 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAR-TVG: Enhancing VLMs with Timestamp Anchor-Constrained Reasoning for Temporal Video Grounding
Aug 11, 2025Temporal Video Grounding (TVG) aims to precisely localize video segments corresponding to natural language queries, which is a critical capability for long-form video understanding. Although existing reinforcement learning approaches encourage models to generate reasoning chains before predictions, they fail to explicitly constrain the reasoning process to ensure the quality of the final temporal predictions. To address this limitation, we propose Timestamp Anchor-constrained Reasoning for Temporal Video Grounding (TAR-TVG), a novel framework that introduces timestamp anchors within the reasoning process to enforce explicit supervision to the thought content. These anchors serve as intermediate verification points. More importantly, we require each reasoning step to produce increasingly accurate temporal estimations, thereby ensuring that the reasoning process contributes meaningfully to the final prediction. To address the challenge of low-probability anchor generation in models (e.g., Qwen2.5-VL-3B), we develop an efficient self-distillation training strategy: (1) initial GRPO training to collect 30K high-quality reasoning traces containing multiple timestamp anchors, (2) supervised fine-tuning (SFT) on distilled data, and (3) final GRPO optimization on the SFT-enhanced model. This three-stage training strategy enables robust anchor generation while maintaining reasoning quality. Experiments show that our model achieves state-of-the-art performance while producing interpretable, verifiable reasoning chains with progressively refined temporal estimations.
Invert4TVG: A Temporal Video Grounding Framework with Inversion Tasks for Enhanced Action Understanding
Aug 10, 2025Temporal Video Grounding (TVG) seeks to localize video segments matching a given textual query. Current methods, while optimizing for high temporal Intersection-over-Union (IoU), often overfit to this metric, compromising semantic action understanding in the video and query, a critical factor for robust TVG. To address this, we introduce Inversion Tasks for TVG (Invert4TVG), a novel framework that enhances both localization accuracy and action understanding without additional data. Our approach leverages three inversion tasks derived from existing TVG annotations: (1) Verb Completion, predicting masked action verbs in queries from video segments; (2) Action Recognition, identifying query-described actions; and (3) Video Description, generating descriptions of video segments that explicitly embed query-relevant actions. These tasks, integrated with TVG via a reinforcement learning framework with well-designed reward functions, ensure balanced optimization of localization and semantics. Experiments show our method outperforms state-of-the-art approaches, achieving a 7.1\% improvement in R1@0.7 on Charades-STA for a 3B model compared to Time-R1. By inverting TVG to derive query-related actions from segments, our approach strengthens semantic understanding, significantly raising the ceiling of localization accuracy.
SITA: Structurally Imperceptible and Transferable Adversarial Attacks for Stylized Image Generation
Mar 25, 2025Image generation technology has brought significant advancements across various fields but has also raised concerns about data misuse and potential rights infringements, particularly with respect to creating visual artworks. Current methods aimed at safeguarding artworks often employ adversarial attacks. However, these methods face challenges such as poor transferability, high computational costs, and the introduction of noticeable noise, which compromises the aesthetic quality of the original artwork. To address these limitations, we propose a Structurally Imperceptible and Transferable Adversarial (SITA) attacks. SITA leverages a CLIP-based destylization loss, which decouples and disrupts the robust style representation of the image. This disruption hinders style extraction during stylized image generation, thereby impairing the overall stylization process. Importantly, SITA eliminates the need for a surrogate diffusion model, leading to significantly reduced computational overhead. The method's robust style feature disruption ensures high transferability across diverse models. Moreover, SITA introduces perturbations by embedding noise within the imperceptible structural details of the image. This approach effectively protects against style extraction without compromising the visual quality of the artwork. Extensive experiments demonstrate that SITA offers superior protection for artworks against unauthorized use in stylized generation. It significantly outperforms existing methods in terms of transferability, computational efficiency, and noise imperceptibility. Code is available at https://github.com/A-raniy-day/SITA.
SCJD: Sparse Correlation and Joint Distillation for Efficient 3D Human Pose Estimation
Mar 18, 2025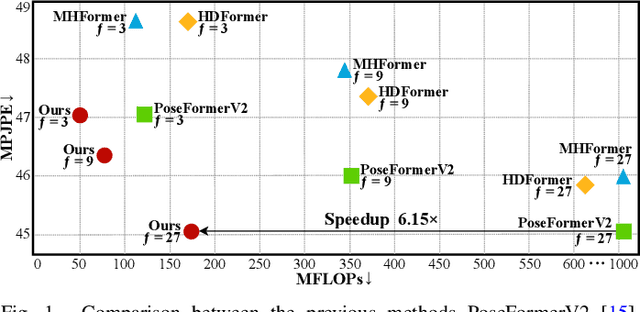
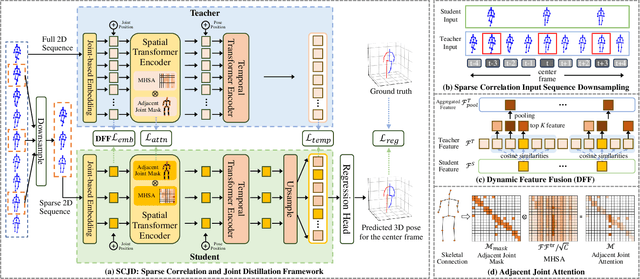
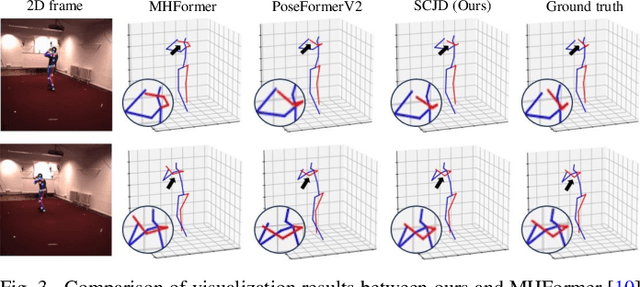
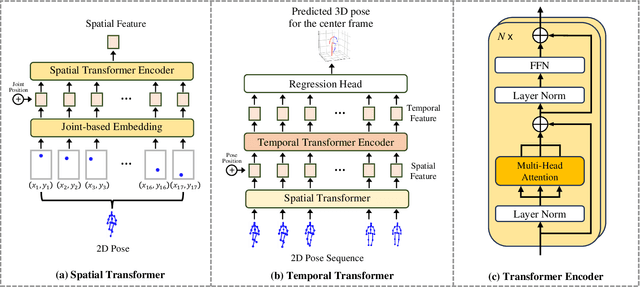
Existing 3D Human Pose Estimation (HPE) methods achieve high accuracy but suffer from computational overhead and slow inference, while knowledge distillation methods fail to address spatial relationships between joints and temporal correlations in multi-frame inputs. In this paper, we propose Sparse Correlation and Joint Distillation (SCJD), a novel framework that balances efficiency and accuracy for 3D HPE. SCJD introduces Sparse Correlation Input Sequence Downsampling to reduce redundancy in student network inputs while preserving inter-frame correlations. For effective knowledge transfer, we propose Dynamic Joint Spatial Attention Distillation, which includes Dynamic Joint Embedding Distillation to enhance the student's feature representation using the teacher's multi-frame context feature, and Adjacent Joint Attention Distillation to improve the student network's focus on adjacent joint relationships for better spatial understanding. Additionally, Temporal Consistency Distillation aligns the temporal correlations between teacher and student networks through upsampling and global supervision. Extensive experiments demonstrate that SCJD achieves state-of-the-art performance. Code is available at https://github.com/wileychan/SCJD.
RecDreamer: Consistent Text-to-3D Generation via Uniform Score Distillation
Feb 18, 2025Current text-to-3D generation methods based on score distillation often suffer from geometric inconsistencies, leading to repeated patterns across different poses of 3D assets. This issue, known as the Multi-Face Janus problem, arises because existing methods struggle to maintain consistency across varying poses and are biased toward a canonical pose. While recent work has improved pose control and approximation, these efforts are still limited by this inherent bias, which skews the guidance during generation. To address this, we propose a solution called RecDreamer, which reshapes the underlying data distribution to achieve a more consistent pose representation. The core idea behind our method is to rectify the prior distribution, ensuring that pose variation is uniformly distributed rather than biased toward a canonical form. By modifying the prescribed distribution through an auxiliary function, we can reconstruct the density of the distribution to ensure compliance with specific marginal constraints. In particular, we ensure that the marginal distribution of poses follows a uniform distribution, thereby eliminating the biases introduced by the prior knowledge. We incorporate this rectified data distribution into existing score distillation algorithms, a process we refer to as uniform score distillation. To efficiently compute the posterior distribution required for the auxiliary function, RecDreamer introduces a training-free classifier that estimates pose categories in a plug-and-play manner. Additionally, we utilize various approximation techniques for noisy states, significantly improving system performance. Our experimental results demonstrate that RecDreamer effectively mitigates the Multi-Face Janus problem, leading to more consistent 3D asset generation across different poses.
Rotation-Adaptive Point Cloud Domain Generalization via Intricate Orientation Learning
Feb 04, 2025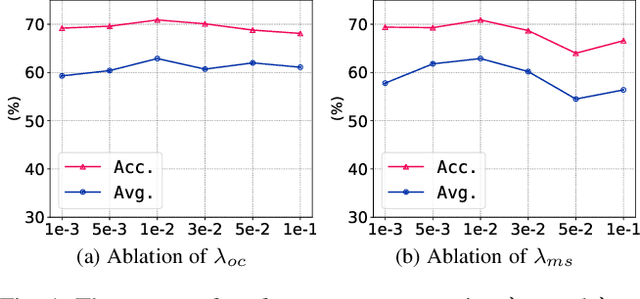



The vulnerability of 3D point cloud analysis to unpredictable rotations poses an open yet challenging problem: orientation-aware 3D domain generalization. Cross-domain robustness and adaptability of 3D representations are crucial but not easily achieved through rotation augmentation. Motivated by the inherent advantages of intricate orientations in enhancing generalizability, we propose an innovative rotation-adaptive domain generalization framework for 3D point cloud analysis. Our approach aims to alleviate orientational shifts by leveraging intricate samples in an iterative learning process. Specifically, we identify the most challenging rotation for each point cloud and construct an intricate orientation set by optimizing intricate orientations. Subsequently, we employ an orientation-aware contrastive learning framework that incorporates an orientation consistency loss and a margin separation loss, enabling effective learning of categorically discriminative and generalizable features with rotation consistency. Extensive experiments and ablations conducted on 3D cross-domain benchmarks firmly establish the state-of-the-art performance of our proposed approach in the context of orientation-aware 3D domain generalization.
DSDFormer: An Innovative Transformer-Mamba Framework for Robust High-Precision Driver Distraction Identification
Sep 09, 2024



Driver distraction remains a leading cause of traffic accidents, posing a critical threat to road safety globally. As intelligent transportation systems evolve, accurate and real-time identification of driver distraction has become essential. However, existing methods struggle to capture both global contextual and fine-grained local features while contending with noisy labels in training datasets. To address these challenges, we propose DSDFormer, a novel framework that integrates the strengths of Transformer and Mamba architectures through a Dual State Domain Attention (DSDA) mechanism, enabling a balance between long-range dependencies and detailed feature extraction for robust driver behavior recognition. Additionally, we introduce Temporal Reasoning Confident Learning (TRCL), an unsupervised approach that refines noisy labels by leveraging spatiotemporal correlations in video sequences. Our model achieves state-of-the-art performance on the AUC-V1, AUC-V2, and 100-Driver datasets and demonstrates real-time processing efficiency on the NVIDIA Jetson AGX Orin platform. Extensive experimental results confirm that DSDFormer and TRCL significantly improve both the accuracy and robustness of driver distraction detection, offering a scalable solution to enhance road safety.
VrdONE: One-stage Video Visual Relation Detection
Aug 18, 2024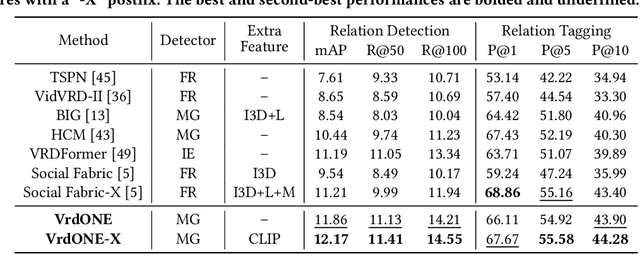

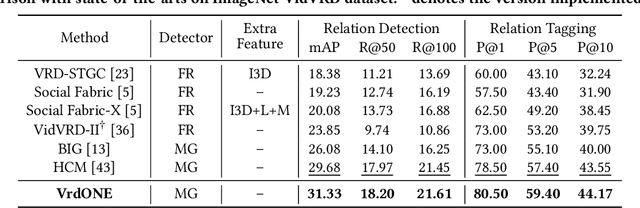

Video Visual Relation Detection (VidVRD) focuses on understanding how entities interact over time and space in videos, a key step for gaining deeper insights into video scenes beyond basic visual tasks. Traditional methods for VidVRD, challenged by its complexity, typically split the task into two parts: one for identifying what relation categories are present and another for determining their temporal boundaries. This split overlooks the inherent connection between these elements. Addressing the need to recognize entity pairs' spatiotemporal interactions across a range of durations, we propose VrdONE, a streamlined yet efficacious one-stage model. VrdONE combines the features of subjects and objects, turning predicate detection into 1D instance segmentation on their combined representations. This setup allows for both relation category identification and binary mask generation in one go, eliminating the need for extra steps like proposal generation or post-processing. VrdONE facilitates the interaction of features across various frames, adeptly capturing both short-lived and enduring relations. Additionally, we introduce the Subject-Object Synergy (SOS) module, enhancing how subjects and objects perceive each other before combining. VrdONE achieves state-of-the-art performances on the VidOR benchmark and ImageNet-VidVRD, showcasing its superior capability in discerning relations across different temporal scales. The code is available at \textcolor[RGB]{228,58,136}{\href{https://github.com/lucaspk512/vrdone}{https://github.com/lucaspk512/vrdone}}.
G2Face: High-Fidelity Reversible Face Anonymization via Generative and Geometric Priors
Aug 18, 2024



Reversible face anonymization, unlike traditional face pixelization, seeks to replace sensitive identity information in facial images with synthesized alternatives, preserving privacy without sacrificing image clarity. Traditional methods, such as encoder-decoder networks, often result in significant loss of facial details due to their limited learning capacity. Additionally, relying on latent manipulation in pre-trained GANs can lead to changes in ID-irrelevant attributes, adversely affecting data utility due to GAN inversion inaccuracies. This paper introduces G\textsuperscript{2}Face, which leverages both generative and geometric priors to enhance identity manipulation, achieving high-quality reversible face anonymization without compromising data utility. We utilize a 3D face model to extract geometric information from the input face, integrating it with a pre-trained GAN-based decoder. This synergy of generative and geometric priors allows the decoder to produce realistic anonymized faces with consistent geometry. Moreover, multi-scale facial features are extracted from the original face and combined with the decoder using our novel identity-aware feature fusion blocks (IFF). This integration enables precise blending of the generated facial patterns with the original ID-irrelevant features, resulting in accurate identity manipulation. Extensive experiments demonstrate that our method outperforms existing state-of-the-art techniques in face anonymization and recovery, while preserving high data utility. Code is available at https://github.com/Harxis/G2Face.
Beat-It: Beat-Synchronized Multi-Condition 3D Dance Generation
Jul 10, 2024Dance, as an art form, fundamentally hinges on the precise synchronization with musical beats. However, achieving aesthetically pleasing dance sequences from music is challenging, with existing methods often falling short in controllability and beat alignment. To address these shortcomings, this paper introduces Beat-It, a novel framework for beat-specific, key pose-guided dance generation. Unlike prior approaches, Beat-It uniquely integrates explicit beat awareness and key pose guidance, effectively resolving two main issues: the misalignment of generated dance motions with musical beats, and the inability to map key poses to specific beats, critical for practical choreography. Our approach disentangles beat conditions from music using a nearest beat distance representation and employs a hierarchical multi-condition fusion mechanism. This mechanism seamlessly integrates key poses, beats, and music features, mitigating condition conflicts and offering rich, multi-conditioned guidance for dance generation. Additionally, a specially designed beat alignment loss ensures the generated dance movements remain in sync with the designated beats. Extensive experiments confirm Beat-It's superiority over existing state-of-the-art methods in terms of beat alignment and motion controllability.