 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining Key Information under High Compression Ratios: Query-Guided Compressor for LLMs
Jun 04, 2024



The growing popularity of Large Language Models has sparked interest in context compression for Large Language Models (LLMs). However, the performance of previous methods degrades dramatically as compression ratios increase, sometimes even falling to the closed-book level. This decline can be attributed to the loss of key information during the compression process. Our preliminary study supports this hypothesis, emphasizing the significance of retaining key information to maintain model performance under high compression ratios. As a result, we introduce Query-Guided Compressor (QGC), which leverages queries to guide the context compression process, effectively preserving key information within the compressed context. Additionally, we employ a dynamic compression strategy. We validate the effectiveness of our proposed QGC on the Question Answering task, including NaturalQuestions, TriviaQA, and HotpotQA datasets. Experimental results show that QGC can consistently perform well even at high compression ratios, which also offers significant benefits in terms of inference cost and throughput.
G-DIG: Towards Gradient-based DIverse and hiGh-quality Instruction Data Selection for Machine Translation
May 21, 2024Large Language Models (LLMs) have demonstrated remarkable abilities in general scenarios. Instruction finetuning empowers them to align with humans in various tasks. Nevertheless, the Diversity and Quality of the instruction data remain two main challenges for instruction finetuning. With regard to this, in this paper, we propose a novel gradient-based method to automatically select high-quality and diverse instruction finetuning data for machine translation. Our key innovation centers around analyzing how individual training examples influence the model during training. Specifically, we select training examples that exert beneficial influences on the model as high-quality ones by means of Influence Function plus a small high-quality seed dataset. Moreover, to enhance the diversity of the training data we maximize the variety of influences they have on the model by clustering on their gradients and resampling. Extensive experiments on WMT22 and FLORES translation tasks demonstrate the superiority of our methods, and in-depth analysis further validates their effectiveness and generalization.
DU-VLG: Unifying Vision-and-Language Generation via Dual Sequence-to-Sequence Pre-training
Mar 17, 2022


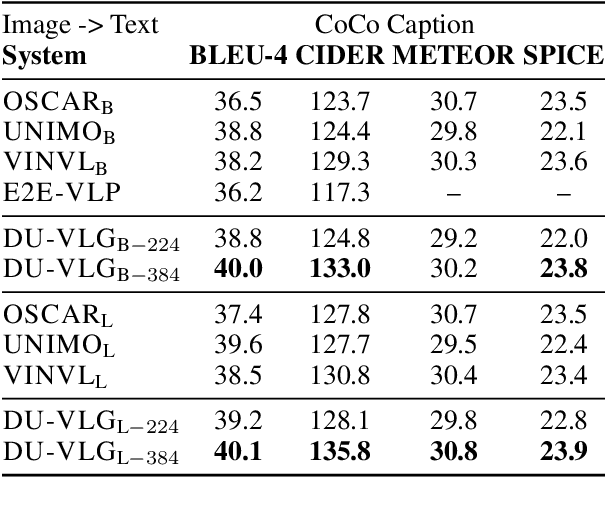
Due to the limitations of the model structure and pre-training objectives, existing vision-and-language generation models cannot utilize pair-wise images and text through bi-directional generation. In this paper, we propose DU-VLG, a framework which unifies vision-and-language generation as sequence generation problems. DU-VLG is trained with novel dual pre-training tasks: multi-modal denoising autoencoder tasks and modality translation tasks. To bridge the gap between image understanding and generation, we further design a novel commitment loss. We compare pre-training objectives on image captioning and text-to-image generation datasets. Results show that DU-VLG yields better performance than variants trained with uni-directional generation objectives or the variant without the commitment loss. We also obtain higher scores compared to previous state-of-the-art systems on three vision-and-language generation tasks. In addition, human judges further confirm that our model generates real and relevant images as well as faithful and informative captions.
Efficient Attentions for Long Document Summarization
Apr 11, 2021
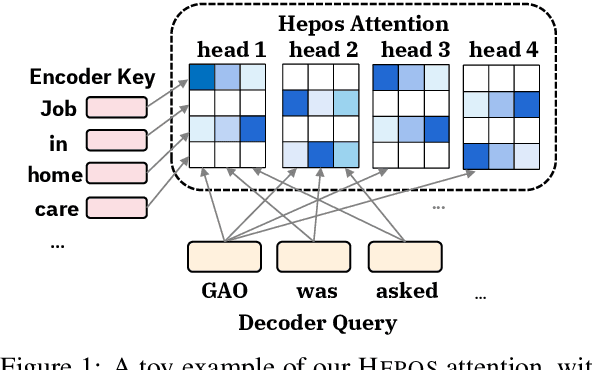


The quadratic computational and memory complexities of large Transformers have limited their scalability for long document summarization. In this paper, we propose Hepos, a novel efficient encoder-decoder attention with head-wise positional strides to effectively pinpoint salient information from the source. We further conduct a systematic study of existing efficient self-attentions. Combined with Hepos, we are able to process ten times more tokens than existing models that use full attentions. For evaluation, we present a new dataset, GovReport, with significantly longer documents and summaries. Results show that our models produce significantly higher ROUGE scores than competitive comparisons, including new state-of-the-art results on PubMed. Human evaluation also shows that our models generate more informative summaries with fewer unfaithful errors.
Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward
May 03, 2020

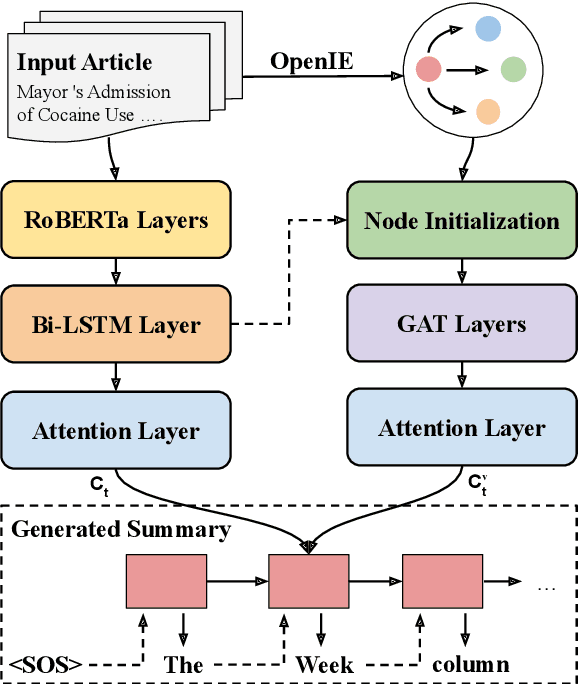

Sequence-to-sequence models for abstractive summarization have been studied extensively, yet the generated summaries commonly suffer from fabricated content, and are often found to be near-extractive. We argue that, to address these issues, the summarizer should acquire semantic interpretation over input, e.g., via structured representation, to allow the generation of more informative summaries. In this paper, we present ASGARD, a novel framework for Abstractive Summarization with Graph-Augmentation and semantic-driven RewarD. We propose the use of dual encoders---a sequential document encoder and a graph-structured encoder---to maintain the global context and local characteristics of entities, complementing each other. We further design a reward based on a multiple choice cloze test to drive the model to better capture entity interactions. Results show that our models produce significantly higher ROUGE scores than a variant without knowledge graph as input on both New York Times and CNN/Daily Mail datasets. We also obtain better or comparable performance compared to systems that are fine-tuned from large pretrained language models. Human judges further rate our model outputs as more informative and containing fewer unfaithful errors.
An Entity-Driven Framework for Abstractive Summarization
Sep 04, 2019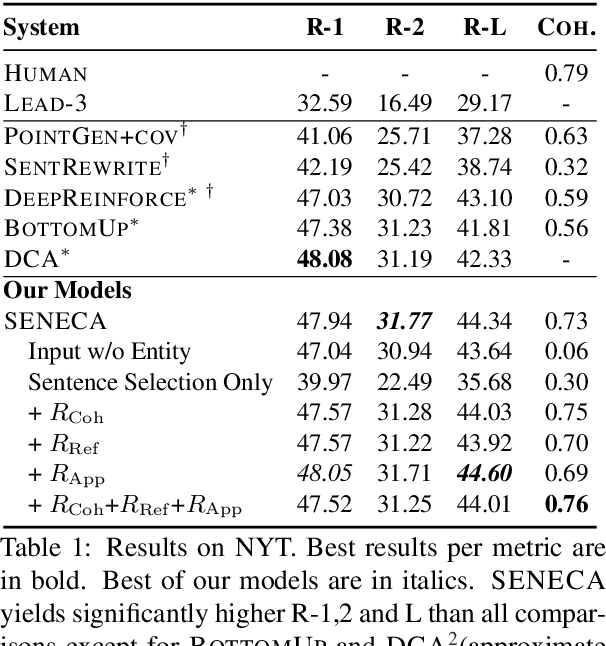
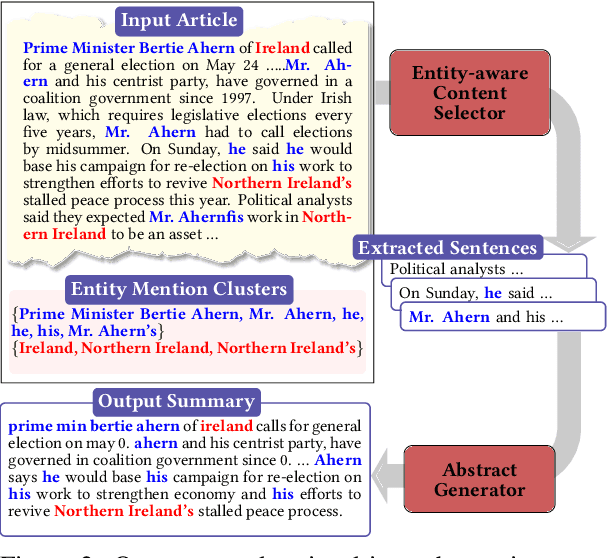
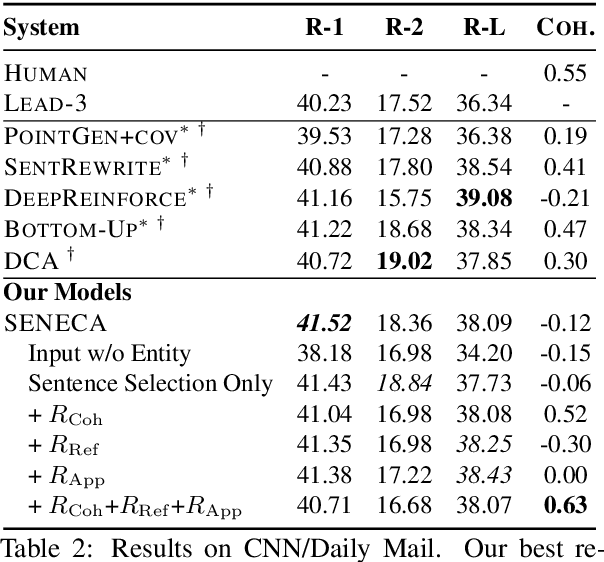

Abstractive summarization systems aim to produce more coherent and concise summaries than their extractive counterparts. Popular neural models have achieved impressive results for single-document summarization, yet their outputs are often incoherent and unfaithful to the input. In this paper, we introduce SENECA, a novel System for ENtity-drivEn Coherent Abstractive summarization framework that leverages entity information to generate informative and coherent abstracts. Our framework takes a two-step approach: (1) an entity-aware content selection module first identifies salient sentences from the input, then (2) an abstract generation module conducts cross-sentence information compression and abstraction to generate the final summary, which is trained with rewards to promote coherence, conciseness, and clarity. The two components are further connected using reinforcement learning. Automatic evaluation shows that our model significantly outperforms previous state-of-the-art on ROUGE and our proposed coherence measures on New York Times and CNN/Daily Mail datasets. Human judges further rate our system summaries as more informative and coherent than those by popular summarization models.