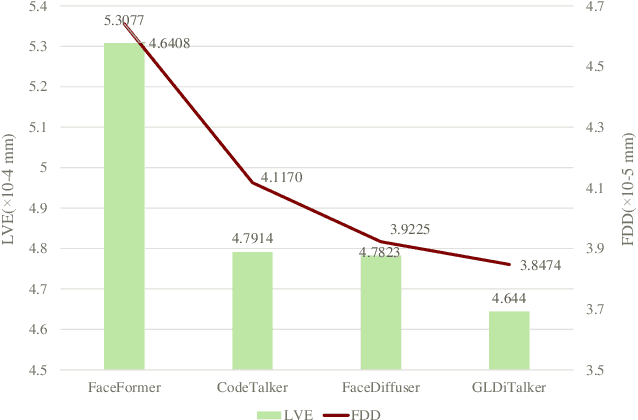
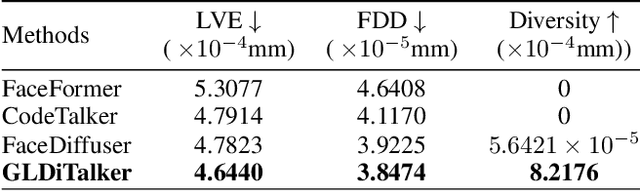
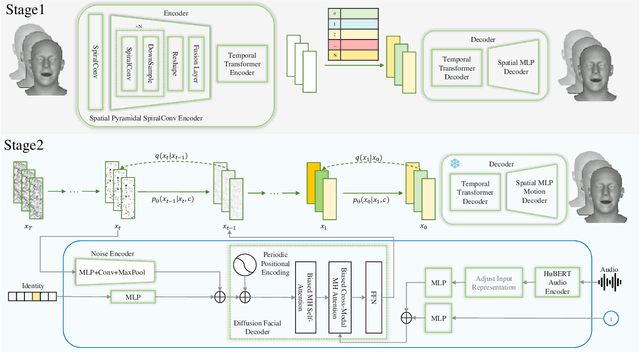
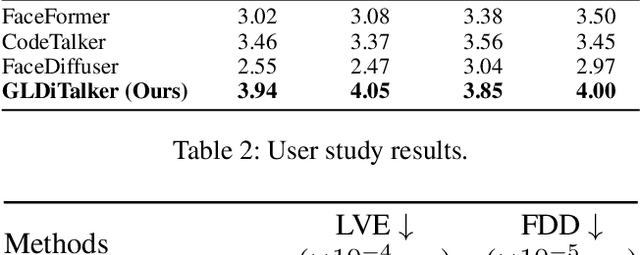
3D speech-driven facial animation generation has received much attention in both industrial applications and academic research. Since the non-verbal facial cues that exist across the face in reality are non-deterministic, the generated results should be diverse. However, most recent methods are deterministic models that cannot learn a many-to-many mapping between audio and facial motion to generate diverse facial animations. To address this problem, we propose GLDiTalker, which introduces a motion prior along with some stochasticity to reduce the uncertainty of cross-modal mapping while increasing non-determinacy of the non-verbal facial cues that reside throughout the face. Particularly, GLDiTalker uses VQ-VAE to map facial motion mesh sequences into latent space in the first stage, and then iteratively adds and removes noise to the latent facial motion features in the second stage. In order to integrate different levels of spatial information, the Spatial Pyramidal SpiralConv Encoder is also designed to extract multi-scale features. Extensive qualitative and quantitative experiments demonstrate that our method achieves the state-of-the-art performance.
STMR: Spiral Transformer for Hand Mesh Reconstruction
Jul 08, 2024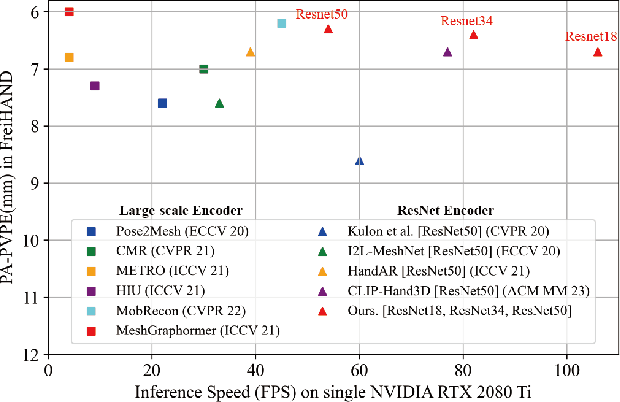
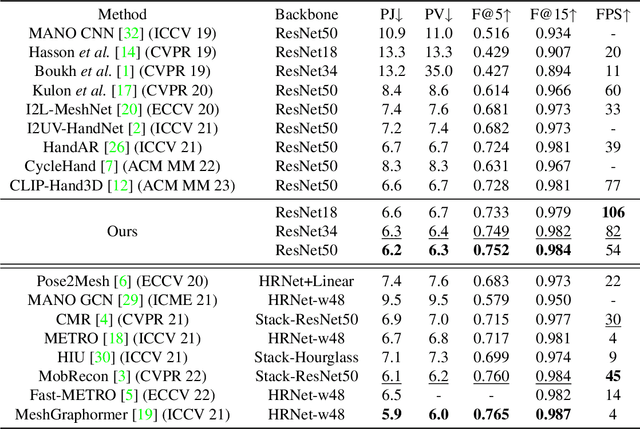

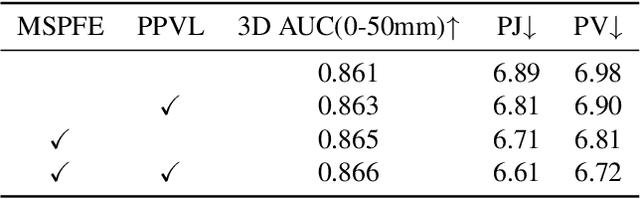
Recent advancements in both transformer-based methods and spiral neighbor sampling techniques have greatly enhanced hand mesh reconstruction. Transformers excel in capturing complex vertex relationships, and spiral neighbor sampling is vital for utilizing topological structures. This paper ingeniously integrates spiral sampling into the Transformer architecture, enhancing its ability to leverage mesh topology for superior performance in hand mesh reconstruction, resulting in substantial accuracy boosts. STMR employs a single image encoder for model efficiency. To augment its information extraction capability, we design the multi-scale pose feature extraction (MSPFE) module, which facilitates the extraction of rich pose features, ultimately enhancing the model's performance. Moreover, the proposed predefined pose-to-vertex lifting (PPVL) method improves vertex feature representation, further boosting reconstruction performance. Extensive experiments on the FreiHAND dataset demonstrate the state-of-the-art performance and unparalleled inference speed of STMR compared with similar backbone methods, showcasing its efficiency and effectiveness. The code is available at https://github.com/SmallXieGithub/STMR.