 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Vibe? Finding and Controlling Language-Agnostic Informal Register with SAEs
Mar 27, 2026While multilingual language models successfully transfer factual and syntactic knowledge across languages, it remains unclear whether they process culture-specific pragmatic registers, such as slang, as isolated language-specific memorizations or as unified, abstract concepts. We study this by probing the internal representations of Gemma-2-9B-IT using Sparse Autoencoders (SAEs) across three typologically diverse source languages: English, Hebrew, and Russian. To definitively isolate pragmatic register processing from trivial lexical sensitivity, we introduce a novel dataset in which every target term is polysemous, appearing in both literal and informal contexts. We find that while much of the informal-register signal is distributed across language-specific features, a small but highly robust cross-linguistic core consistently emerges. This shared core forms a geometrically coherent ``informal register subspace'' that sharpens in the model's deeper layers. Crucially, these shared representations are not merely correlational: activation steering with these features causally shifts output formality across all source languages and transfers zero-shot to six unseen languages spanning diverse language families and scripts. Together, these results provide the first mechanistic evidence that multilingual LLMs internalize informal register not just as surface-level heuristics, but as a portable, language-agnostic pragmatic abstraction.
Effective QA-driven Annotation of Predicate-Argument Relations Across Languages
Feb 26, 2026Explicit representations of predicate-argument relations form the basis of interpretable semantic analysis, supporting reasoning, generation, and evaluation. However, attaining such semantic structures requires costly annotation efforts and has remained largely confined to English. We leverage the Question-Answer driven Semantic Role Labeling (QA-SRL) framework -- a natural-language formulation of predicate-argument relations -- as the foundation for extending semantic annotation to new languages. To this end, we introduce a cross-linguistic projection approach that reuses an English QA-SRL parser within a constrained translation and word-alignment pipeline to automatically generate question-answer annotations aligned with target-language predicates. Applied to Hebrew, Russian, and French -- spanning diverse language families -- the method yields high-quality training data and fine-tuned, language-specific parsers that outperform strong multilingual LLM baselines (GPT-4o, LLaMA-Maverick). By leveraging QA-SRL as a transferable natural-language interface for semantics, our approach enables efficient and broadly accessible predicate-argument parsing across languages.
QA-Noun: Representing Nominal Semantics via Natural Language Question-Answer Pairs
Nov 16, 2025
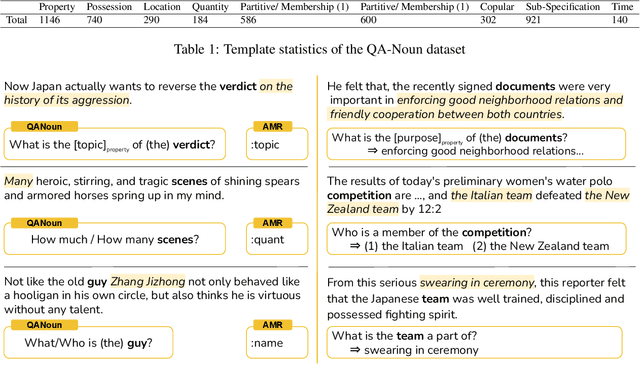
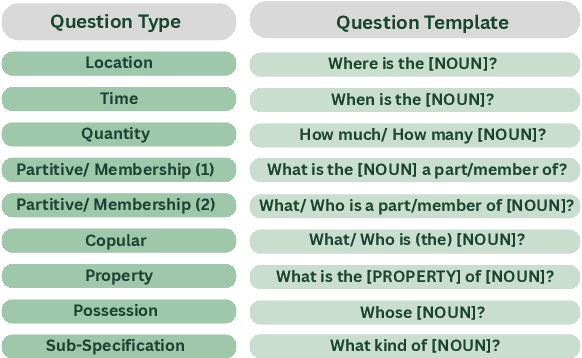
Decomposing sentences into fine-grained meaning units is increasingly used to model semantic alignment. While QA-based semantic approaches have shown effectiveness for representing predicate-argument relations, they have so far left noun-centered semantics largely unaddressed. We introduce QA-Noun, a QA-based framework for capturing noun-centered semantic relations. QA-Noun defines nine question templates that cover both explicit syntactical and implicit contextual roles for nouns, producing interpretable QA pairs that complement verbal QA-SRL. We release detailed guidelines, a dataset of over 2,000 annotated noun mentions, and a trained model integrated with QA-SRL to yield a unified decomposition of sentence meaning into individual, highly fine-grained, facts. Evaluation shows that QA-Noun achieves near-complete coverage of AMR's noun arguments while surfacing additional contextually implied relations, and that combining QA-Noun with QA-SRL yields over 130\% higher granularity than recent fact-based decomposition methods such as FactScore and DecompScore. QA-Noun thus complements the broader QA-based semantic framework, forming a comprehensive and scalable approach to fine-grained semantic decomposition for cross-text alignment.
QAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Dec 10, 2024
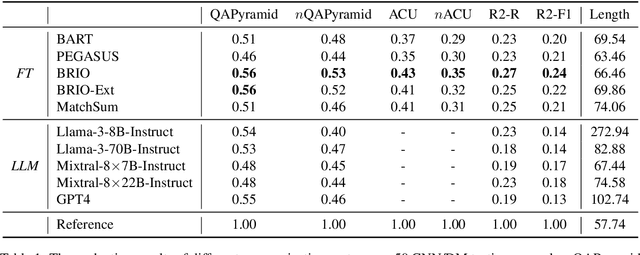
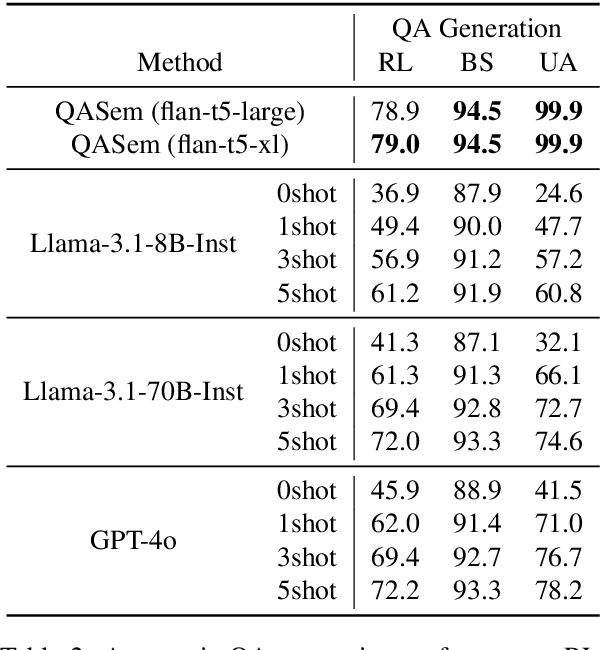
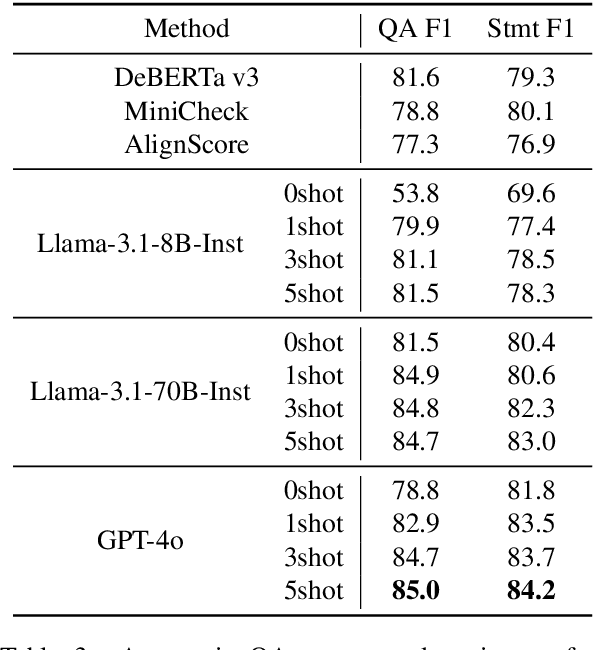
How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.
Explicating the Implicit: Argument Detection Beyond Sentence Boundaries
Aug 08, 2024



Detecting semantic arguments of a predicate word has been conventionally modeled as a sentence-level task. The typical reader, however, perfectly interprets predicate-argument relations in a much wider context than just the sentence where the predicate was evoked. In this work, we reformulate the problem of argument detection through textual entailment to capture semantic relations across sentence boundaries. We propose a method that tests whether some semantic relation can be inferred from a full passage by first encoding it into a simple and standalone proposition and then testing for entailment against the passage. Our method does not require direct supervision, which is generally absent due to dataset scarcity, but instead builds on existing NLI and sentence-level SRL resources. Such a method can potentially explicate pragmatically understood relations into a set of explicit sentences. We demonstrate it on a recent document-level benchmark, outperforming some supervised methods and contemporary language models.
QASem Parsing: Text-to-text Modeling of QA-based Semantics
May 23, 2022
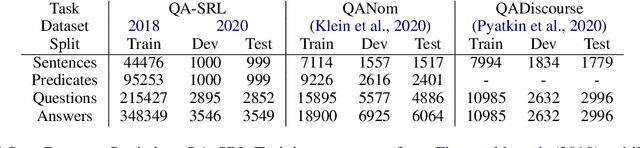
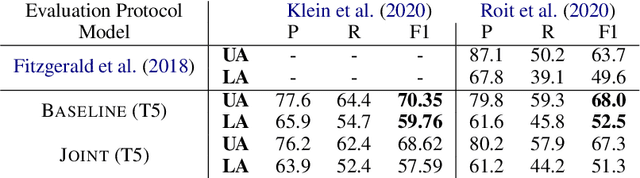
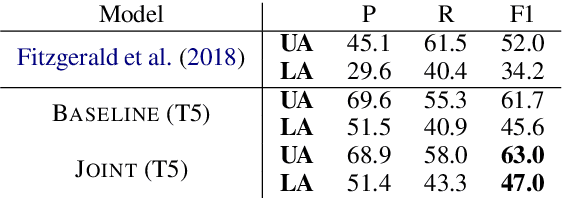
Several recent works have suggested to represent semantic relations with questions and answers, decomposing textual information into separate interrogative natural language statements. In this paper, we consider three QA-based semantic tasks - namely, QA-SRL, QANom and QADiscourse, each targeting a certain type of predication - and propose to regard them as jointly providing a comprehensive representation of textual information. To promote this goal, we investigate how to best utilize the power of sequence-to-sequence (seq2seq) pre-trained language models, within the unique setup of semi-structured outputs, consisting of an unordered set of question-answer pairs. We examine different input and output linearization strategies, and assess the effect of multitask learning and of simple data augmentation techniques in the setting of imbalanced training data. Consequently, we release the first unified QASem parsing tool, practical for downstream applications who can benefit from an explicit, QA-based account of information units in a text.
QA-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions
Sep 26, 2021
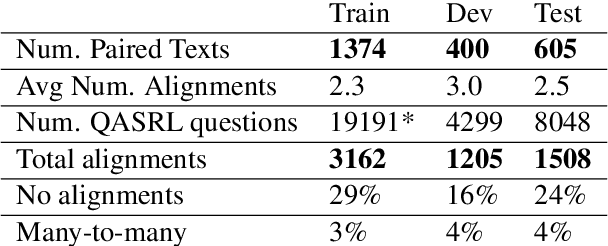
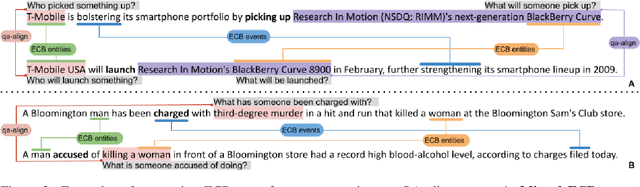
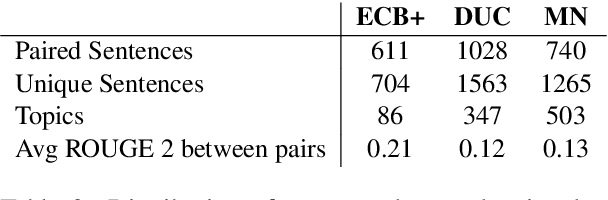
Multi-text applications, such as multi-document summarization, are typically required to model redundancies across related texts. Current methods confronting consolidation struggle to fuse overlapping information. In order to explicitly represent content overlap, we propose to align predicate-argument relations across texts, providing a potential scaffold for information consolidation. We go beyond clustering coreferring mentions, and instead model overlap with respect to redundancy at a propositional level, rather than merely detecting shared referents. Our setting exploits QA-SRL, utilizing question-answer pairs to capture predicate-argument relations, facilitating laymen annotation of cross-text alignments. We employ crowd-workers for constructing a dataset of QA-based alignments, and present a baseline QA alignment model trained over our dataset. Analyses show that our new task is semantically challenging, capturing content overlap beyond lexical similarity and complements cross-document coreference with proposition-level links, offering potential use for downstream tasks.
QADiscourse -- Discourse Relations as QA Pairs: Representation, Crowdsourcing and Baselines
Oct 06, 2020
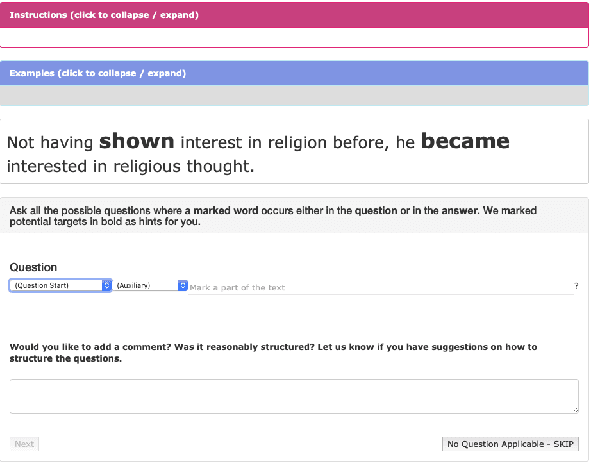

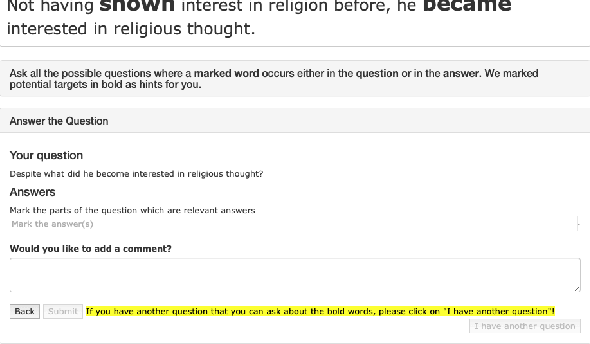
Discourse relations describe how two propositions relate to one another, and identifying them automatically is an integral part of natural language understanding. However, annotating discourse relations typically requires expert annotators. Recently, different semantic aspects of a sentence have been represented and crowd-sourced via question-and-answer (QA) pairs. This paper proposes a novel representation of discourse relations as QA pairs, which in turn allows us to crowd-source wide-coverage data annotated with discourse relations, via an intuitively appealing interface for composing such questions and answers. Based on our proposed representation, we collect a novel and wide-coverage QADiscourse dataset, and present baseline algorithms for predicting QADiscourse relations.
Crowdsourcing a High-Quality Gold Standard for QA-SRL
Nov 08, 2019
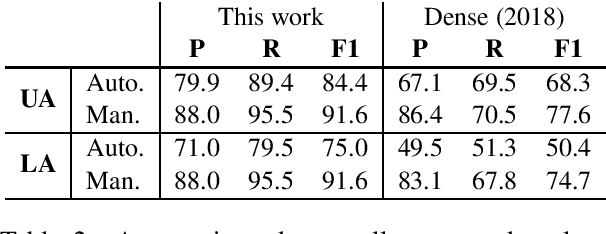
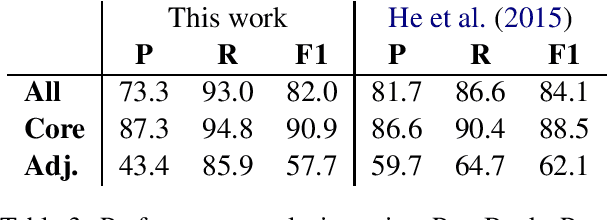
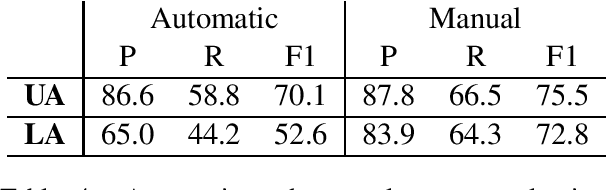
Question-answer driven Semantic Role Labeling (QA-SRL) has been proposed as an attractive open and natural form of SRL, easily crowdsourceable for new corpora. Recently, a large-scale QA-SRL corpus and a trained parser were released, accompanied by a densely annotated dataset for evaluation. Trying to replicate the QA-SRL annotation and evaluation scheme for new texts, we observed that the resulting annotations were lacking in quality and coverage, particularly insufficient for creating gold standards for evaluation. In this paper, we present an improved QA-SRL annotation protocol, involving crowd-worker selection and training, followed by data consolidation. Applying this process, we release a new gold evaluation dataset for QA-SRL, yielding more consistent annotations and greater coverage. We believe that our new annotation protocol and gold standard will facilitate future replicable research of natural semantic annotations.