 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPS: Information Elicitation with Reinforcement Prompt Selection
Apr 15, 2026Large language models (LLMs) have shown remarkable capabilities in dialogue generation and reasoning, yet their effectiveness in eliciting user-known but concealed information in open-ended conversations remains limited. In many interactive AI applications, such as personal assistants, tutoring systems, and legal or clinical support, users often withhold sensitive or uncertain information due to privacy concerns, ambiguity, or social hesitation. This makes it challenging for LLMs to gather complete and contextually relevant inputs. In this work, we define the problem of information elicitation in open-ended dialogue settings and propose Reinforcement Prompt Selection (RPS), a lightweight reinforcement learning framework that formulates prompt selection as a sequential decision-making problem. To analyze this problem in a controlled setting, we design a synthetic experiment, where a reinforcement learning agent outperforms a random query baseline, illustrating the potential of policy-based approaches for adaptive information elicitation. Building on this insight, RPS learns a policy over a pool of prompts to adaptively elicit concealed or incompletely expressed information from users through dialogue. We also introduce IELegal, a new benchmark dataset constructed from real legal case documents, which simulates dialogue-based information elicitation tasks aimed at uncovering case-relevant facts. In this setting, RPS outperforms static prompt baselines, demonstrating the effectiveness of adaptive prompt selection for eliciting critical information in LLM-driven dialogue systems.
Transferable Graph Condensation from the Causal Perspective
Jan 29, 2026The increasing scale of graph datasets has significantly improved the performance of graph representation learning methods, but it has also introduced substantial training challenges. Graph dataset condensation techniques have emerged to compress large datasets into smaller yet information-rich datasets, while maintaining similar test performance. However, these methods strictly require downstream applications to match the original dataset and task, which often fails in cross-task and cross-domain scenarios. To address these challenges, we propose a novel causal-invariance-based and transferable graph dataset condensation method, named \textbf{TGCC}, providing effective and transferable condensed datasets. Specifically, to preserve domain-invariant knowledge, we first extract domain causal-invariant features from the spatial domain of the graph using causal interventions. Then, to fully capture the structural and feature information of the original graph, we perform enhanced condensation operations. Finally, through spectral-domain enhanced contrastive learning, we inject the causal-invariant features into the condensed graph, ensuring that the compressed graph retains the causal information of the original graph. Experimental results on five public datasets and our novel \textbf{FinReport} dataset demonstrate that TGCC achieves up to a 13.41\% improvement in cross-task and cross-domain complex scenarios compared to existing methods, and achieves state-of-the-art performance on 5 out of 6 datasets in the single dataset and task scenario.
When Helpers Become Hazards: A Benchmark for Analyzing Multimodal LLM-Powered Safety in Daily Life
Jan 07, 2026As Multimodal Large Language Models (MLLMs) become an indispensable assistant in human life, the unsafe content generated by MLLMs poses a danger to human behavior, perpetually overhanging human society like a sword of Damocles. To investigate and evaluate the safety impact of MLLMs responses on human behavior in daily life, we introduce SaLAD, a multimodal safety benchmark which contains 2,013 real-world image-text samples across 10 common categories, with a balanced design covering both unsafe scenarios and cases of oversensitivity. It emphasizes realistic risk exposure, authentic visual inputs, and fine-grained cross-modal reasoning, ensuring that safety risks cannot be inferred from text alone. We further propose a safety-warning-based evaluation framework that encourages models to provide clear and informative safety warnings, rather than generic refusals. Results on 18 MLLMs demonstrate that the top-performing models achieve a safe response rate of only 57.2% on unsafe queries. Moreover, even popular safety alignment methods limit effectiveness of the models in our scenario, revealing the vulnerabilities of current MLLMs in identifying dangerous behaviors in daily life. Our dataset is available at https://github.com/xinyuelou/SaLAD.
Pegasus: A Universal Framework for Scalable Deep Learning Inference on the Dataplane
Jun 06, 2025The paradigm of Intelligent DataPlane (IDP) embeds deep learning (DL) models on the network dataplane to enable intelligent traffic analysis at line-speed. However, the current use of the match-action table (MAT) abstraction on the dataplane is misaligned with DL inference, leading to several key limitations, including accuracy degradation, limited scale, and lack of generality. This paper proposes Pegasus to address these limitations. Pegasus translates DL operations into three dataplane-oriented primitives to achieve generality: Partition, Map, and SumReduce. Specifically, Partition "divides" high-dimensional features into multiple low-dimensional vectors, making them more suitable for the dataplane; Map "conquers" computations on the low-dimensional vectors in parallel with the technique of fuzzy matching, while SumReduce "combines" the computation results. Additionally, Pegasus employs Primitive Fusion to merge computations, improving scalability. Finally, Pegasus adopts full precision weights with fixed-point activations to improve accuracy. Our implementation on a P4 switch demonstrates that Pegasus can effectively support various types of DL models, including Multi-Layer Perceptron (MLP), Recurrent Neural Network (RNN), Convolutional Neural Network (CNN), and AutoEncoder models on the dataplane. Meanwhile, Pegasus outperforms state-of-the-art approaches with an average accuracy improvement of up to 22.8%, along with up to 248x larger model size and 212x larger input scale.
Walking in Others' Shoes: How Perspective-Taking Guides Large Language Models in Reducing Toxicity and Bias
Jul 22, 2024


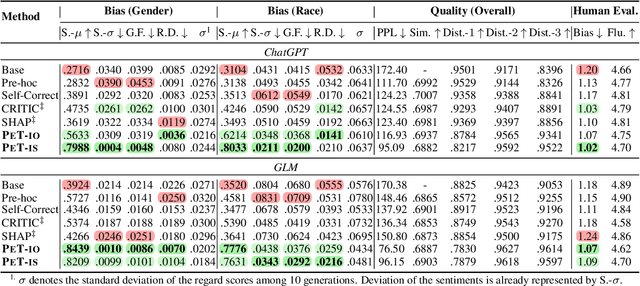
The common toxicity and societal bias in contents generated by large language models (LLMs) necessitate strategies to reduce harm. Present solutions often demand white-box access to the model or substantial training, which is impractical for cutting-edge commercial LLMs. Moreover, prevailing prompting methods depend on external tool feedback and fail to simultaneously lessen toxicity and bias. Motivated by social psychology principles, we propose a novel strategy named \textbf{perspective-taking prompting (\textsc{PeT})} that inspires LLMs to integrate diverse human perspectives and self-regulate their responses. This self-correction mechanism can significantly diminish toxicity (up to $89\%$) and bias (up to $73\%$) in LLMs' responses. Rigorous evaluations and ablation studies are conducted on two commercial LLMs (ChatGPT and GLM) and three open-source LLMs, revealing \textsc{PeT}'s superiority in producing less harmful responses, outperforming five strong baselines.
Differentially Private Learning with Per-Sample Adaptive Clipping
Dec 01, 2022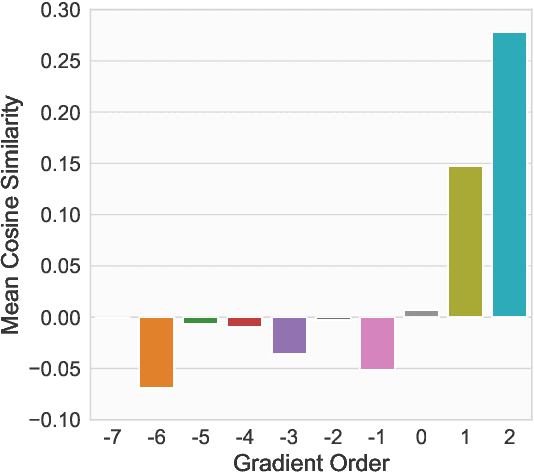

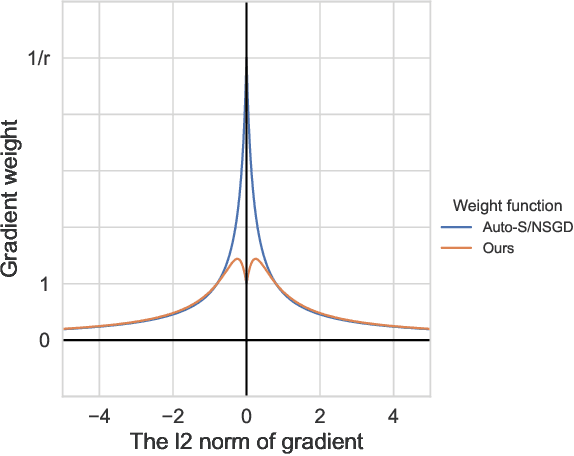
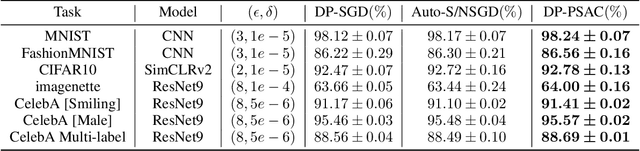
Privacy in AI remains a topic that draws attention from researchers and the general public in recent years. As one way to implement privacy-preserving AI, differentially private learning is a framework that enables AI models to use differential privacy (DP). To achieve DP in the learning process, existing algorithms typically limit the magnitude of gradients with a constant clipping, which requires carefully tuned due to its significant impact on model performance. As a solution to this issue, latest works NSGD and Auto-S innovatively propose to use normalization instead of clipping to avoid hyperparameter tuning. However, normalization-based approaches like NSGD and Auto-S rely on a monotonic weight function, which imposes excessive weight on small gradient samples and introduces extra deviation to the update. In this paper, we propose a Differentially Private Per-Sample Adaptive Clipping (DP-PSAC) algorithm based on a non-monotonic adaptive weight function, which guarantees privacy without the typical hyperparameter tuning process of using a constant clipping while significantly reducing the deviation between the update and true batch-averaged gradient. We provide a rigorous theoretical convergence analysis and show that with convergence rate at the same order, the proposed algorithm achieves a lower non-vanishing bound, which is maintained over training iterations, compared with NSGD/Auto-S. In addition, through extensive experimental evaluation, we show that DP-PSAC outperforms or matches the state-of-the-art methods on multiple main-stream vision and language tasks.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022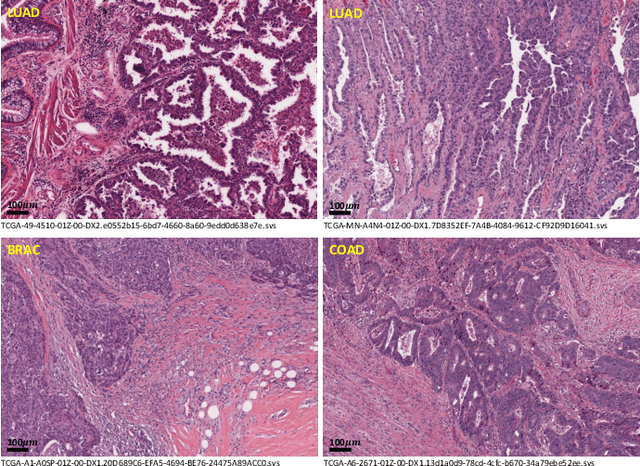
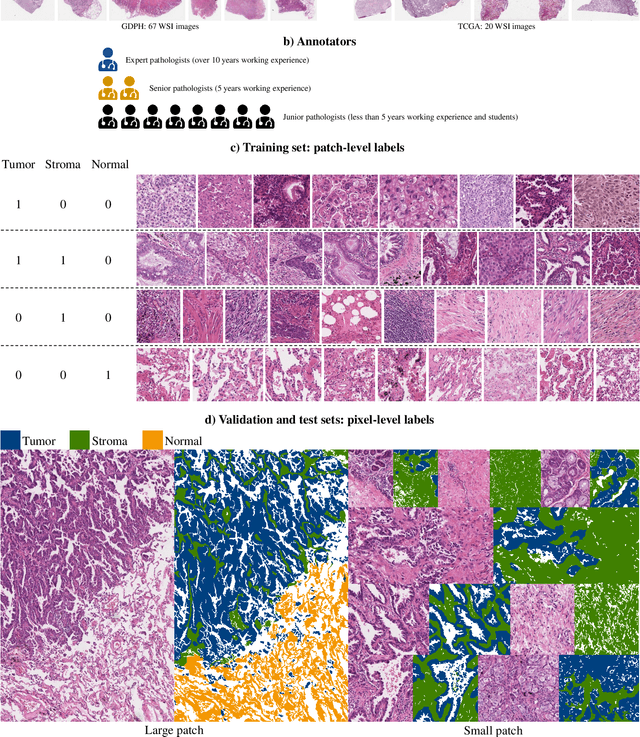
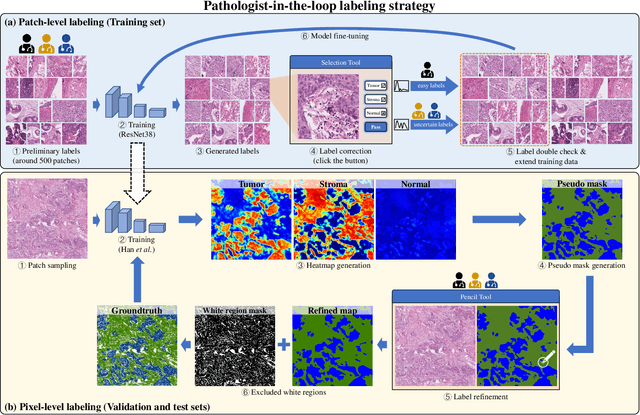
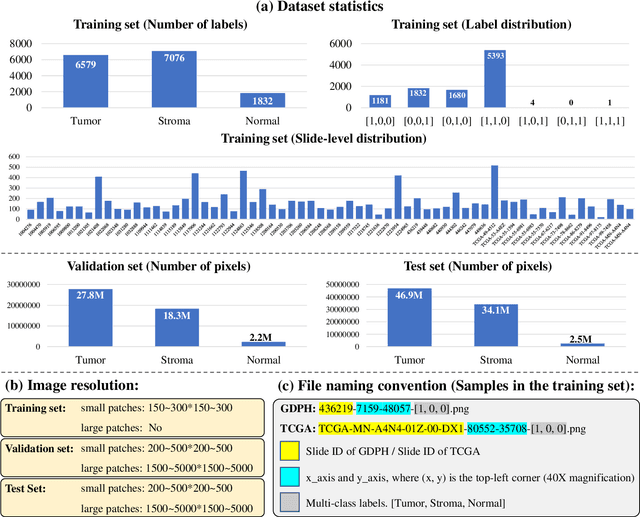
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
Multi-Layer Pseudo-Supervision for Histopathology Tissue Semantic Segmentation using Patch-level Classification Labels
Oct 14, 2021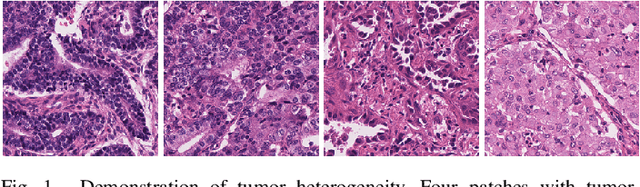
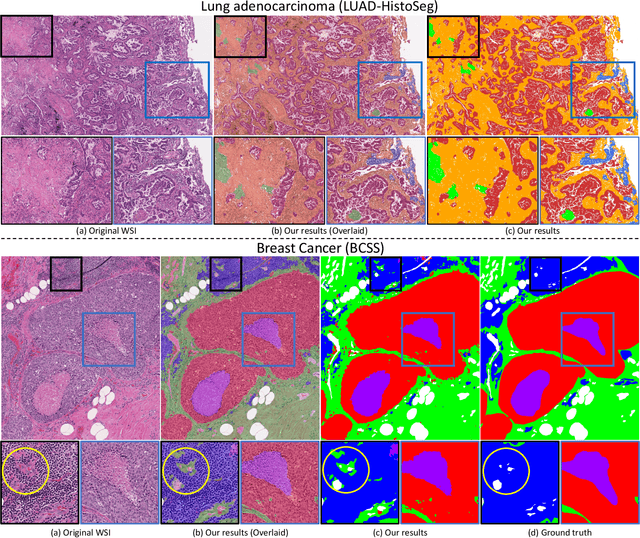
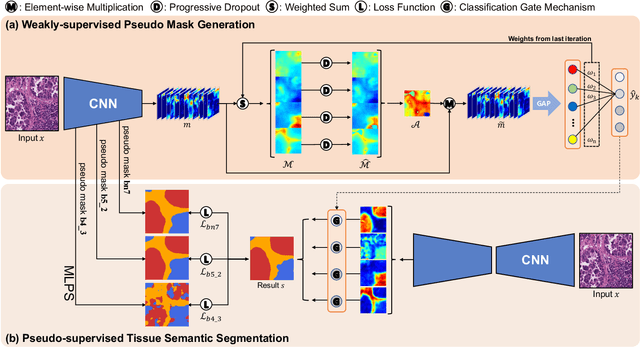
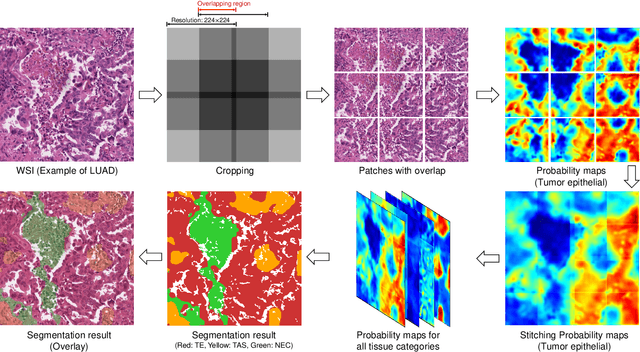
Tissue-level semantic segmentation is a vital step in computational pathology. Fully-supervised models have already achieved outstanding performance with dense pixel-level annotations. However, drawing such labels on the giga-pixel whole slide images is extremely expensive and time-consuming. In this paper, we use only patch-level classification labels to achieve tissue semantic segmentation on histopathology images, finally reducing the annotation efforts. We proposed a two-step model including a classification and a segmentation phases. In the classification phase, we proposed a CAM-based model to generate pseudo masks by patch-level labels. In the segmentation phase, we achieved tissue semantic segmentation by our proposed Multi-Layer Pseudo-Supervision. Several technical novelties have been proposed to reduce the information gap between pixel-level and patch-level annotations. As a part of this paper, we introduced a new weakly-supervised semantic segmentation (WSSS) dataset for lung adenocarcinoma (LUAD-HistoSeg). We conducted several experiments to evaluate our proposed model on two datasets. Our proposed model outperforms two state-of-the-art WSSS approaches. Note that we can achieve comparable quantitative and qualitative results with the fully-supervised model, with only around a 2\% gap for MIoU and FwIoU. By comparing with manual labeling, our model can greatly save the annotation time from hours to minutes. The source code is available at: \url{https://github.com/ChuHan89/WSSS-Tissue}.