 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRMR: LLM-Driven Relational Multi-node Ranking for Lymph Node Metastasis Assessment in Rectal Cancer
Jul 15, 2025Accurate preoperative assessment of lymph node (LN) metastasis in rectal cancer guides treatment decisions, yet conventional MRI evaluation based on morphological criteria shows limited diagnostic performance. While some artificial intelligence models have been developed, they often operate as black boxes, lacking the interpretability needed for clinical trust. Moreover, these models typically evaluate nodes in isolation, overlooking the patient-level context. To address these limitations, we introduce LRMR, an LLM-Driven Relational Multi-node Ranking framework. This approach reframes the diagnostic task from a direct classification problem into a structured reasoning and ranking process. The LRMR framework operates in two stages. First, a multimodal large language model (LLM) analyzes a composite montage image of all LNs from a patient, generating a structured report that details ten distinct radiological features. Second, a text-based LLM performs pairwise comparisons of these reports between different patients, establishing a relative risk ranking based on the severity and number of adverse features. We evaluated our method on a retrospective cohort of 117 rectal cancer patients. LRMR achieved an area under the curve (AUC) of 0.7917 and an F1-score of 0.7200, outperforming a range of deep learning baselines, including ResNet50 (AUC 0.7708). Ablation studies confirmed the value of our two main contributions: removing the relational ranking stage or the structured prompting stage led to a significant performance drop, with AUCs falling to 0.6875 and 0.6458, respectively. Our work demonstrates that decoupling visual perception from cognitive reasoning through a two-stage LLM framework offers a powerful, interpretable, and effective new paradigm for assessing lymph node metastasis in rectal cancer.
iMD4GC: Incomplete Multimodal Data Integration to Advance Precise Treatment Response Prediction and Survival Analysis for Gastric Cancer
Apr 01, 2024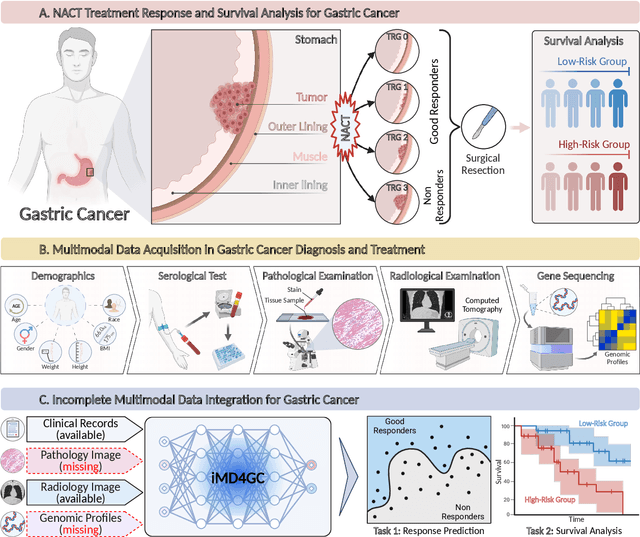
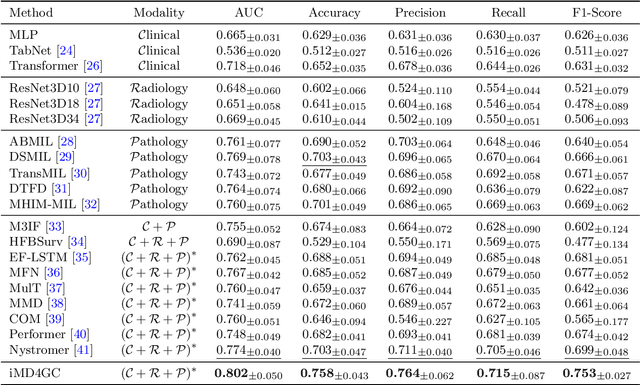
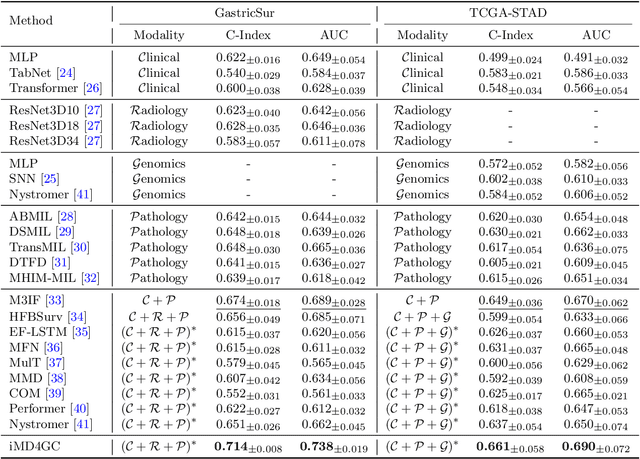
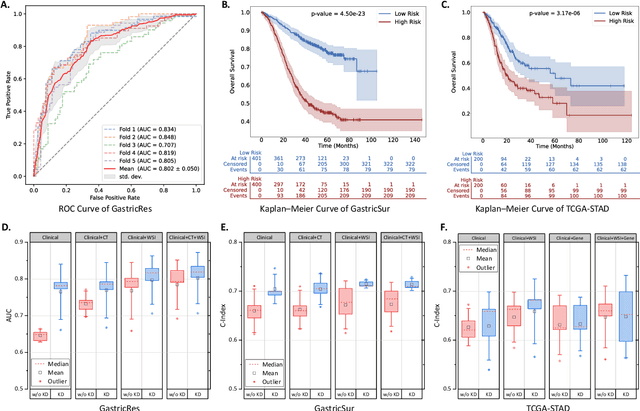
Gastric cancer (GC) is a prevalent malignancy worldwide, ranking as the fifth most common cancer with over 1 million new cases and 700 thousand deaths in 2020. Locally advanced gastric cancer (LAGC) accounts for approximately two-thirds of GC diagnoses, and neoadjuvant chemotherapy (NACT) has emerged as the standard treatment for LAGC. However, the effectiveness of NACT varies significantly among patients, with a considerable subset displaying treatment resistance. Ineffective NACT not only leads to adverse effects but also misses the optimal therapeutic window, resulting in lower survival rate. However, existing multimodal learning methods assume the availability of all modalities for each patient, which does not align with the reality of clinical practice. The limited availability of modalities for each patient would cause information loss, adversely affecting predictive accuracy. In this study, we propose an incomplete multimodal data integration framework for GC (iMD4GC) to address the challenges posed by incomplete multimodal data, enabling precise response prediction and survival analysis. Specifically, iMD4GC incorporates unimodal attention layers for each modality to capture intra-modal information. Subsequently, the cross-modal interaction layers explore potential inter-modal interactions and capture complementary information across modalities, thereby enabling information compensation for missing modalities. To evaluate iMD4GC, we collected three multimodal datasets for GC study: GastricRes (698 cases) for response prediction, GastricSur (801 cases) for survival analysis, and TCGA-STAD (400 cases) for survival analysis. The scale of our datasets is significantly larger than previous studies. The iMD4GC achieved impressive performance with an 80.2% AUC on GastricRes, 71.4% C-index on GastricSur, and 66.1% C-index on TCGA-STAD, significantly surpassing other compared methods.
HoVer-Trans: Anatomy-aware HoVer-Transformer for ROI-free Breast Cancer Diagnosis in Ultrasound Images
May 17, 2022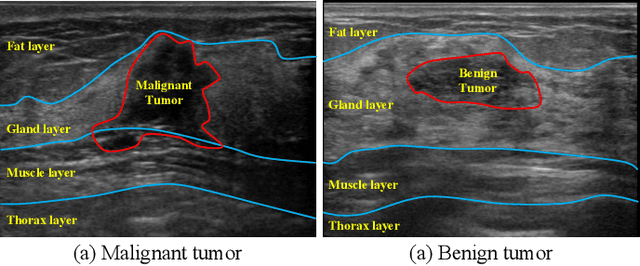
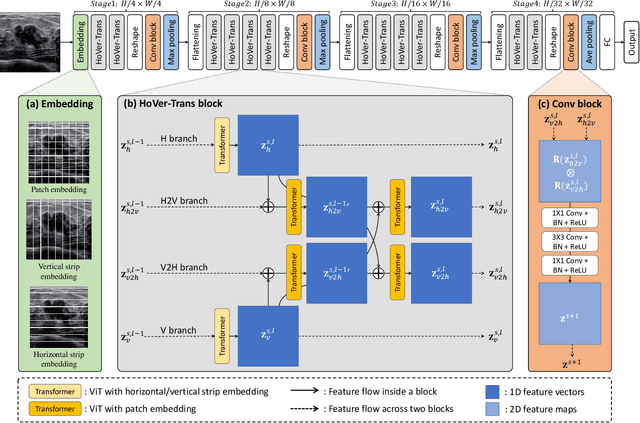

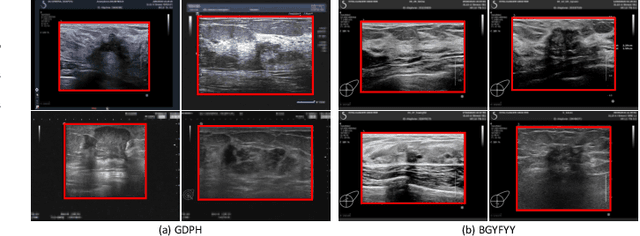
Ultrasonography is an important routine examination for breast cancer diagnosis, due to its non-invasive, radiation-free and low-cost properties. However, it is still not the first-line screening test for breast cancer due to its inherent limitations. It would be a tremendous success if we can precisely diagnose breast cancer by breast ultrasound images (BUS). Many learning-based computer-aided diagnostic methods have been proposed to achieve breast cancer diagnosis/lesion classification. However, most of them require a pre-define ROI and then classify the lesion inside the ROI. Conventional classification backbones, such as VGG16 and ResNet50, can achieve promising classification results with no ROI requirement. But these models lack interpretability, thus restricting their use in clinical practice. In this study, we propose a novel ROI-free model for breast cancer diagnosis in ultrasound images with interpretable feature representations. We leverage the anatomical prior knowledge that malignant and benign tumors have different spatial relationships between different tissue layers, and propose a HoVer-Transformer to formulate this prior knowledge. The proposed HoVer-Trans block extracts the inter- and intra-layer spatial information horizontally and vertically. We conduct and release an open dataset GDPH&GYFYY for breast cancer diagnosis in BUS. The proposed model is evaluated in three datasets by comparing with four CNN-based models and two vision transformer models via a five-fold cross validation. It achieves state-of-the-art classification performance with the best model interpretability.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022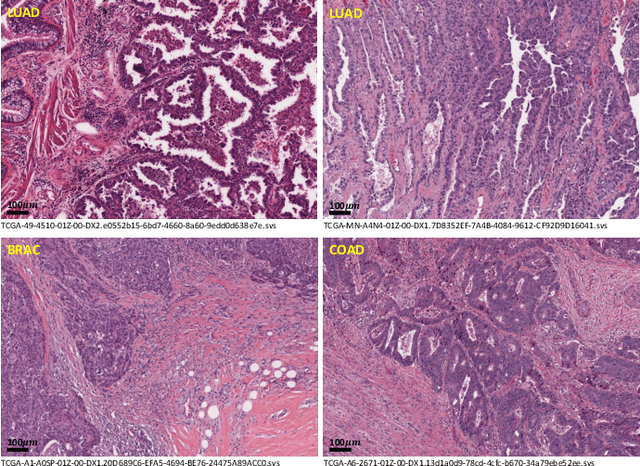
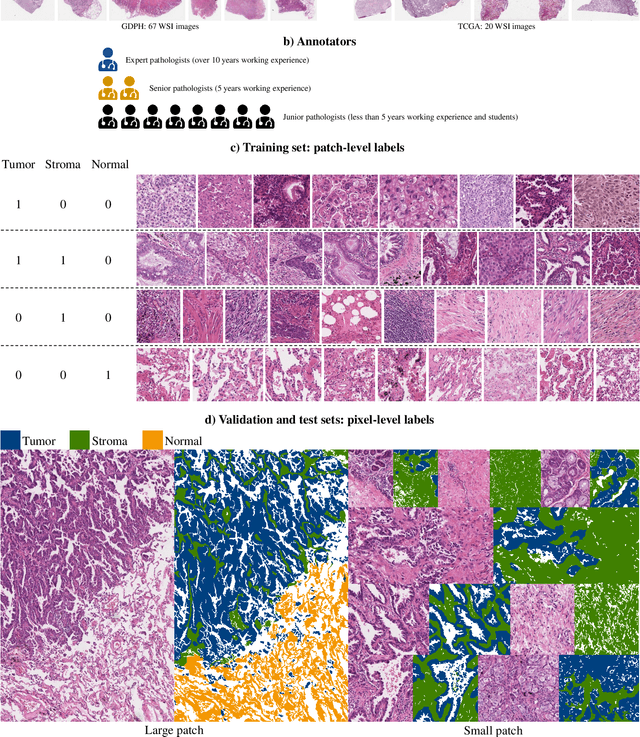
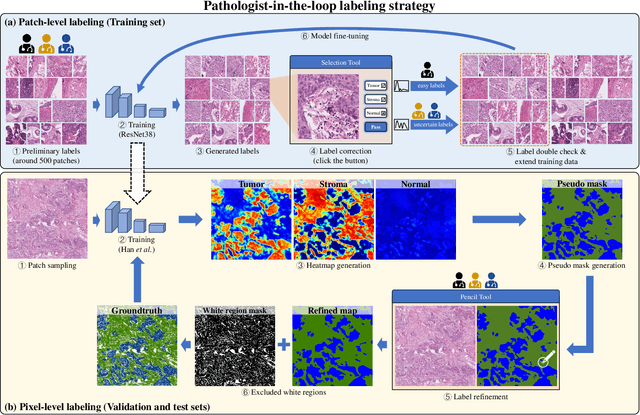
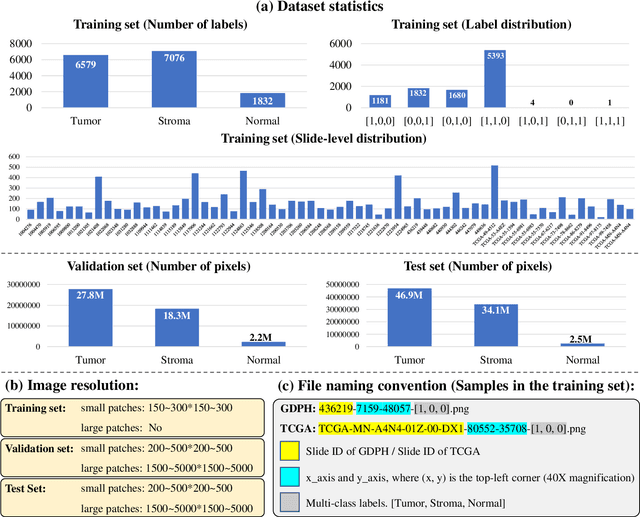
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
PDBL: Improving Histopathological Tissue Classification with Plug-and-Play Pyramidal Deep-Broad Learning
Nov 04, 2021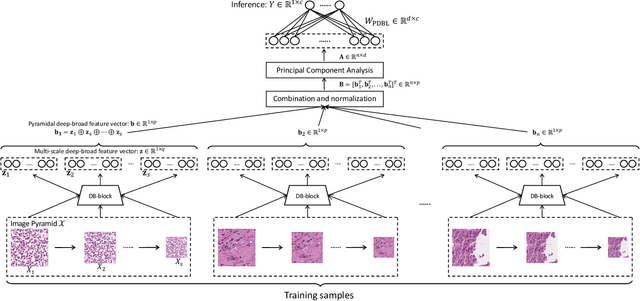
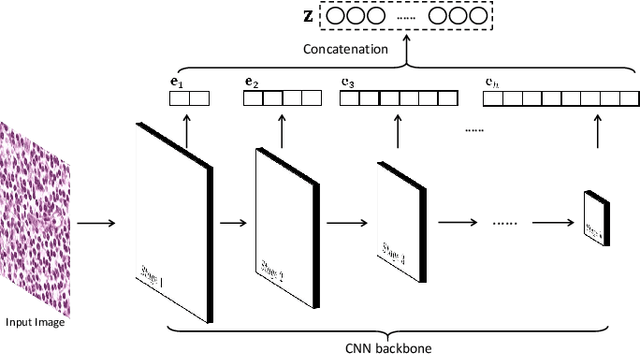
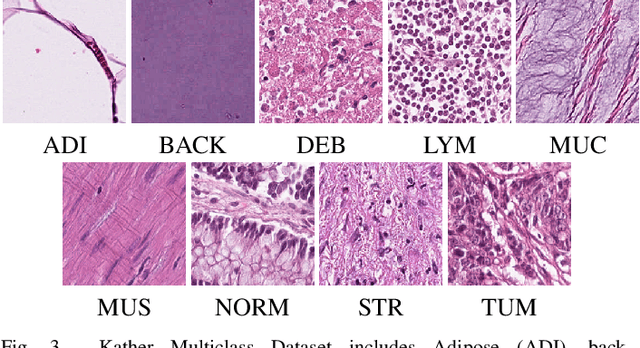
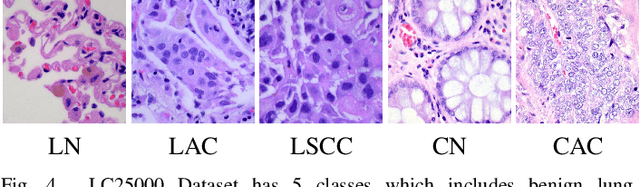
Histopathological tissue classification is a fundamental task in pathomics cancer research. Precisely differentiating different tissue types is a benefit for the downstream researches, like cancer diagnosis, prognosis and etc. Existing works mostly leverage the popular classification backbones in computer vision to achieve histopathological tissue classification. In this paper, we proposed a super lightweight plug-and-play module, named Pyramidal Deep-Broad Learning (PDBL), for any well-trained classification backbone to further improve the classification performance without a re-training burden. We mimic how pathologists observe pathology slides in different magnifications and construct an image pyramid for the input image in order to obtain the pyramidal contextual information. For each level in the pyramid, we extract the multi-scale deep-broad features by our proposed Deep-Broad block (DB-block). We equipped PDBL in three popular classification backbones, ShuffLeNetV2, EfficientNetb0, and ResNet50 to evaluate the effectiveness and efficiency of our proposed module on two datasets (Kather Multiclass Dataset and the LC25000 Dataset). Experimental results demonstrate the proposed PDBL can steadily improve the tissue-level classification performance for any CNN backbones, especially for the lightweight models when given a small among of training samples (less than 10%), which greatly saves the computational time and annotation efforts.