 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
May 12, 2026Large language models have achieved remarkable capabilities across diverse tasks, yet their internal decision-making processes remain largely opaque, limiting our ability to inspect, control, and systematically improve them. This opacity motivates a growing body of research in mechanistic interpretability, with sparse autoencoders (SAEs) emerging as one of the most promising tools for decomposing model activations into sparse, interpretable feature representations. We introduce Qwen-Scope, an open-source suite of SAEs built on the Qwen model family, comprising 14 groups of SAEs across 7 model variants from the Qwen3 and Qwen3.5 series, covering both dense and mixture-of-expert architectures. Built on top of these SAEs, we show that SAEs can go beyond post-hoc analysis to serve as practical interfaces for model development along four directions: (i) inference-time steering, where SAE feature directions control language, concepts, and preferences without modifying model weights; (ii) evaluation analysis, where activated SAE features provide a representation-level proxy for benchmark redundancy and capability coverage; (iii) data-centric workflows, where SAE features support multilingual toxicity classification and safety-oriented data synthesis; and (iv) post-training optimization, where SAE-derived signals are incorporated into supervised fine-tuning and reinforcement learning objectives to mitigate undesirable behaviors such as code-switching and repetition. Together, these results demonstrate that SAEs can serve not only as post-hoc analysis tools, but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models. By open-sourcing Qwen-Scope, we aim to support mechanistic research and accelerate practical workflows that connect model internals to downstream behavior.
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Jun 05, 2025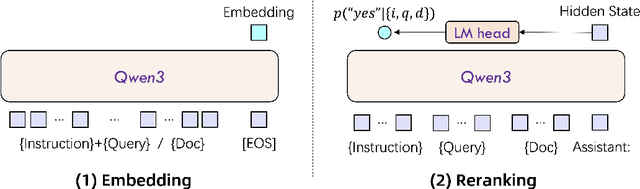
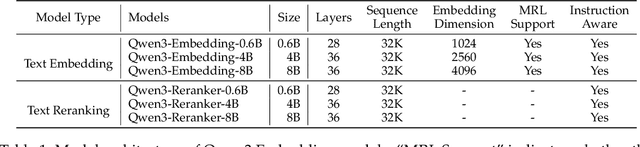

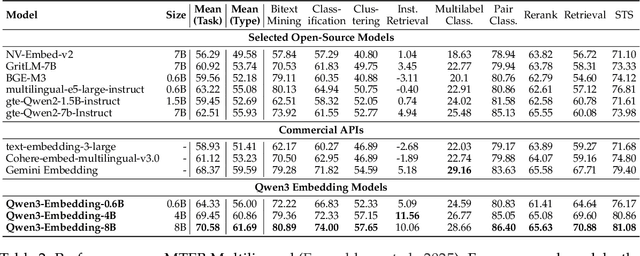
In this work, we introduce the Qwen3 Embedding series, a significant advancement over its predecessor, the GTE-Qwen series, in text embedding and reranking capabilities, built upon the Qwen3 foundation models. Leveraging the Qwen3 LLMs' robust capabilities in multilingual text understanding and generation, our innovative multi-stage training pipeline combines large-scale unsupervised pre-training with supervised fine-tuning on high-quality datasets. Effective model merging strategies further ensure the robustness and adaptability of the Qwen3 Embedding series. During the training process, the Qwen3 LLMs serve not only as backbone models but also play a crucial role in synthesizing high-quality, rich, and diverse training data across multiple domains and languages, thus enhancing the training pipeline. The Qwen3 Embedding series offers a spectrum of model sizes (0.6B, 4B, 8B) for both embedding and reranking tasks, addressing diverse deployment scenarios where users can optimize for either efficiency or effectiveness. Empirical evaluations demonstrate that the Qwen3 Embedding series achieves state-of-the-art results across diverse benchmarks. Notably, it excels on the multilingual evaluation benchmark MTEB for text embedding, as well as in various retrieval tasks, including code retrieval, cross-lingual retrieval and multilingual retrieval. To facilitate reproducibility and promote community-driven research and development, the Qwen3 Embedding models are publicly available under the Apache 2.0 license.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Enhancing LLM Language Adaption through Cross-lingual In-Context Pre-training
Apr 29, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite English-dominated pre-training, attributed to cross-lingual mechanisms during pre-training. Existing methods for enhancing cross-lingual transfer remain constrained by parallel resources, suffering from limited linguistic and domain coverage. We propose Cross-lingual In-context Pre-training (CrossIC-PT), a simple and scalable approach that enhances cross-lingual transfer by leveraging semantically related bilingual texts via simple next-word prediction. We construct CrossIC-PT samples by interleaving semantic-related bilingual Wikipedia documents into a single context window. To access window size constraints, we implement a systematic segmentation policy to split long bilingual document pairs into chunks while adjusting the sliding window mechanism to preserve contextual coherence. We further extend data availability through a semantic retrieval framework to construct CrossIC-PT samples from web-crawled corpus. Experimental results demonstrate that CrossIC-PT improves multilingual performance on three models (Llama-3.1-8B, Qwen2.5-7B, and Qwen2.5-1.5B) across six target languages, yielding performance gains of 3.79%, 3.99%, and 1.95%, respectively, with additional improvements after data augmentation.
Qwen2.5 Technical Report
Dec 19, 2024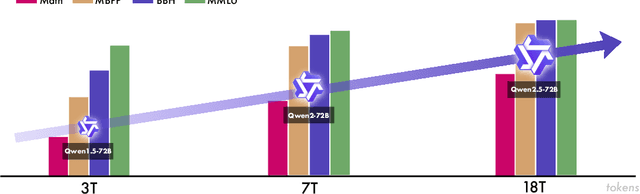

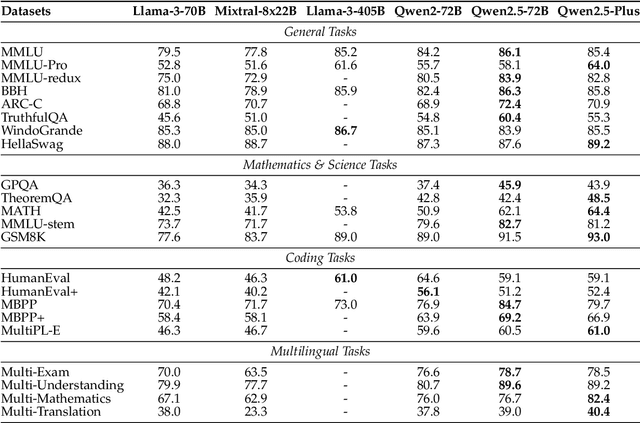
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
Jul 29, 2024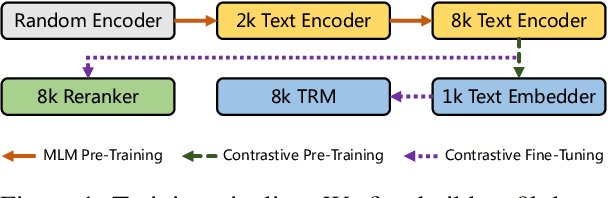

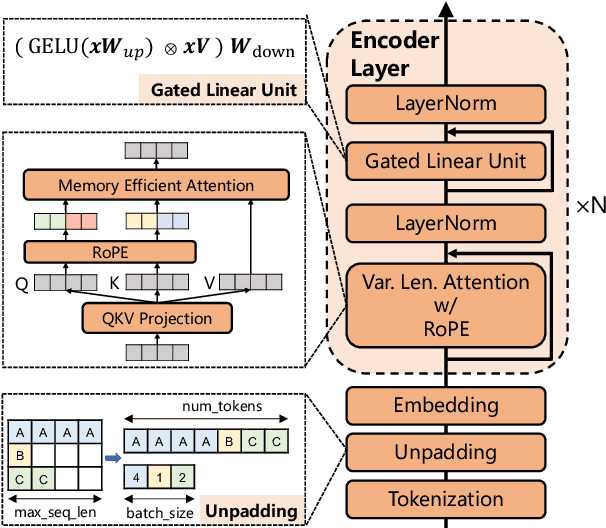
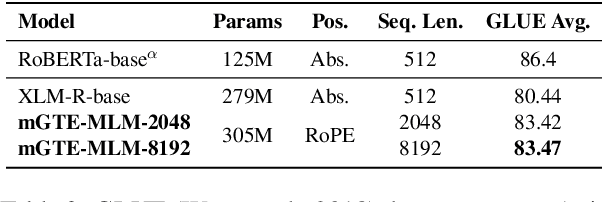
We present systematic efforts in building long-context multilingual text representation model (TRM) and reranker from scratch for text retrieval. We first introduce a text encoder (base size) enhanced with RoPE and unpadding, pre-trained in a native 8192-token context (longer than 512 of previous multilingual encoders). Then we construct a hybrid TRM and a cross-encoder reranker by contrastive learning. Evaluations show that our text encoder outperforms the same-sized previous state-of-the-art XLM-R. Meanwhile, our TRM and reranker match the performance of large-sized state-of-the-art BGE-M3 models and achieve better results on long-context retrieval benchmarks. Further analysis demonstrate that our proposed models exhibit higher efficiency during both training and inference. We believe their efficiency and effectiveness could benefit various researches and industrial applications.
Qwen2 Technical Report
Jul 16, 2024
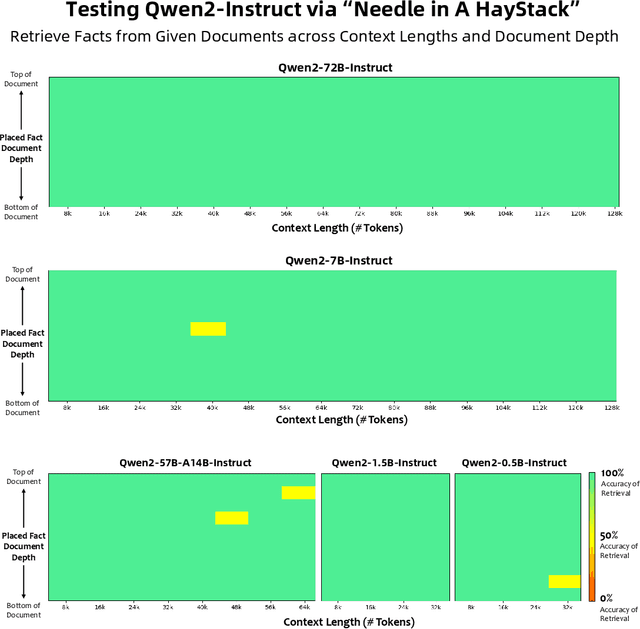
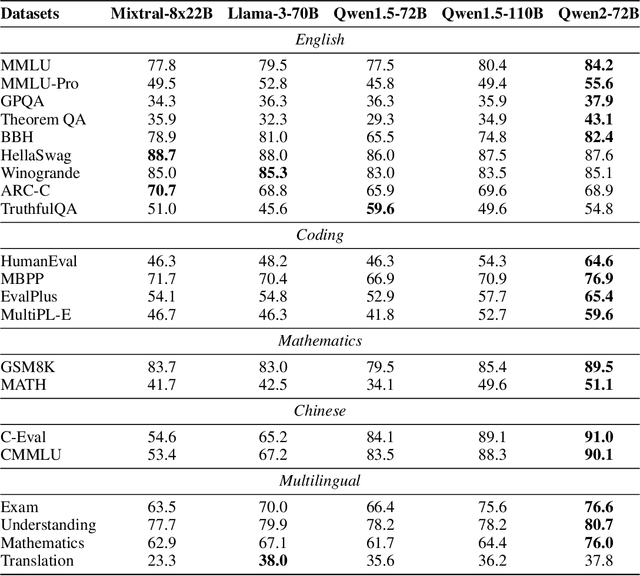
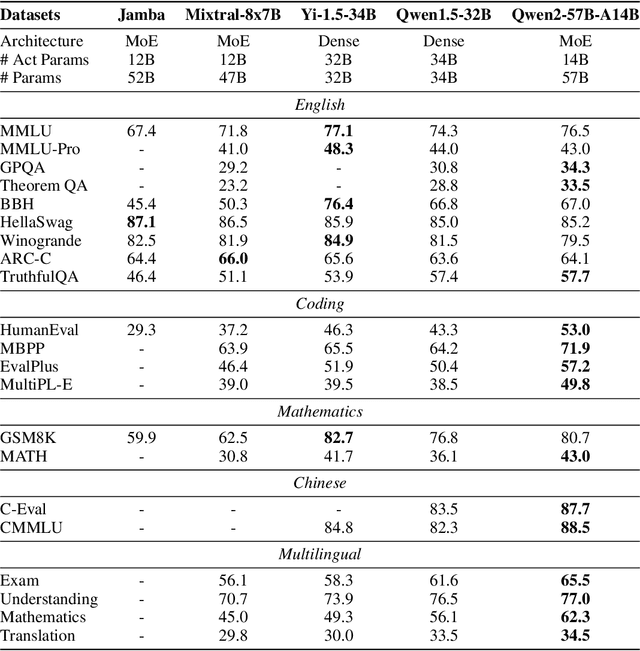
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
PolyLM: An Open Source Polyglot Large Language Model
Jul 12, 2023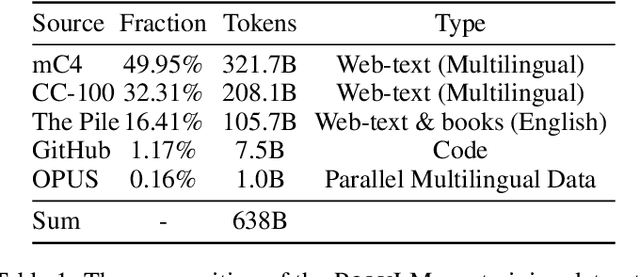
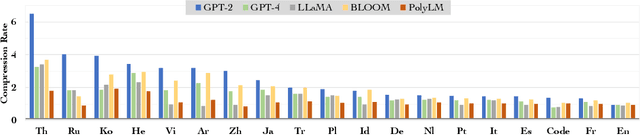
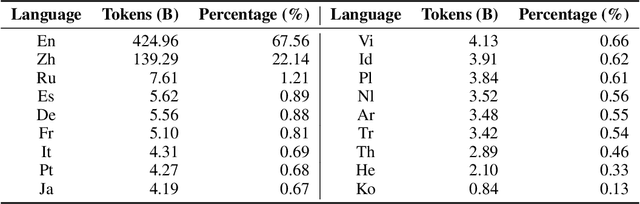
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limiting their applicability and research in other languages. Consequently, we present PolyLM, a multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training. Further, we propose a multilingual self-instruct method which automatically generates 132.7K diverse multilingual instructions for model fine-tuning. To assess the model's performance, we collect several existing multilingual tasks, including multilingual understanding, question answering, generation, and translation. Extensive experiments show that PolyLM surpasses other open-source models such as LLaMA and BLOOM on multilingual tasks while maintaining comparable performance in English. Our models, alone with the instruction data and multilingual benchmark, are available at: \url{https://modelscope.cn/models/damo/nlp_polylm_13b_text_generation}.
Bridging the Domain Gaps in Context Representations for k-Nearest Neighbor Neural Machine Translation
May 26, 2023



$k$-Nearest neighbor machine translation ($k$NN-MT) has attracted increasing attention due to its ability to non-parametrically adapt to new translation domains. By using an upstream NMT model to traverse the downstream training corpus, it is equipped with a datastore containing vectorized key-value pairs, which are retrieved during inference to benefit translation. However, there often exists a significant gap between upstream and downstream domains, which hurts the retrieval accuracy and the final translation quality. To deal with this issue, we propose a novel approach to boost the datastore retrieval of $k$NN-MT by reconstructing the original datastore. Concretely, we design a reviser to revise the key representations, making them better fit for the downstream domain. The reviser is trained using the collected semantically-related key-queries pairs, and optimized by two proposed losses: one is the key-queries semantic distance ensuring each revised key representation is semantically related to its corresponding queries, and the other is an L2-norm loss encouraging revised key representations to effectively retain the knowledge learned by the upstream NMT model. Extensive experiments on domain adaptation tasks demonstrate that our method can effectively boost the datastore retrieval and translation quality of $k$NN-MT.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/RevisedKey-knn-mt}.}
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023



Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.