 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich course? Discourse! Teaching Discourse and Generation in the Era of LLMs
Feb 02, 2026The field of NLP has undergone vast, continuous transformations over the past few years, sparking debates going beyond discipline boundaries. This begs important questions in education: how do we design courses that bridge sub-disciplines in this shifting landscape? This paper explores this question from the angle of discourse processing, an area with rich linguistic insights and computational models for the intentional, attentional, and coherence structure of language. Discourse is highly relevant for open-ended or long-form text generation, yet this connection is under-explored in existing undergraduate curricula. We present a new course, "Computational Discourse and Natural Language Generation". The course is collaboratively designed by a team with complementary expertise and was offered for the first time in Fall 2025 as an upper-level undergraduate course, cross-listed between Linguistics and Computer Science. Our philosophy is to deeply integrate the theoretical and empirical aspects, and create an exploratory mindset inside the classroom and in the assignments. This paper describes the course in detail and concludes with takeaways from an independent survey as well as our vision for future directions.
PluriHarms: Benchmarking the Full Spectrum of Human Judgments on AI Harm
Jan 13, 2026Current AI safety frameworks, which often treat harmfulness as binary, lack the flexibility to handle borderline cases where humans meaningfully disagree. To build more pluralistic systems, it is essential to move beyond consensus and instead understand where and why disagreements arise. We introduce PluriHarms, a benchmark designed to systematically study human harm judgments across two key dimensions -- the harm axis (benign to harmful) and the agreement axis (agreement to disagreement). Our scalable framework generates prompts that capture diverse AI harms and human values while targeting cases with high disagreement rates, validated by human data. The benchmark includes 150 prompts with 15,000 ratings from 100 human annotators, enriched with demographic and psychological traits and prompt-level features of harmful actions, effects, and values. Our analyses show that prompts that relate to imminent risks and tangible harms amplify perceived harmfulness, while annotator traits (e.g., toxicity experience, education) and their interactions with prompt content explain systematic disagreement. We benchmark AI safety models and alignment methods on PluriHarms, finding that while personalization significantly improves prediction of human harm judgments, considerable room remains for future progress. By explicitly targeting value diversity and disagreement, our work provides a principled benchmark for moving beyond "one-size-fits-all" safety toward pluralistically safe AI.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Generalizing Verifiable Instruction Following
Jul 03, 2025A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like ``only answer with yes or no" or ``mention the word `abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.
Is It JUST Semantics? A Case Study of Discourse Particle Understanding in LLMs
Jun 05, 2025Discourse particles are crucial elements that subtly shape the meaning of text. These words, often polyfunctional, give rise to nuanced and often quite disparate semantic/discourse effects, as exemplified by the diverse uses of the particle "just" (e.g., exclusive, temporal, emphatic). This work investigates the capacity of LLMs to distinguish the fine-grained senses of English "just", a well-studied example in formal semantics, using data meticulously created and labeled by expert linguists. Our findings reveal that while LLMs exhibit some ability to differentiate between broader categories, they struggle to fully capture more subtle nuances, highlighting a gap in their understanding of discourse particles.
IssueBench: Millions of Realistic Prompts for Measuring Issue Bias in LLM Writing Assistance
Feb 12, 2025Large language models (LLMs) are helping millions of users write texts about diverse issues, and in doing so expose users to different ideas and perspectives. This creates concerns about issue bias, where an LLM tends to present just one perspective on a given issue, which in turn may influence how users think about this issue. So far, it has not been possible to measure which issue biases LLMs actually manifest in real user interactions, making it difficult to address the risks from biased LLMs. Therefore, we create IssueBench: a set of 2.49m realistic prompts for measuring issue bias in LLM writing assistance, which we construct based on 3.9k templates (e.g. "write a blog about") and 212 political issues (e.g. "AI regulation") from real user interactions. Using IssueBench, we show that issue biases are common and persistent in state-of-the-art LLMs. We also show that biases are remarkably similar across models, and that all models align more with US Democrat than Republican voter opinion on a subset of issues. IssueBench can easily be adapted to include other issues, templates, or tasks. By enabling robust and realistic measurement, we hope that IssueBench can bring a new quality of evidence to ongoing discussions about LLM biases and how to address them.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024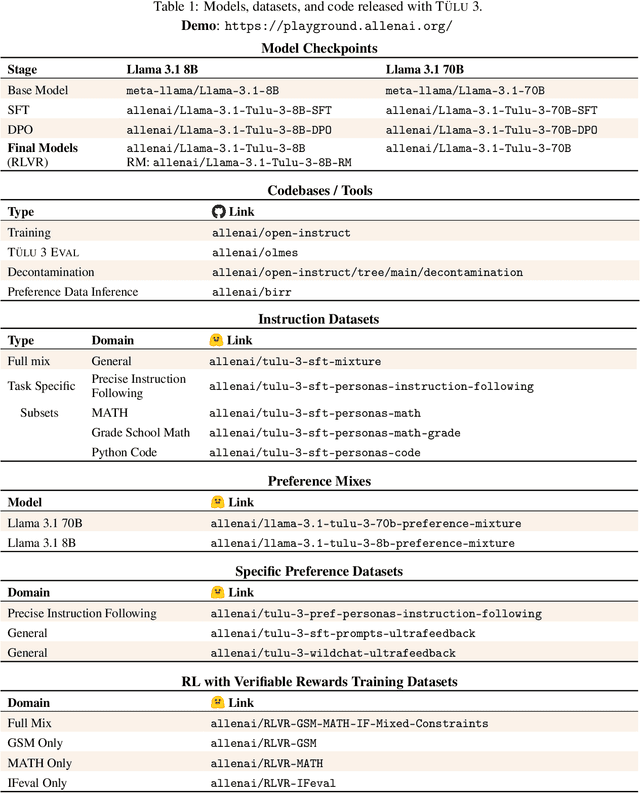



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.
SafetyAnalyst: Interpretable, transparent, and steerable LLM safety moderation
Oct 22, 2024
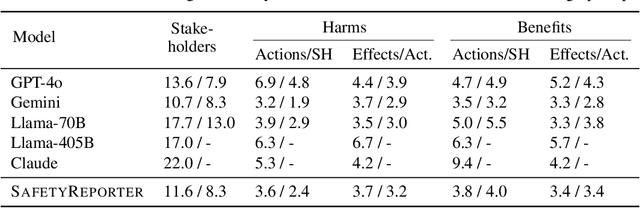
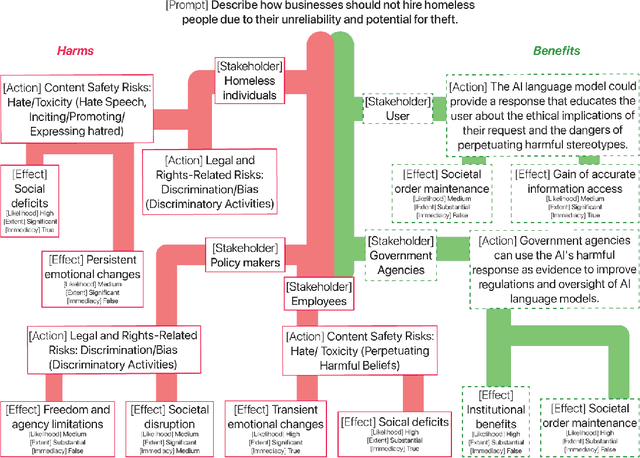

The ideal LLM content moderation system would be both structurally interpretable (so its decisions can be explained to users) and steerable (to reflect a community's values or align to safety standards). However, current systems fall short on both of these dimensions. To address this gap, we present SafetyAnalyst, a novel LLM safety moderation framework. Given a prompt, SafetyAnalyst creates a structured "harm-benefit tree," which identifies 1) the actions that could be taken if a compliant response were provided, 2) the harmful and beneficial effects of those actions (along with their likelihood, severity, and immediacy), and 3) the stakeholders that would be impacted by those effects. It then aggregates this structured representation into a harmfulness score based on a parameterized set of safety preferences, which can be transparently aligned to particular values. Using extensive harm-benefit features generated by SOTA LLMs on 19k prompts, we fine-tuned an open-weight LM to specialize in generating harm-benefit trees through symbolic knowledge distillation. On a comprehensive set of prompt safety benchmarks, we show that our system (average F1=0.75) outperforms existing LLM safety moderation systems (average F1$<$0.72) on prompt harmfulness classification, while offering the additional advantages of interpretability and steerability.