 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-CT: A Novel Approach For Large Language Models Training With Resistance To Catastrophic Forgetting
Jun 25, 2024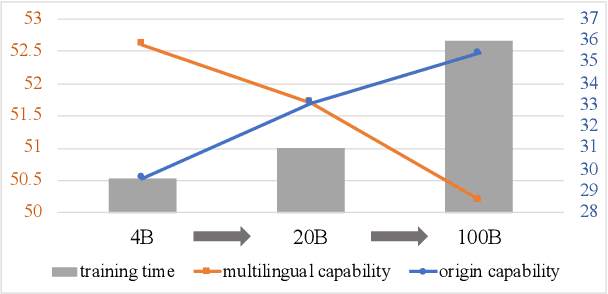

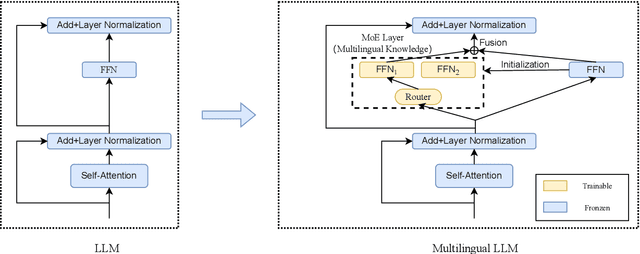
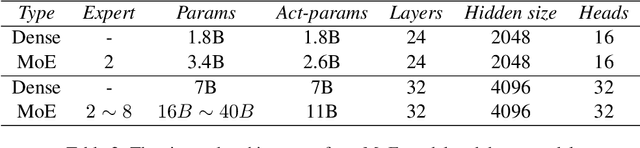
The advent of large language models (LLMs) has predominantly catered to high-resource languages, leaving a disparity in performance for low-resource languages. Conventional Continual Training (CT) approaches to bridge this gap often undermine a model's original linguistic proficiency when expanding to multilingual contexts. Addressing this issue, we introduce a novel MoE-CT architecture, a paradigm that innovatively separates the base model's learning from the multilingual expansion process. Our design freezes the original LLM parameters, thus safeguarding its performance in high-resource languages, while an appended MoE module, trained on diverse language datasets, augments low-resource language proficiency. Our approach significantly outperforms conventional CT methods, as evidenced by our experiments, which show marked improvements in multilingual benchmarks without sacrificing the model's original language performance. Moreover, our MoE-CT framework demonstrates enhanced resistance to forgetting and superior transfer learning capabilities. By preserving the base model's integrity and focusing on strategic parameter expansion, our methodology advances multilingual language modeling and represents a significant step forward for low-resource language inclusion in LLMs, indicating a fruitful direction for future research in language technologies.
PolyLM: An Open Source Polyglot Large Language Model
Jul 12, 2023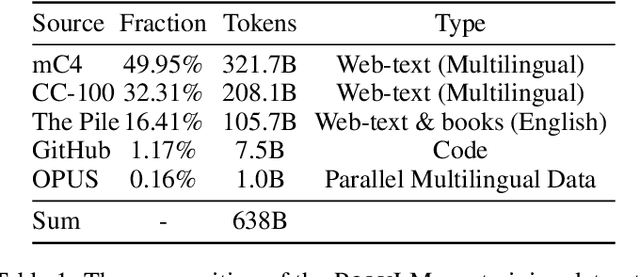
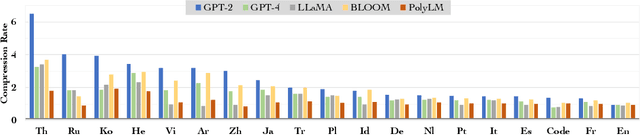
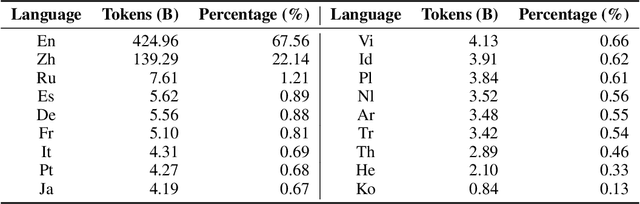
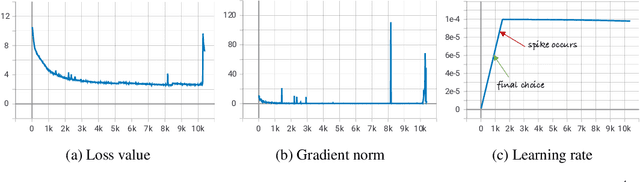
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limiting their applicability and research in other languages. Consequently, we present PolyLM, a multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training. Further, we propose a multilingual self-instruct method which automatically generates 132.7K diverse multilingual instructions for model fine-tuning. To assess the model's performance, we collect several existing multilingual tasks, including multilingual understanding, question answering, generation, and translation. Extensive experiments show that PolyLM surpasses other open-source models such as LLaMA and BLOOM on multilingual tasks while maintaining comparable performance in English. Our models, alone with the instruction data and multilingual benchmark, are available at: \url{https://modelscope.cn/models/damo/nlp_polylm_13b_text_generation}.
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023



Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.
WR-ONE2SET: Towards Well-Calibrated Keyphrase Generation
Nov 13, 2022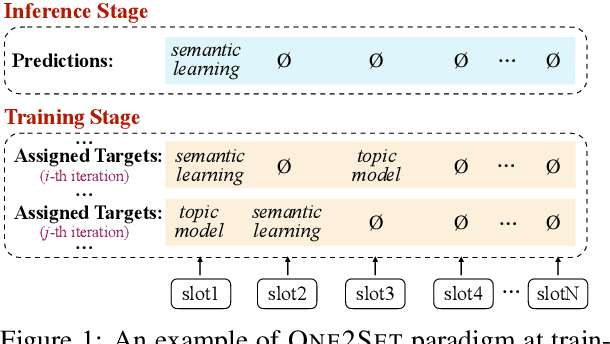
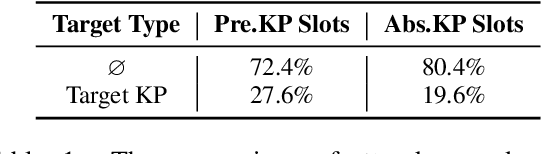

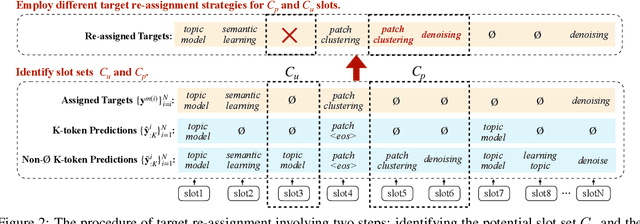
Keyphrase generation aims to automatically generate short phrases summarizing an input document. The recently emerged ONE2SET paradigm (Ye et al., 2021) generates keyphrases as a set and has achieved competitive performance. Nevertheless, we observe serious calibration errors outputted by ONE2SET, especially in the over-estimation of $\varnothing$ token (means "no corresponding keyphrase"). In this paper, we deeply analyze this limitation and identify two main reasons behind: 1) the parallel generation has to introduce excessive $\varnothing$ as padding tokens into training instances; and 2) the training mechanism assigning target to each slot is unstable and further aggravates the $\varnothing$ token over-estimation. To make the model well-calibrated, we propose WR-ONE2SET which extends ONE2SET with an adaptive instance-level cost Weighting strategy and a target Re-assignment mechanism. The former dynamically penalizes the over-estimated slots for different instances thus smoothing the uneven training distribution. The latter refines the original inappropriate assignment and reduces the supervisory signals of over-estimated slots. Experimental results on commonly-used datasets demonstrate the effectiveness and generality of our proposed paradigm.
Improving Tree-Structured Decoder Training for Code Generation via Mutual Learning
May 31, 2021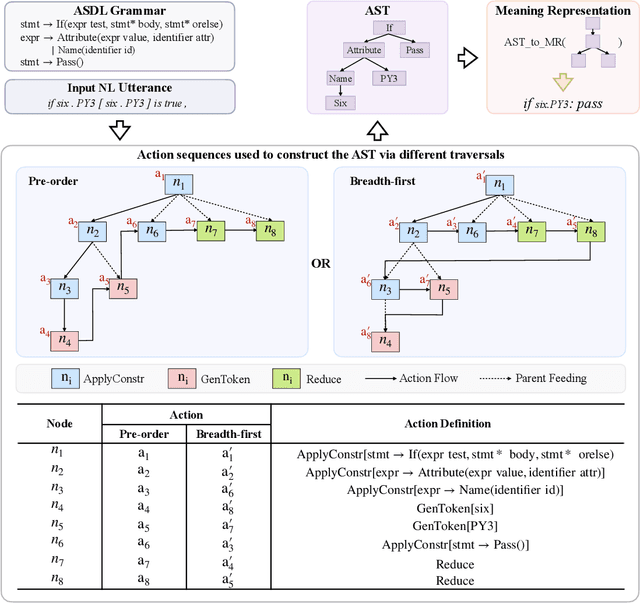
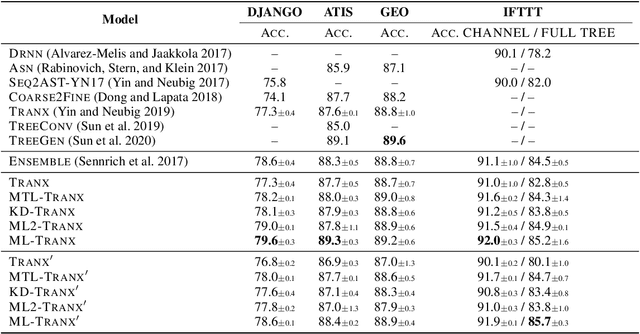
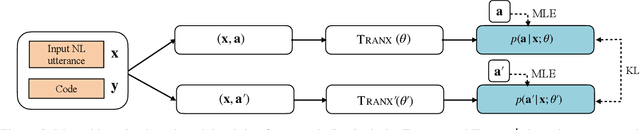
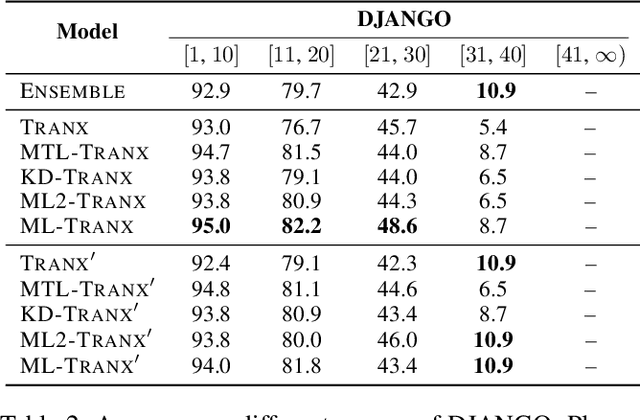
Code generation aims to automatically generate a piece of code given an input natural language utterance. Currently, among dominant models, it is treated as a sequence-to-tree task, where a decoder outputs a sequence of actions corresponding to the pre-order traversal of an Abstract Syntax Tree. However, such a decoder only exploits the preorder traversal based preceding actions, which are insufficient to ensure correct action predictions. In this paper, we first throughly analyze the context modeling difference between neural code generation models with different traversals based decodings (preorder traversal vs breadth-first traversal), and then propose to introduce a mutual learning framework to jointly train these models. Under this framework, we continuously enhance both two models via mutual distillation, which involves synchronous executions of two one-to-one knowledge transfers at each training step. More specifically, we alternately choose one model as the student and the other as its teacher, and require the student to fit the training data and the action prediction distributions of its teacher. By doing so, both models can fully absorb the knowledge from each other and thus could be improved simultaneously. Experimental results and in-depth analysis on several benchmark datasets demonstrate the effectiveness of our approach. We release our code at https://github.com/DeepLearnXMU/CGML.