 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Intelligence for Digital Twinning AI Data Centers: A Synergistic GenAI-PhyAI Approach
May 26, 2025The explosion in artificial intelligence (AI) applications is pushing the development of AI-dedicated data centers (AIDCs), creating management challenges that traditional methods and standalone AI solutions struggle to address. While digital twins are beneficial for AI-based design validation and operational optimization, current AI methods for their creation face limitations. Specifically, physical AI (PhyAI) aims to capture the underlying physical laws, which demands extensive, case-specific customization, and generative AI (GenAI) can produce inaccurate or hallucinated results. We propose Fusion Intelligence, a novel framework synergizing GenAI's automation with PhyAI's domain grounding. In this dual-agent collaboration, GenAI interprets natural language prompts to generate tokenized AIDC digital twins. Subsequently, PhyAI optimizes these generated twins by enforcing physical constraints and assimilating real-time data. Case studies demonstrate the advantages of our framework in automating the creation and validation of AIDC digital twins. These twins deliver predictive analytics to support power usage effectiveness (PUE) optimization in the design stage. With operational data collected, the digital twin accuracy is further improved compared with pure physics-based models developed by human experts. Fusion Intelligence offers a promising pathway to accelerate digital transformation. It enables more reliable and efficient AI-driven digital transformation for a broad range of mission-critical infrastructures.
Toward Physics-Informed Machine Learning for Data Center Operations: A Tropical Case Study
May 26, 2025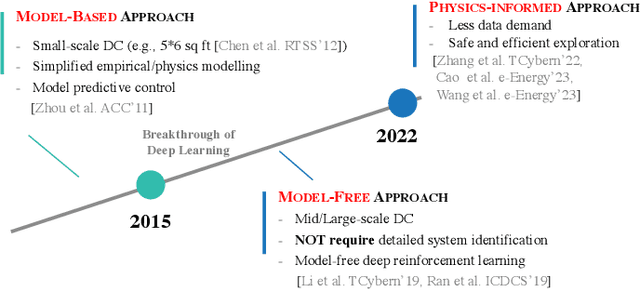
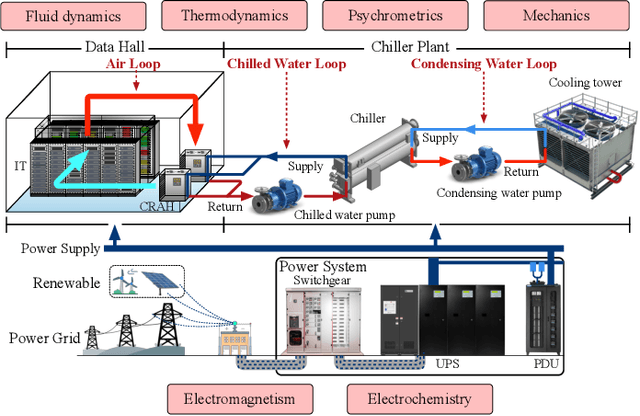
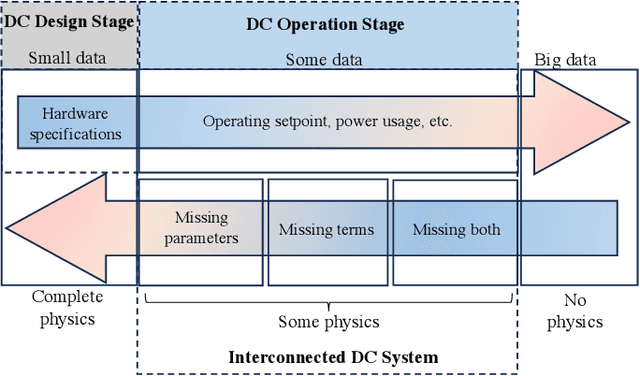
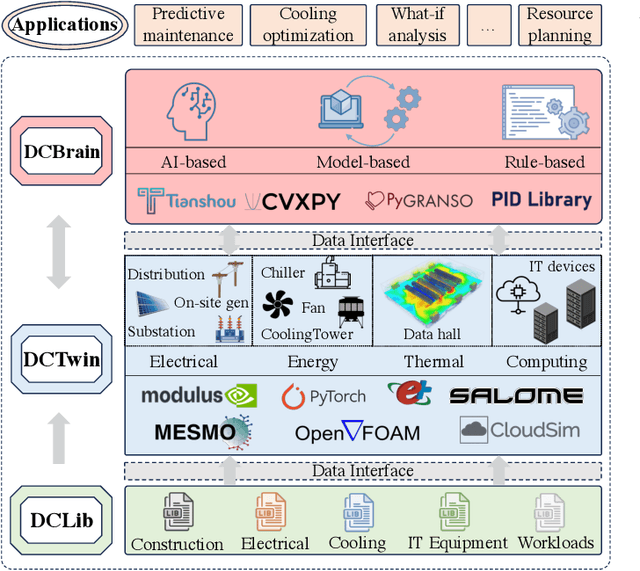
Data centers are the backbone of computing capacity. Operating data centers in the tropical regions faces unique challenges due to consistently high ambient temperature and elevated relative humidity throughout the year. These conditions result in increased cooling costs to maintain the reliability of the computing systems. While existing machine learning-based approaches have demonstrated potential to elevate operations to a more proactive and intelligent level, their deployment remains dubious due to concerns about model extrapolation capabilities and associated system safety issues. To address these concerns, this article proposes incorporating the physical characteristics of data centers into traditional data-driven machine learning solutions. We begin by introducing the data center system, including the relevant multiphysics processes and the data-physics availability. Next, we outline the associated modeling and optimization problems and propose an integrated, physics-informed machine learning system to address them. Using the proposed system, we present relevant applications across varying levels of operational intelligence. A case study on an industry-grade tropical data center is provided to demonstrate the effectiveness of our approach. Finally, we discuss key challenges and highlight potential future directions.
Transforming Future Data Center Operations and Management via Physical AI
Apr 07, 2025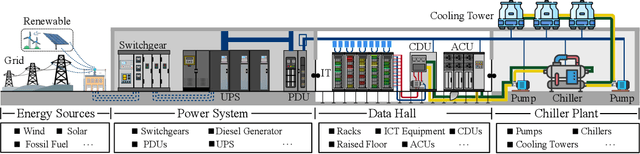
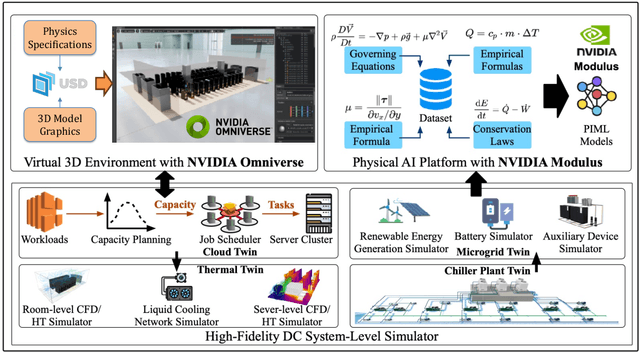
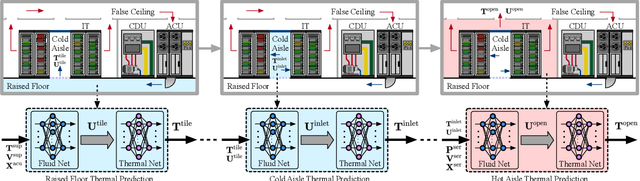
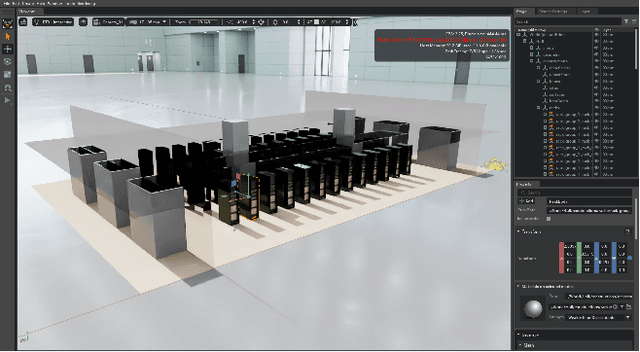
Data centers (DCs) as mission-critical infrastructures are pivotal in powering the growth of artificial intelligence (AI) and the digital economy. The evolution from Internet DC to AI DC has introduced new challenges in operating and managing data centers for improved business resilience and reduced total cost of ownership. As a result, new paradigms, beyond the traditional approaches based on best practices, must be in order for future data centers. In this research, we propose and develop a novel Physical AI (PhyAI) framework for advancing DC operations and management. Our system leverages the emerging capabilities of state-of-the-art industrial products and our in-house research and development. Specifically, it presents three core modules, namely: 1) an industry-grade in-house simulation engine to simulate DC operations in a highly accurate manner, 2) an AI engine built upon NVIDIA PhysicsNemo for the training and evaluation of physics-informed machine learning (PIML) models, and 3) a digital twin platform built upon NVIDIA Omniverse for our proposed 5-tier digital twin framework. This system presents a scalable and adaptable solution to digitalize, optimize, and automate future data center operations and management, by enabling real-time digital twins for future data centers. To illustrate its effectiveness, we present a compelling case study on building a surrogate model for predicting the thermal and airflow profiles of a large-scale DC in a real-time manner. Our results demonstrate its superior performance over traditional time-consuming Computational Fluid Dynamics/Heat Transfer (CFD/HT) simulation, with a median absolute temperature prediction error of 0.18 {\deg}C. This emerging approach would open doors to several potential research directions for advancing Physical AI in future DC operations.
Dual-Splitting Conformal Prediction for Multi-Step Time Series Forecasting
Mar 27, 2025Time series forecasting is crucial for applications like resource scheduling and risk management, where multi-step predictions provide a comprehensive view of future trends. Uncertainty Quantification (UQ) is a mainstream approach for addressing forecasting uncertainties, with Conformal Prediction (CP) gaining attention due to its model-agnostic nature and statistical guarantees. However, most variants of CP are designed for single-step predictions and face challenges in multi-step scenarios, such as reliance on real-time data and limited scalability. This highlights the need for CP methods specifically tailored to multi-step forecasting. We propose the Dual-Splitting Conformal Prediction (DSCP) method, a novel CP approach designed to capture inherent dependencies within time-series data for multi-step forecasting. Experimental results on real-world datasets from four different domains demonstrate that the proposed DSCP significantly outperforms existing CP variants in terms of the Winkler Score, achieving a performance improvement of up to 23.59% compared to state-of-the-art methods. Furthermore, we deployed the DSCP approach for renewable energy generation and IT load forecasting in power management of a real-world trajectory-based application, achieving an 11.25% reduction in carbon emissions through predictive optimization of data center operations and controls.
Efficient k-Nearest-Neighbor Machine Translation with Dynamic Retrieval
Jun 10, 2024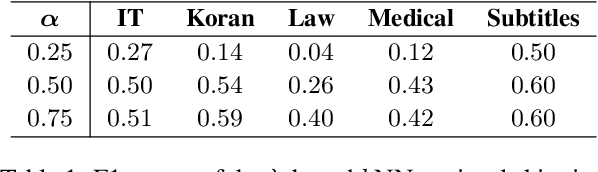
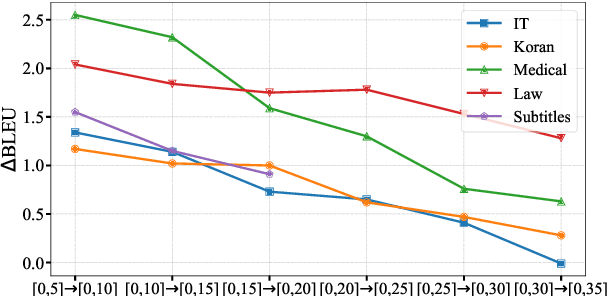
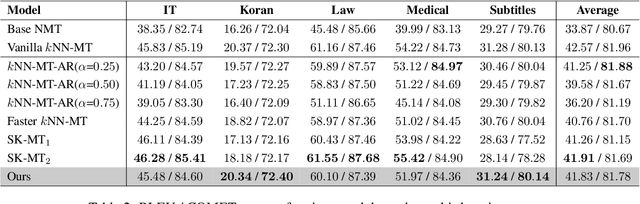
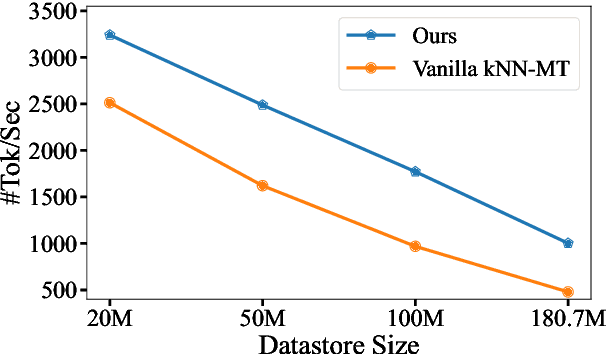
To achieve non-parametric NMT domain adaptation, $k$-Nearest-Neighbor Machine Translation ($k$NN-MT) constructs an external datastore to store domain-specific translation knowledge, which derives a $k$NN distribution to interpolate the prediction distribution of the NMT model via a linear interpolation coefficient $\lambda$. Despite its success, $k$NN retrieval at each timestep leads to substantial time overhead. To address this issue, dominant studies resort to $k$NN-MT with adaptive retrieval ($k$NN-MT-AR), which dynamically estimates $\lambda$ and skips $k$NN retrieval if $\lambda$ is less than a fixed threshold. Unfortunately, $k$NN-MT-AR does not yield satisfactory results. In this paper, we first conduct a preliminary study to reveal two key limitations of $k$NN-MT-AR: 1) the optimization gap leads to inaccurate estimation of $\lambda$ for determining $k$NN retrieval skipping, and 2) using a fixed threshold fails to accommodate the dynamic demands for $k$NN retrieval at different timesteps. To mitigate these limitations, we then propose $k$NN-MT with dynamic retrieval ($k$NN-MT-DR) that significantly extends vanilla $k$NN-MT in two aspects. Firstly, we equip $k$NN-MT with a MLP-based classifier for determining whether to skip $k$NN retrieval at each timestep. Particularly, we explore several carefully-designed scalar features to fully exert the potential of the classifier. Secondly, we propose a timestep-aware threshold adjustment method to dynamically generate the threshold, which further improves the efficiency of our model. Experimental results on the widely-used datasets demonstrate the effectiveness and generality of our model.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/knn-mt-dr}.
Retaining Key Information under High Compression Ratios: Query-Guided Compressor for LLMs
Jun 04, 2024



The growing popularity of Large Language Models has sparked interest in context compression for Large Language Models (LLMs). However, the performance of previous methods degrades dramatically as compression ratios increase, sometimes even falling to the closed-book level. This decline can be attributed to the loss of key information during the compression process. Our preliminary study supports this hypothesis, emphasizing the significance of retaining key information to maintain model performance under high compression ratios. As a result, we introduce Query-Guided Compressor (QGC), which leverages queries to guide the context compression process, effectively preserving key information within the compressed context. Additionally, we employ a dynamic compression strategy. We validate the effectiveness of our proposed QGC on the Question Answering task, including NaturalQuestions, TriviaQA, and HotpotQA datasets. Experimental results show that QGC can consistently perform well even at high compression ratios, which also offers significant benefits in terms of inference cost and throughput.
PolyLM: An Open Source Polyglot Large Language Model
Jul 12, 2023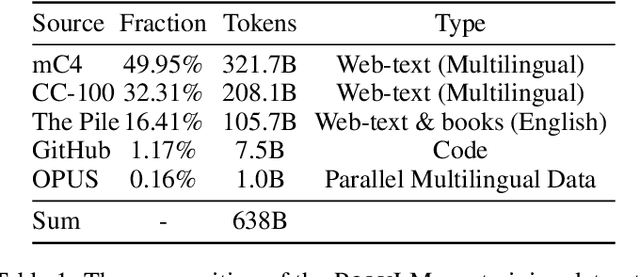
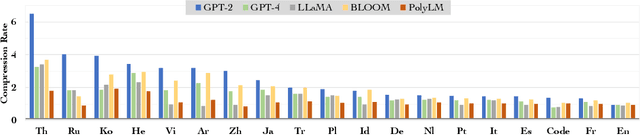
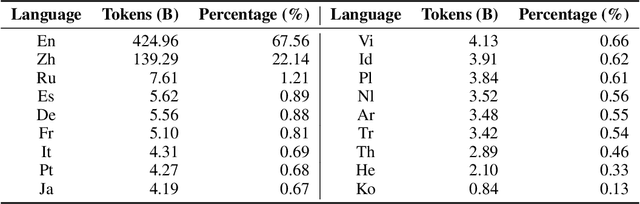
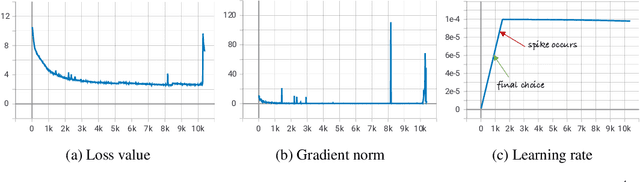
Large language models (LLMs) demonstrate remarkable ability to comprehend, reason, and generate following nature language instructions. However, the development of LLMs has been primarily focused on high-resource languages, such as English, thereby limiting their applicability and research in other languages. Consequently, we present PolyLM, a multilingual LLM trained on 640 billion (B) tokens, avaliable in two model sizes: 1.7B and 13B. To enhance its multilingual capabilities, we 1) integrate bilingual data into training data; and 2) adopt a curriculum learning strategy that increases the proportion of non-English data from 30% in the first stage to 60% in the final stage during pre-training. Further, we propose a multilingual self-instruct method which automatically generates 132.7K diverse multilingual instructions for model fine-tuning. To assess the model's performance, we collect several existing multilingual tasks, including multilingual understanding, question answering, generation, and translation. Extensive experiments show that PolyLM surpasses other open-source models such as LLaMA and BLOOM on multilingual tasks while maintaining comparable performance in English. Our models, alone with the instruction data and multilingual benchmark, are available at: \url{https://modelscope.cn/models/damo/nlp_polylm_13b_text_generation}.
Bridging the Domain Gaps in Context Representations for k-Nearest Neighbor Neural Machine Translation
May 26, 2023



$k$-Nearest neighbor machine translation ($k$NN-MT) has attracted increasing attention due to its ability to non-parametrically adapt to new translation domains. By using an upstream NMT model to traverse the downstream training corpus, it is equipped with a datastore containing vectorized key-value pairs, which are retrieved during inference to benefit translation. However, there often exists a significant gap between upstream and downstream domains, which hurts the retrieval accuracy and the final translation quality. To deal with this issue, we propose a novel approach to boost the datastore retrieval of $k$NN-MT by reconstructing the original datastore. Concretely, we design a reviser to revise the key representations, making them better fit for the downstream domain. The reviser is trained using the collected semantically-related key-queries pairs, and optimized by two proposed losses: one is the key-queries semantic distance ensuring each revised key representation is semantically related to its corresponding queries, and the other is an L2-norm loss encouraging revised key representations to effectively retain the knowledge learned by the upstream NMT model. Extensive experiments on domain adaptation tasks demonstrate that our method can effectively boost the datastore retrieval and translation quality of $k$NN-MT.\footnote{Our code is available at \url{https://github.com/DeepLearnXMU/RevisedKey-knn-mt}.}
Controllable Dialogue Generation with Disentangled Multi-grained Style Specification and Attribute Consistency Reward
Sep 14, 2021

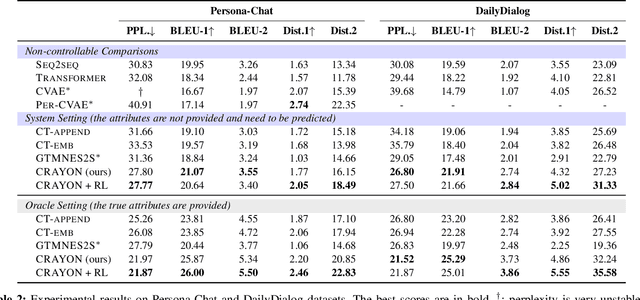
Controllable text generation is an appealing but challenging task, which allows users to specify particular attributes of the generated outputs. In this paper, we propose a controllable dialogue generation model to steer response generation under multi-attribute constraints. Specifically, we define and categorize the commonly used control attributes into global and local ones, which possess different granularities of effects on response generation. Then, we significantly extend the conventional seq2seq framework by introducing a novel two-stage decoder, which first uses a multi-grained style specification layer to impose the stylistic constraints and determine word-level control states of responses based on the attributes, and then employs a response generation layer to generate final responses maintaining both semantic relevancy to the contexts and fidelity to the attributes. Furthermore, we train our model with an attribute consistency reward to promote response control with explicit supervision signals. Extensive experiments and in-depth analyses on two datasets indicate that our model can significantly outperform competitive baselines in terms of response quality, content diversity and controllability.