 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Found in Translation: Measuring Multilingual LLM Consistency as Simple as Translate then Evaluate
May 28, 2025Large language models (LLMs) provide detailed and impressive responses to queries in English. However, are they really consistent at responding to the same query in other languages? The popular way of evaluating for multilingual performance of LLMs requires expensive-to-collect annotated datasets. Further, evaluating for tasks like open-ended generation, where multiple correct answers may exist, is nontrivial. Instead, we propose to evaluate the predictability of model response across different languages. In this work, we propose a framework to evaluate LLM's cross-lingual consistency based on a simple Translate then Evaluate strategy. We instantiate this evaluation framework along two dimensions of consistency: information and empathy. Our results reveal pronounced inconsistencies in popular LLM responses across thirty languages, with severe performance deficits in certain language families and scripts, underscoring critical weaknesses in their multilingual capabilities. These findings necessitate cross-lingual evaluations that are consistent along multiple dimensions. We invite practitioners to use our framework for future multilingual LLM benchmarking.
Promptly Predicting Structures: The Return of Inference
Jan 12, 2024Prompt-based methods have been used extensively across NLP to build zero- and few-shot label predictors. Many NLP tasks are naturally structured: that is, their outputs consist of multiple labels which constrain each other. Annotating data for such tasks can be cumbersome. Can the promise of the prompt-based paradigm be extended to such structured outputs? In this paper, we present a framework for constructing zero- and few-shot linguistic structure predictors. Our key insight is that we can use structural constraints -- and combinatorial inference derived from them -- to filter out inconsistent structures predicted by large language models. We instantiated this framework on two structured prediction tasks, and five datasets. Across all cases, our results show that enforcing consistency not only constructs structurally valid outputs, but also improves performance over the unconstrained variants.
Learning Constraints for Structured Prediction Using Rectifier Networks
May 23, 2020
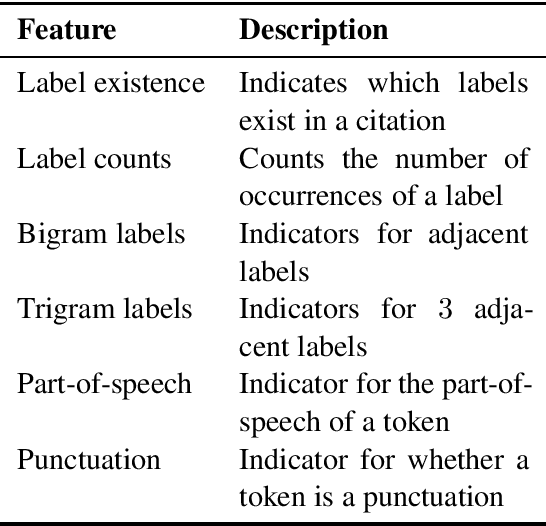

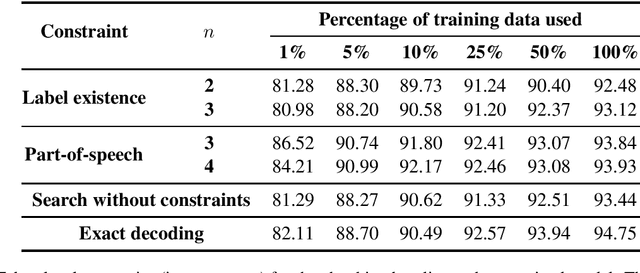
Various natural language processing tasks are structured prediction problems where outputs are constructed with multiple interdependent decisions. Past work has shown that domain knowledge, framed as constraints over the output space, can help improve predictive accuracy. However, designing good constraints often relies on domain expertise. In this paper, we study the problem of learning such constraints. We frame the problem as that of training a two-layer rectifier network to identify valid structures or substructures, and show a construction for converting a trained network into a system of linear constraints over the inference variables. Our experiments on several NLP tasks show that the learned constraints can improve the prediction accuracy, especially when the number of training examples is small.
INFOTABS: Inference on Tables as Semi-structured Data
May 13, 2020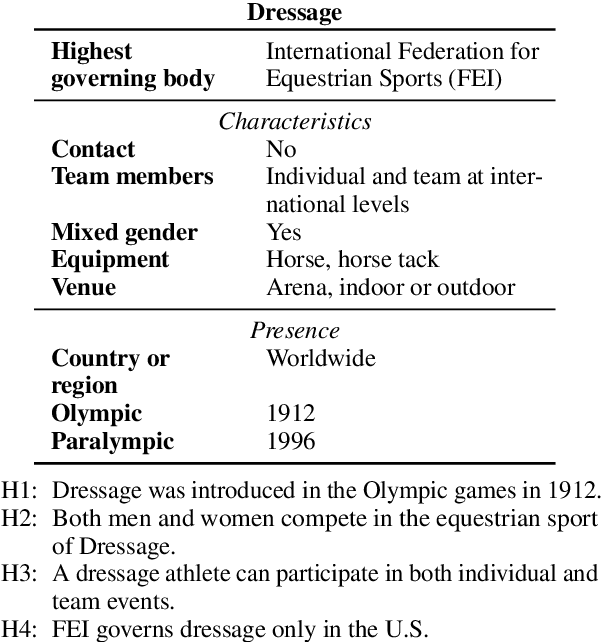

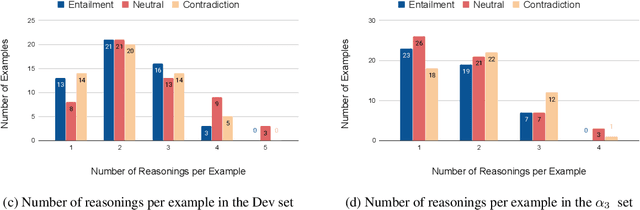
In this paper, we observe that semi-structured tabulated text is ubiquitous; understanding them requires not only comprehending the meaning of text fragments, but also implicit relationships between them. We argue that such data can prove as a testing ground for understanding how we reason about information. To study this, we introduce a new dataset called INFOTABS, comprising of human-written textual hypotheses based on premises that are tables extracted from Wikipedia info-boxes. Our analysis shows that the semi-structured, multi-domain and heterogeneous nature of the premises admits complex, multi-faceted reasoning. Experiments reveal that, while human annotators agree on the relationships between a table-hypothesis pair, several standard modeling strategies are unsuccessful at the task, suggesting that reasoning about tables can pose a difficult modeling challenge.
A Logic-Driven Framework for Consistency of Neural Models
Sep 13, 2019



While neural models show remarkable accuracy on individual predictions, their internal beliefs can be inconsistent across examples. In this paper, we formalize such inconsistency as a generalization of prediction error. We propose a learning framework for constraining models using logic rules to regularize them away from inconsistency. Our framework can leverage both labeled and unlabeled examples and is directly compatible with off-the-shelf learning schemes without model redesign. We instantiate our framework on natural language inference, where experiments show that enforcing invariants stated in logic can help make the predictions of neural models both accurate and consistent.
Correlated discrete data generation using adversarial training
Apr 03, 2018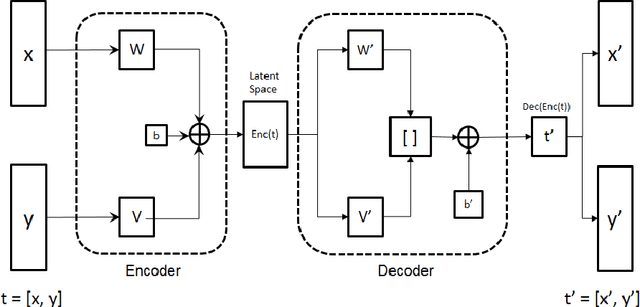

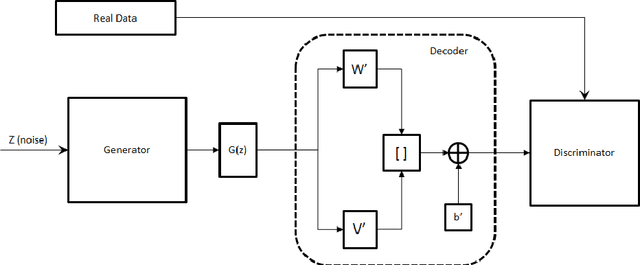

Generative Adversarial Networks (GAN) have shown great promise in tasks like synthetic image generation, image inpainting, style transfer, and anomaly detection. However, generating discrete data is a challenge. This work presents an adversarial training based correlated discrete data (CDD) generation model. It also details an approach for conditional CDD generation. The results of our approach are presented over two datasets; job-seeking candidates skill set (private dataset) and MNIST (public dataset). From quantitative and qualitative analysis of these results, we show that our model performs better as it leverages inherent correlation in the data, than an existing model that overlooks correlation.