 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaunce: Data Attribution through Uncertainty Estimation
May 29, 2025Training data attribution (TDA) methods aim to identify which training examples influence a model's predictions on specific test data most. By quantifying these influences, TDA supports critical applications such as data debugging, curation, and valuation. Gradient-based TDA methods rely on gradients and second-order information, limiting their applicability at scale. While recent random projection-based methods improve scalability, they often suffer from degraded attribution accuracy. Motivated by connections between uncertainty and influence functions, we introduce Daunce - a simple yet effective data attribution approach through uncertainty estimation. Our method operates by fine-tuning a collection of perturbed models and computing the covariance of per-example losses across these models as the attribution score. Daunce is scalable to large language models (LLMs) and achieves more accurate attribution compared to existing TDA methods. We validate Daunce on tasks ranging from vision tasks to LLM fine-tuning, and further demonstrate its compatibility with black-box model access. Applied to OpenAI's GPT models, our method achieves, to our knowledge, the first instance of data attribution on proprietary LLMs.
Adapt-Pruner: Adaptive Structural Pruning for Efficient Small Language Model Training
Feb 05, 2025Small language models (SLMs) have attracted considerable attention from both academia and industry due to their broad range of applications in edge devices. To obtain SLMs with strong performance, conventional approaches either pre-train the models from scratch, which incurs substantial computational costs, or compress/prune existing large language models (LLMs), which results in performance drops and falls short in comparison to pre-training. In this paper, we investigate the family of acceleration methods that involve both structured pruning and model training. We found 1) layer-wise adaptive pruning (Adapt-Pruner) is extremely effective in LLMs and yields significant improvements over existing pruning techniques, 2) adaptive pruning equipped with further training leads to models comparable to those pre-training from scratch, 3) incremental pruning brings non-trivial performance gain by interleaving pruning with training and only removing a small portion of neurons ($\sim$5%) at a time. Experimental results on LLaMA-3.1-8B demonstrate that Adapt-Pruner outperforms conventional pruning methods, such as LLM-Pruner, FLAP, and SliceGPT, by an average of 1%-7% in accuracy on commonsense benchmarks. Additionally, Adapt-Pruner restores the performance of MobileLLM-125M to 600M on the MMLU benchmark with 200$\times$ fewer tokens via pruning from its larger counterparts, and discovers a new 1B model that surpasses LLaMA-3.2-1B in multiple benchmarks.
ScaleBiO: Scalable Bilevel Optimization for LLM Data Reweighting
Jun 28, 2024



Bilevel optimization has shown its utility across various machine learning settings, yet most algorithms in practice require second-order information, making it challenging to scale them up. Only recently, a paradigm of first-order algorithms emerged, capable of effectively addressing bilevel optimization problems. Nevertheless, the practical efficiency of this paradigm remains unverified, particularly in the context of large language models (LLMs). This paper introduces the first scalable instantiation of this paradigm called ScaleBiO, focusing on bilevel optimization for large-scale LLM data reweighting. By combining with a recently proposed memory-efficient training technique called LISA, our novel algorithm allows the paradigm to scale to 34-billion-parameter LLMs on eight A40 GPUs, marking the first successful application of bilevel optimization under practical scenarios for large-sized LLMs. Empirically, extensive experiments on data reweighting verify the effectiveness of ScaleBiO for different-scaled models, including GPT-2, LLaMA-3-8B, GPT-NeoX-20B, and Yi-34B, where bilevel optimization succeeds in filtering irrelevant data samples and selecting informative samples. Theoretically, ScaleBiO ensures the optimality of the learned data weights, along with a convergence guarantee matching the conventional first-order bilevel optimization paradigm on smooth and strongly convex objectives.
G-DIG: Towards Gradient-based DIverse and hiGh-quality Instruction Data Selection for Machine Translation
May 21, 2024Large Language Models (LLMs) have demonstrated remarkable abilities in general scenarios. Instruction finetuning empowers them to align with humans in various tasks. Nevertheless, the Diversity and Quality of the instruction data remain two main challenges for instruction finetuning. With regard to this, in this paper, we propose a novel gradient-based method to automatically select high-quality and diverse instruction finetuning data for machine translation. Our key innovation centers around analyzing how individual training examples influence the model during training. Specifically, we select training examples that exert beneficial influences on the model as high-quality ones by means of Influence Function plus a small high-quality seed dataset. Moreover, to enhance the diversity of the training data we maximize the variety of influences they have on the model by clustering on their gradients and resampling. Extensive experiments on WMT22 and FLORES translation tasks demonstrate the superiority of our methods, and in-depth analysis further validates their effectiveness and generalization.
Learning Constraints for Structured Prediction Using Rectifier Networks
May 23, 2020
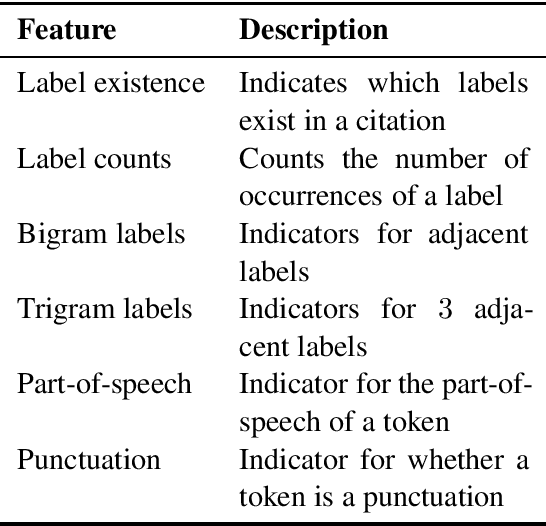

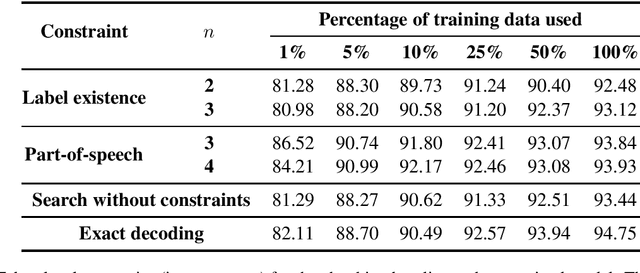
Various natural language processing tasks are structured prediction problems where outputs are constructed with multiple interdependent decisions. Past work has shown that domain knowledge, framed as constraints over the output space, can help improve predictive accuracy. However, designing good constraints often relies on domain expertise. In this paper, we study the problem of learning such constraints. We frame the problem as that of training a two-layer rectifier network to identify valid structures or substructures, and show a construction for converting a trained network into a system of linear constraints over the inference variables. Our experiments on several NLP tasks show that the learned constraints can improve the prediction accuracy, especially when the number of training examples is small.
Learning to Speed Up Structured Output Prediction
Jun 11, 2018


Predicting structured outputs can be computationally onerous due to the combinatorially large output spaces. In this paper, we focus on reducing the prediction time of a trained black-box structured classifier without losing accuracy. To do so, we train a speedup classifier that learns to mimic a black-box classifier under the learning-to-search approach. As the structured classifier predicts more examples, the speedup classifier will operate as a learned heuristic to guide search to favorable regions of the output space. We present a mistake bound for the speedup classifier and identify inference situations where it can independently make correct judgments without input features. We evaluate our method on the task of entity and relation extraction and show that the speedup classifier outperforms even greedy search in terms of speed without loss of accuracy.
Expressiveness of Rectifier Networks
May 27, 2016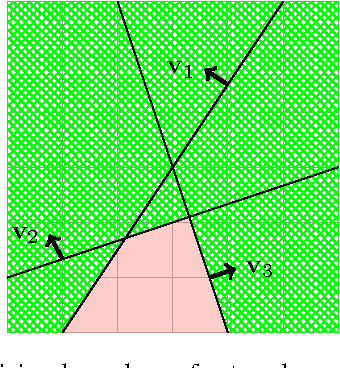
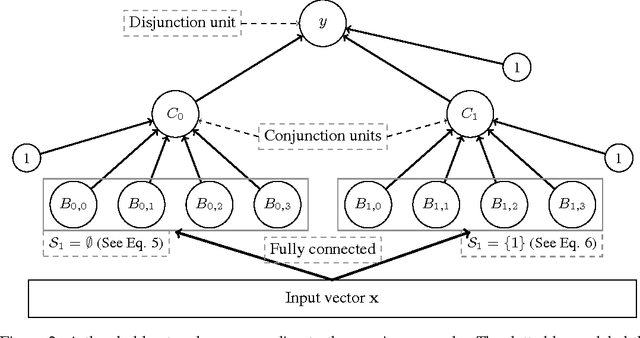
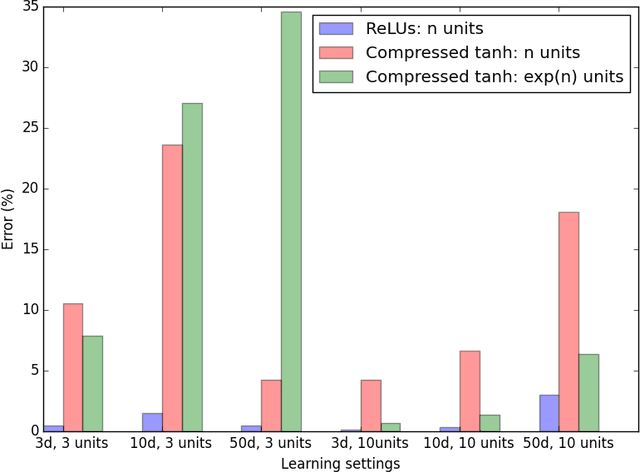
Rectified Linear Units (ReLUs) have been shown to ameliorate the vanishing gradient problem, allow for efficient backpropagation, and empirically promote sparsity in the learned parameters. They have led to state-of-the-art results in a variety of applications. However, unlike threshold and sigmoid networks, ReLU networks are less explored from the perspective of their expressiveness. This paper studies the expressiveness of ReLU networks. We characterize the decision boundary of two-layer ReLU networks by constructing functionally equivalent threshold networks. We show that while the decision boundary of a two-layer ReLU network can be captured by a threshold network, the latter may require an exponentially larger number of hidden units. We also formulate sufficient conditions for a corresponding logarithmic reduction in the number of hidden units to represent a sign network as a ReLU network. Finally, we experimentally compare threshold networks and their much smaller ReLU counterparts with respect to their ability to learn from synthetically generated data.