 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAPyramid: Fine-grained Evaluation of Content Selection for Text Summarization
Paper and Code

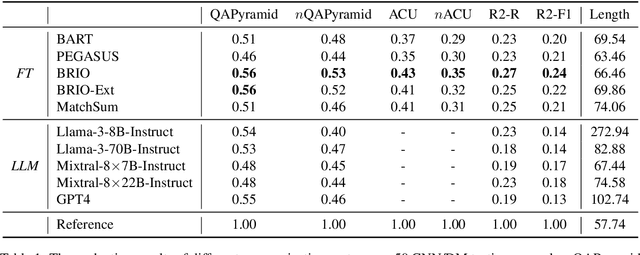
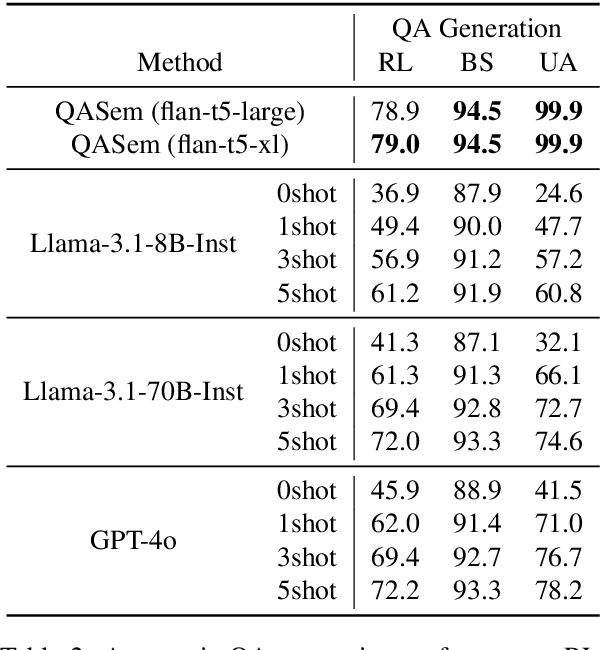
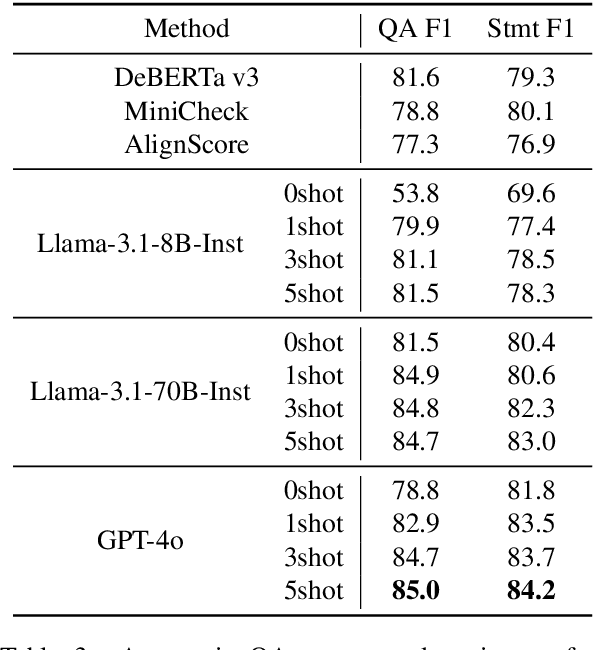
How to properly conduct human evaluations for text summarization is a longstanding challenge. The Pyramid human evaluation protocol, which assesses content selection by breaking the reference summary into sub-units and verifying their presence in the system summary, has been widely adopted. However, it suffers from a lack of systematicity in the definition and granularity of the sub-units. We address these problems by proposing QAPyramid, which decomposes each reference summary into finer-grained question-answer (QA) pairs according to the QA-SRL framework. We collect QA-SRL annotations for reference summaries from CNN/DM and evaluate 10 summarization systems, resulting in 8.9K QA-level annotations. We show that, compared to Pyramid, QAPyramid provides more systematic and fine-grained content selection evaluation while maintaining high inter-annotator agreement without needing expert annotations. Furthermore, we propose metrics that automate the evaluation pipeline and achieve higher correlations with QAPyramid than other widely adopted metrics, allowing future work to accurately and efficiently benchmark summarization systems.