 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Computation- and Communication-efficient Computational Pathology
Apr 03, 2025Despite the impressive performance across a wide range of applications, current computational pathology models face significant diagnostic efficiency challenges due to their reliance on high-magnification whole-slide image analysis. This limitation severely compromises their clinical utility, especially in time-sensitive diagnostic scenarios and situations requiring efficient data transfer. To address these issues, we present a novel computation- and communication-efficient framework called Magnification-Aligned Global-Local Transformer (MAGA-GLTrans). Our approach significantly reduces computational time, file transfer requirements, and storage overhead by enabling effective analysis using low-magnification inputs rather than high-magnification ones. The key innovation lies in our proposed magnification alignment (MAGA) mechanism, which employs self-supervised learning to bridge the information gap between low and high magnification levels by effectively aligning their feature representations. Through extensive evaluation across various fundamental CPath tasks, MAGA-GLTrans demonstrates state-of-the-art classification performance while achieving remarkable efficiency gains: up to 10.7 times reduction in computational time and over 20 times reduction in file transfer and storage requirements. Furthermore, we highlight the versatility of our MAGA framework through two significant extensions: (1) its applicability as a feature extractor to enhance the efficiency of any CPath architecture, and (2) its compatibility with existing foundation models and histopathology-specific encoders, enabling them to process low-magnification inputs with minimal information loss. These advancements position MAGA-GLTrans as a particularly promising solution for time-sensitive applications, especially in the context of intraoperative frozen section diagnosis where both accuracy and efficiency are paramount.
BroadCAM: Outcome-agnostic Class Activation Mapping for Small-scale Weakly Supervised Applications
Sep 07, 2023



Class activation mapping~(CAM), a visualization technique for interpreting deep learning models, is now commonly used for weakly supervised semantic segmentation~(WSSS) and object localization~(WSOL). It is the weighted aggregation of the feature maps by activating the high class-relevance ones. Current CAM methods achieve it relying on the training outcomes, such as predicted scores~(forward information), gradients~(backward information), etc. However, when with small-scale data, unstable training may lead to less effective model outcomes and generate unreliable weights, finally resulting in incorrect activation and noisy CAM seeds. In this paper, we propose an outcome-agnostic CAM approach, called BroadCAM, for small-scale weakly supervised applications. Since broad learning system (BLS) is independent to the model learning, BroadCAM can avoid the weights being affected by the unreliable model outcomes when with small-scale data. By evaluating BroadCAM on VOC2012 (natural images) and BCSS-WSSS (medical images) for WSSS and OpenImages30k for WSOL, BroadCAM demonstrates superior performance than existing CAM methods with small-scale data (less than 5\%) in different CNN architectures. It also achieves SOTA performance with large-scale training data. Extensive qualitative comparisons are conducted to demonstrate how BroadCAM activates the high class-relevance feature maps and generates reliable CAMs when with small-scale training data.
Rethinking Mitosis Detection: Towards Diverse Data and Feature Representation
Jul 12, 2023Mitosis detection is one of the fundamental tasks in computational pathology, which is extremely challenging due to the heterogeneity of mitotic cell. Most of the current studies solve the heterogeneity in the technical aspect by increasing the model complexity. However, lacking consideration of the biological knowledge and the complex model design may lead to the overfitting problem while limited the generalizability of the detection model. In this paper, we systematically study the morphological appearances in different mitotic phases as well as the ambiguous non-mitotic cells and identify that balancing the data and feature diversity can achieve better generalizability. Based on this observation, we propose a novel generalizable framework (MitDet) for mitosis detection. The data diversity is considered by the proposed diversity-guided sample balancing (DGSB). And the feature diversity is preserved by inter- and intra- class feature diversity-preserved module (InCDP). Stain enhancement (SE) module is introduced to enhance the domain-relevant diversity of both data and features simultaneously. Extensive experiments have demonstrated that our proposed model outperforms all the SOTA approaches in several popular mitosis detection datasets in both internal and external test sets using minimal annotation efforts with point annotations only. Comprehensive ablation studies have also proven the effectiveness of the rethinking of data and feature diversity balancing. By analyzing the results quantitatively and qualitatively, we believe that our proposed model not only achieves SOTA performance but also might inspire the future studies in new perspectives. Source code is at https://github.com/Onehour0108/MitDet.
FedDBL: Communication and Data Efficient Federated Deep-Broad Learning for Histopathological Tissue Classification
Feb 24, 2023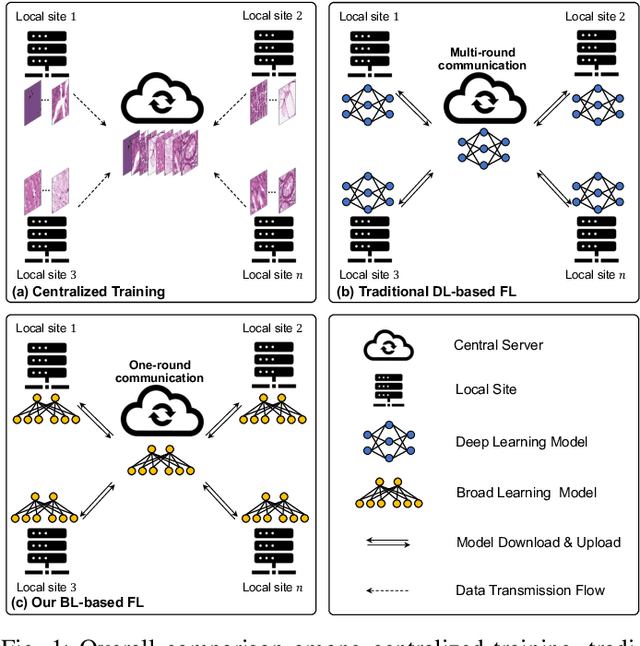
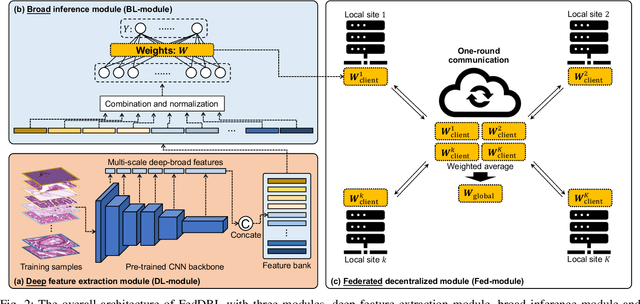
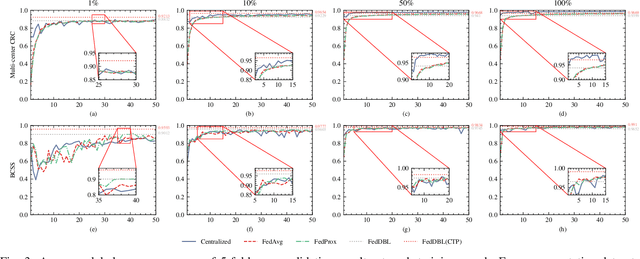

Histopathological tissue classification is a fundamental task in computational pathology. Deep learning-based models have achieved superior performance but centralized training with data centralization suffers from the privacy leakage problem. Federated learning (FL) can safeguard privacy by keeping training samples locally, but existing FL-based frameworks require a large number of well-annotated training samples and numerous rounds of communication which hinder their practicability in the real-world clinical scenario. In this paper, we propose a universal and lightweight federated learning framework, named Federated Deep-Broad Learning (FedDBL), to achieve superior classification performance with limited training samples and only one-round communication. By simply associating a pre-trained deep learning feature extractor, a fast and lightweight broad learning inference system and a classical federated aggregation approach, FedDBL can dramatically reduce data dependency and improve communication efficiency. Five-fold cross-validation demonstrates that FedDBL greatly outperforms the competitors with only one-round communication and limited training samples, while it even achieves comparable performance with the ones under multiple-round communications. Furthermore, due to the lightweight design and one-round communication, FedDBL reduces the communication burden from 4.6GB to only 276.5KB per client using the ResNet-50 backbone at 50-round training. Since no data or deep model sharing across different clients, the privacy issue is well-solved and the model security is guaranteed with no model inversion attack risk. Code is available at https://github.com/tianpeng-deng/FedDBL.
CKD-TransBTS: Clinical Knowledge-Driven Hybrid Transformer with Modality-Correlated Cross-Attention for Brain Tumor Segmentation
Jul 15, 2022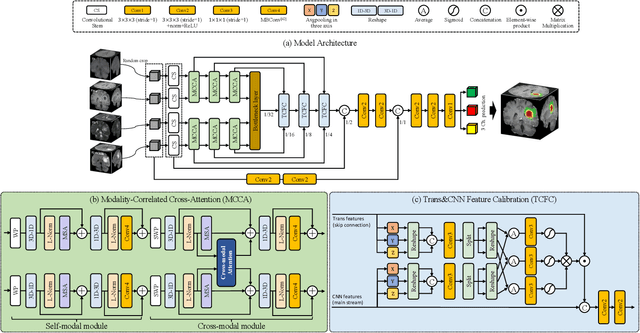
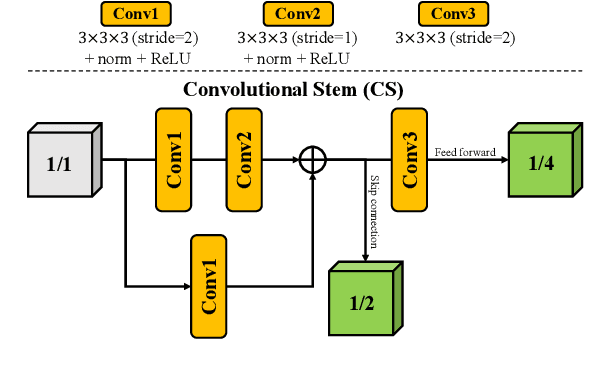
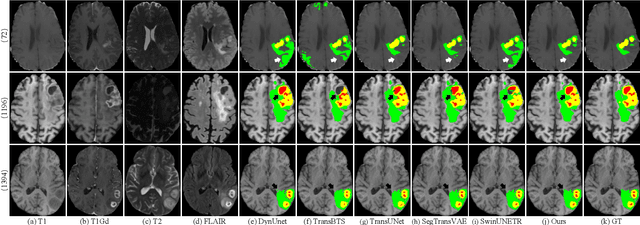
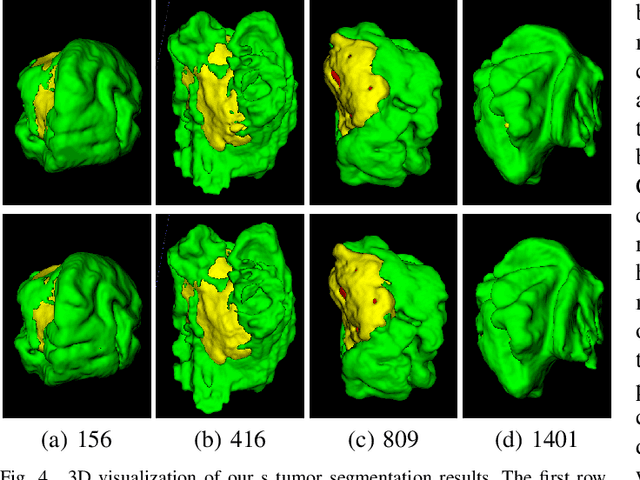
Brain tumor segmentation (BTS) in magnetic resonance image (MRI) is crucial for brain tumor diagnosis, cancer management and research purposes. With the great success of the ten-year BraTS challenges as well as the advances of CNN and Transformer algorithms, a lot of outstanding BTS models have been proposed to tackle the difficulties of BTS in different technical aspects. However, existing studies hardly consider how to fuse the multi-modality images in a reasonable manner. In this paper, we leverage the clinical knowledge of how radiologists diagnose brain tumors from multiple MRI modalities and propose a clinical knowledge-driven brain tumor segmentation model, called CKD-TransBTS. Instead of directly concatenating all the modalities, we re-organize the input modalities by separating them into two groups according to the imaging principle of MRI. A dual-branch hybrid encoder with the proposed modality-correlated cross-attention block (MCCA) is designed to extract the multi-modality image features. The proposed model inherits the strengths from both Transformer and CNN with the local feature representation ability for precise lesion boundaries and long-range feature extraction for 3D volumetric images. To bridge the gap between Transformer and CNN features, we propose a Trans&CNN Feature Calibration block (TCFC) in the decoder. We compare the proposed model with five CNN-based models and six transformer-based models on the BraTS 2021 challenge dataset. Extensive experiments demonstrate that the proposed model achieves state-of-the-art brain tumor segmentation performance compared with all the competitors.
HoVer-Trans: Anatomy-aware HoVer-Transformer for ROI-free Breast Cancer Diagnosis in Ultrasound Images
May 17, 2022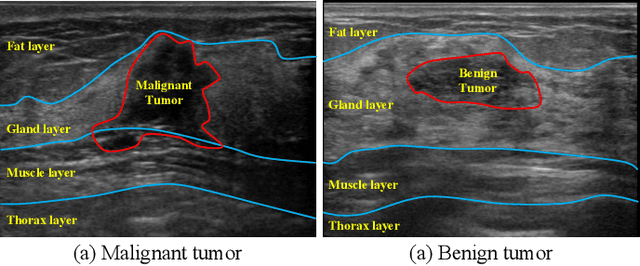
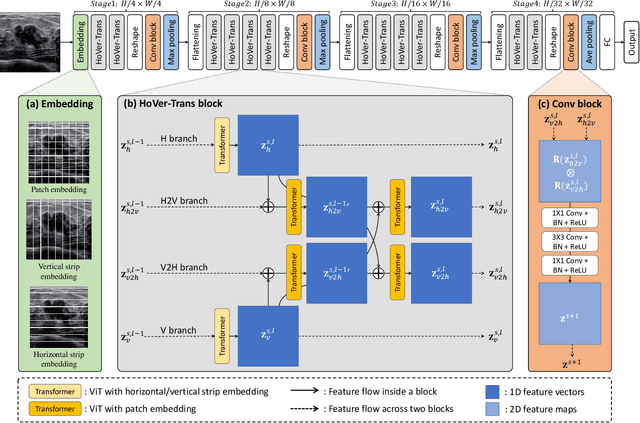

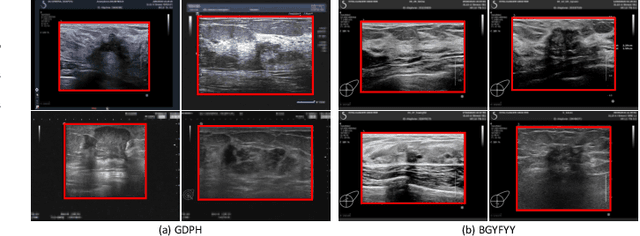
Ultrasonography is an important routine examination for breast cancer diagnosis, due to its non-invasive, radiation-free and low-cost properties. However, it is still not the first-line screening test for breast cancer due to its inherent limitations. It would be a tremendous success if we can precisely diagnose breast cancer by breast ultrasound images (BUS). Many learning-based computer-aided diagnostic methods have been proposed to achieve breast cancer diagnosis/lesion classification. However, most of them require a pre-define ROI and then classify the lesion inside the ROI. Conventional classification backbones, such as VGG16 and ResNet50, can achieve promising classification results with no ROI requirement. But these models lack interpretability, thus restricting their use in clinical practice. In this study, we propose a novel ROI-free model for breast cancer diagnosis in ultrasound images with interpretable feature representations. We leverage the anatomical prior knowledge that malignant and benign tumors have different spatial relationships between different tissue layers, and propose a HoVer-Transformer to formulate this prior knowledge. The proposed HoVer-Trans block extracts the inter- and intra-layer spatial information horizontally and vertically. We conduct and release an open dataset GDPH&GYFYY for breast cancer diagnosis in BUS. The proposed model is evaluated in three datasets by comparing with four CNN-based models and two vision transformer models via a five-fold cross validation. It achieves state-of-the-art classification performance with the best model interpretability.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022
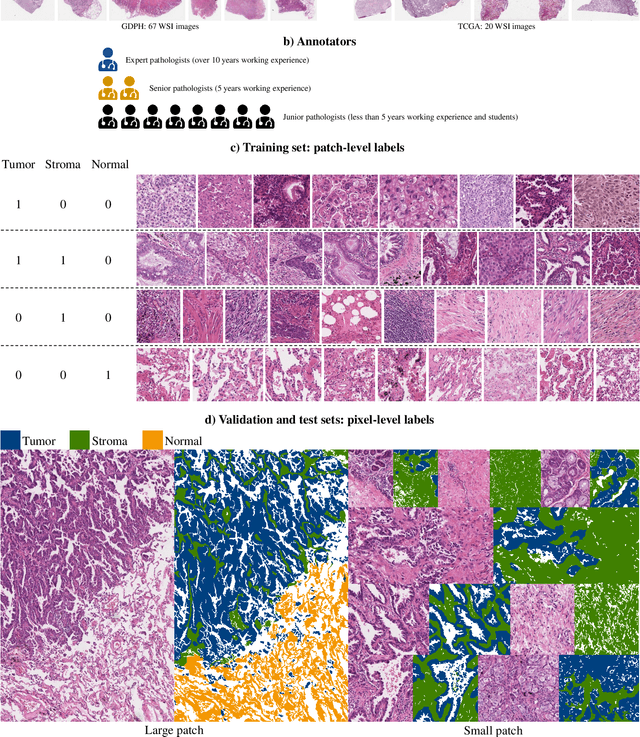
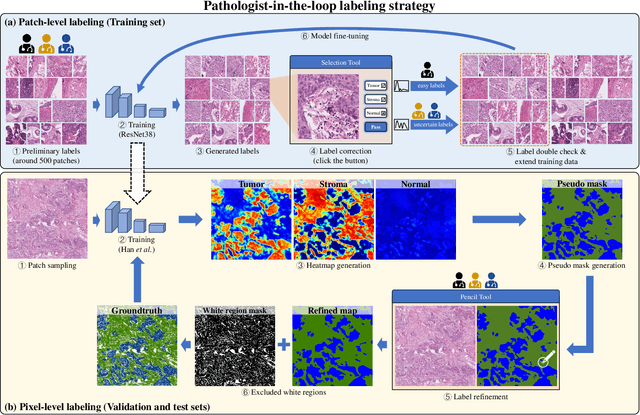
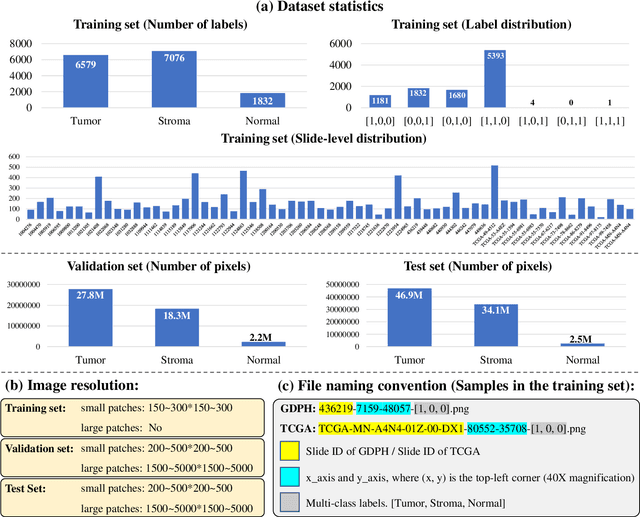
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
A Standardized Pipeline for Colon Nuclei Identification and Counting Challenge
Mar 20, 2022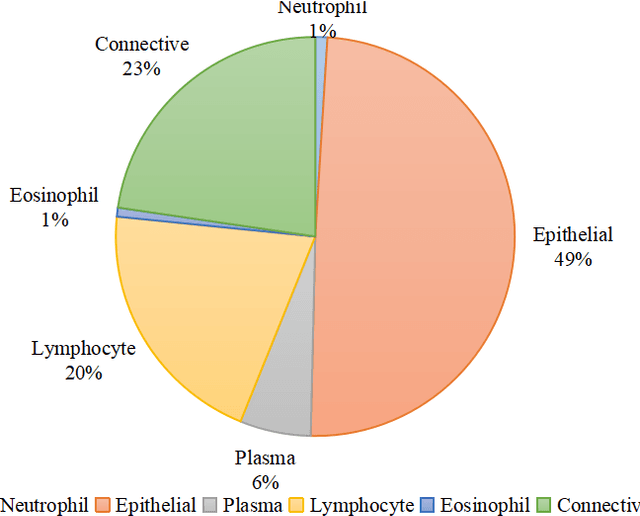
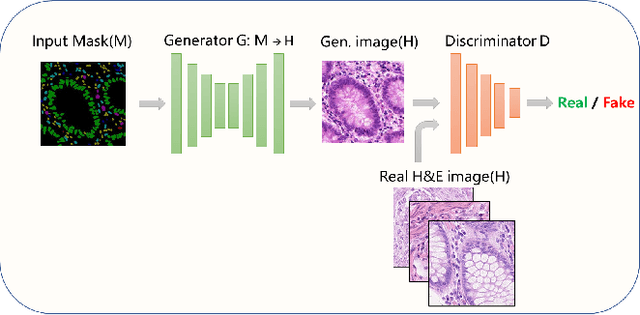

Nuclear segmentation and classification is an essential step for computational pathology. TIA lab from Warwick University organized a nuclear segmentation and classification challenge (CoNIC) for H&E stained histopathology images in colorectal cancer with two highly correlated tasks, nuclei segmentation and classification task and cellular composition task. There are a few obstacles we have to address in this challenge, 1) limited training samples, 2) color variation, 3) imbalanced annotations, 4) similar morphological appearance among classes. To deal with these challenges, we proposed a standardized pipeline for nuclear segmentation and classification by integrating several pluggable components. First, we built a GAN-based model to automatically generate pseudo images for data augmentation. Then we trained a self-supervised stain normalization model to solve the color variation problem. Next we constructed a baseline model HoVer-Net with cost-sensitive loss to encourage the model pay more attention on the minority classes. According to the results of the leaderboard, our proposed pipeline achieves 0.40665 mPQ+ (Rank 49th) and 0.62199 r2 (Rank 10th) in the preliminary test phase.
RestainNet: a self-supervised digital re-stainer for stain normalization
Feb 28, 2022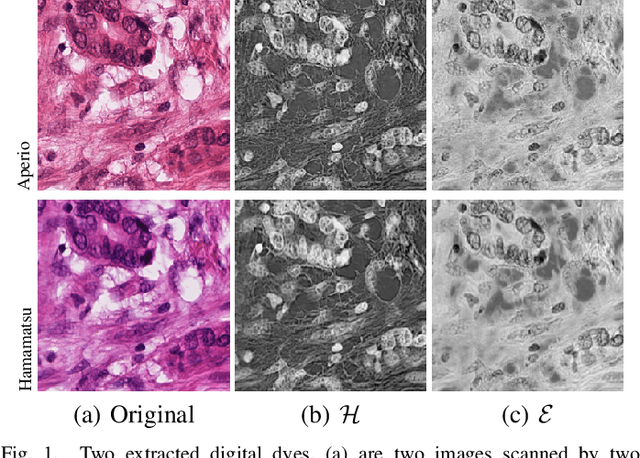
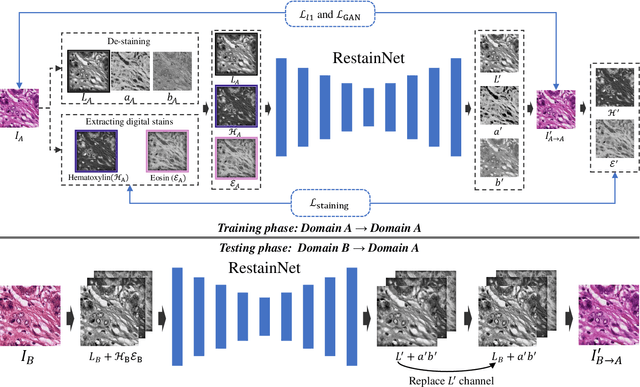
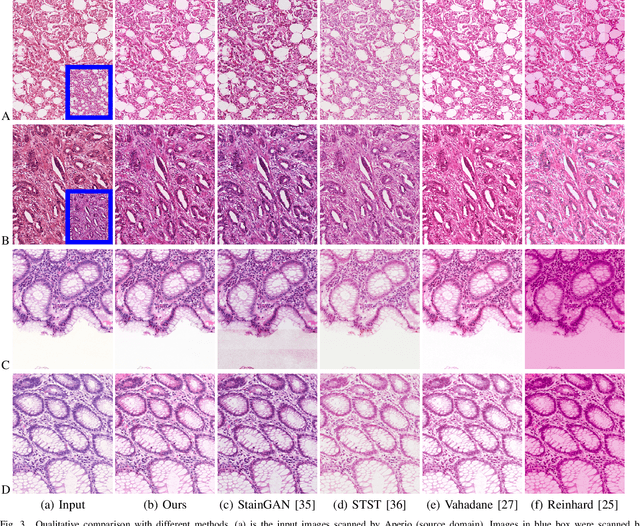

Color inconsistency is an inevitable challenge in computational pathology, which generally happens because of stain intensity variations or sections scanned by different scanners. It harms the pathological image analysis methods, especially the learning-based models. A series of approaches have been proposed for stain normalization. However, most of them are lack flexibility in practice. In this paper, we formulated stain normalization as a digital re-staining process and proposed a self-supervised learning model, which is called RestainNet. Our network is regarded as a digital restainer which learns how to re-stain an unstained (grayscale) image. Two digital stains, Hematoxylin (H) and Eosin (E) were extracted from the original image by Beer-Lambert's Law. We proposed a staining loss to maintain the correctness of stain intensity during the restaining process. Thanks to the self-supervised nature, paired training samples are no longer necessary, which demonstrates great flexibility in practical usage. Our RestainNet outperforms existing approaches and achieves state-of-the-art performance with regard to color correctness and structure preservation. We further conducted experiments on the segmentation and classification tasks and the proposed RestainNet achieved outstanding performance compared with SOTA methods. The self-supervised design allows the network to learn any staining style with no extra effort.
PDBL: Improving Histopathological Tissue Classification with Plug-and-Play Pyramidal Deep-Broad Learning
Nov 04, 2021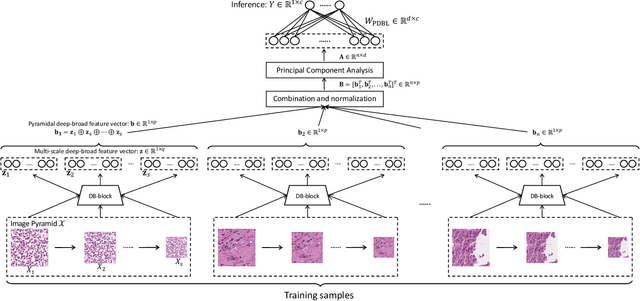
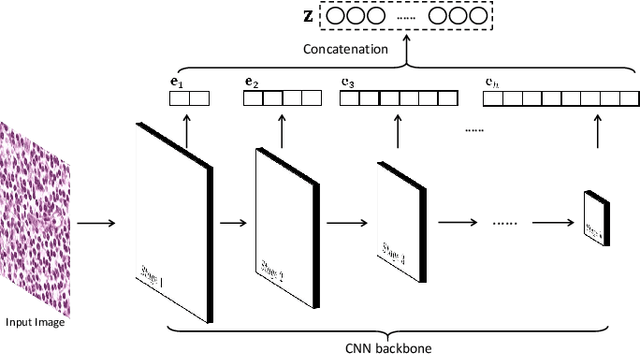
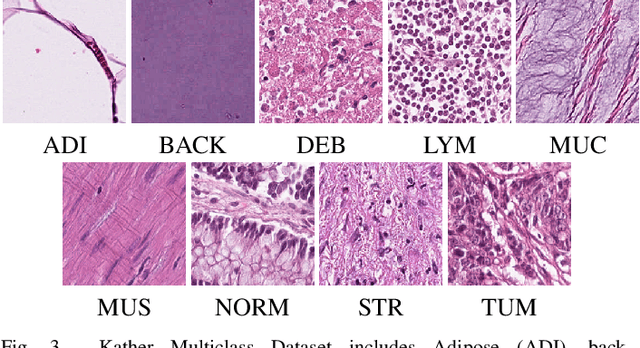
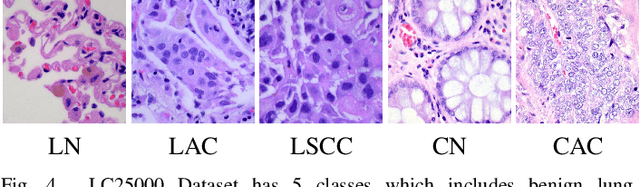
Histopathological tissue classification is a fundamental task in pathomics cancer research. Precisely differentiating different tissue types is a benefit for the downstream researches, like cancer diagnosis, prognosis and etc. Existing works mostly leverage the popular classification backbones in computer vision to achieve histopathological tissue classification. In this paper, we proposed a super lightweight plug-and-play module, named Pyramidal Deep-Broad Learning (PDBL), for any well-trained classification backbone to further improve the classification performance without a re-training burden. We mimic how pathologists observe pathology slides in different magnifications and construct an image pyramid for the input image in order to obtain the pyramidal contextual information. For each level in the pyramid, we extract the multi-scale deep-broad features by our proposed Deep-Broad block (DB-block). We equipped PDBL in three popular classification backbones, ShuffLeNetV2, EfficientNetb0, and ResNet50 to evaluate the effectiveness and efficiency of our proposed module on two datasets (Kather Multiclass Dataset and the LC25000 Dataset). Experimental results demonstrate the proposed PDBL can steadily improve the tissue-level classification performance for any CNN backbones, especially for the lightweight models when given a small among of training samples (less than 10%), which greatly saves the computational time and annotation efforts.