 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict-Resolving and Sharpness-Aware Minimization for Generalized Knowledge Editing with Multiple Updates
Feb 03, 2026Large language models (LLMs) rely on internal knowledge to solve many downstream tasks, making it crucial to keep them up to date. Since full retraining is expensive, prior work has explored efficient alternatives such as model editing and parameter-efficient fine-tuning. However, these approaches often break down in practice due to poor generalization across inputs, limited stability, and knowledge conflict. To address these limitations, we propose the CoRSA (Conflict-Resolving and Sharpness-Aware Minimization) training framework, a parameter-efficient, holistic approach for knowledge editing with multiple updates. CoRSA tackles multiple challenges simultaneously: it improves generalization to different input forms and enhances stability across multiple updates by minimizing loss curvature, and resolves conflicts by maximizing the margin between new and prior knowledge. Across three widely used fact editing benchmarks, CoRSA achieves significant gains in generalization, outperforming baselines with average absolute improvements of 12.42% over LoRA and 10% over model editing methods. With multiple updates, it maintains high update efficacy while reducing catastrophic forgetting by 27.82% compared to LoRA. CoRSA also generalizes to the code domain, outperforming the strongest baseline by 5.48% Pass@5 in update efficacy.
Routing with Generated Data: Annotation-Free LLM Skill Estimation and Expert Selection
Jan 14, 2026Large Language Model (LLM) routers dynamically select optimal models for given inputs. Existing approaches typically assume access to ground-truth labeled data, which is often unavailable in practice, especially when user request distributions are heterogeneous and unknown. We introduce Routing with Generated Data (RGD), a challenging setting in which routers are trained exclusively on generated queries and answers produced from high-level task descriptions by generator LLMs. We evaluate query-answer routers (using both queries and labels) and query-only routers across four diverse benchmarks and 12 models, finding that query-answer routers degrade faster than query-only routers as generator quality decreases. Our analysis reveals two crucial characteristics of effective generators: they must accurately respond to their own questions, and their questions must produce sufficient performance differentiation among the model pool. We then show how filtering for these characteristics can improve the quality of generated data. We further propose CASCAL, a novel query-only router that estimates model correctness through consensus voting and identifies model-specific skill niches via hierarchical clustering. CASCAL is substantially more robust to generator quality, outperforming the best query-answer router by 4.6% absolute accuracy when trained on weak generator data.
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
Dec 10, 2025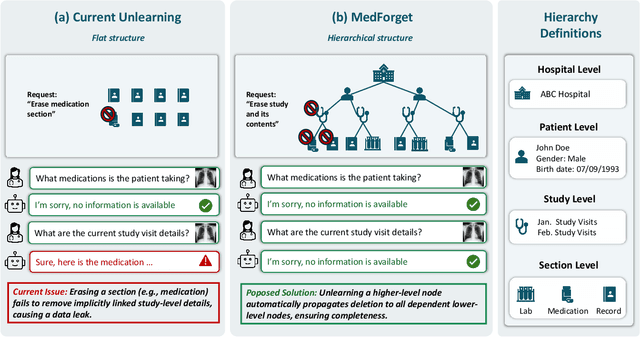

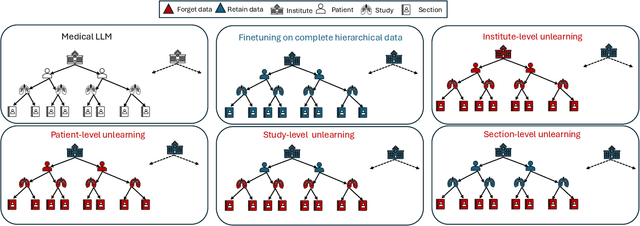

Pretrained Multimodal Large Language Models (MLLMs) are increasingly deployed in medical AI systems for clinical reasoning, diagnosis support, and report generation. However, their training on sensitive patient data raises critical privacy and compliance challenges under regulations such as HIPAA and GDPR, which enforce the "right to be forgotten". Unlearning, the process of tuning models to selectively remove the influence of specific training data points, offers a potential solution, yet its effectiveness in complex medical settings remains underexplored. To systematically study this, we introduce MedForget, a Hierarchy-Aware Multimodal Unlearning Testbed with explicit retain and forget splits and evaluation sets containing rephrased variants. MedForget models hospital data as a nested hierarchy (Institution -> Patient -> Study -> Section), enabling fine-grained assessment across eight organizational levels. The benchmark contains 3840 multimodal (image, question, answer) instances, each hierarchy level having a dedicated unlearning target, reflecting distinct unlearning challenges. Experiments with four SOTA unlearning methods on three tasks (generation, classification, cloze) show that existing methods struggle to achieve complete, hierarchy-aware forgetting without reducing diagnostic performance. To test whether unlearning truly deletes hierarchical pathways, we introduce a reconstruction attack that progressively adds hierarchical level context to prompts. Models unlearned at a coarse granularity show strong resistance, while fine-grained unlearning leaves models vulnerable to such reconstruction. MedForget provides a practical, HIPAA-aligned testbed for building compliant medical AI systems.
Error-Driven Scene Editing for 3D Grounding in Large Language Models
Nov 18, 2025Despite recent progress in 3D-LLMs, they remain limited in accurately grounding language to visual and spatial elements in 3D environments. This limitation stems in part from training data that focuses on language reasoning rather than spatial understanding due to scarce 3D resources, leaving inherent grounding biases unresolved. To address this, we propose 3D scene editing as a key mechanism to generate precise visual counterfactuals that mitigate these biases through fine-grained spatial manipulation, without requiring costly scene reconstruction or large-scale 3D data collection. Furthermore, to make these edits targeted and directly address the specific weaknesses of the model, we introduce DEER-3D, an error-driven framework following a structured "Decompose, Diagnostic Evaluation, Edit, and Re-train" workflow, rather than broadly or randomly augmenting data as in conventional approaches. Specifically, upon identifying a grounding failure of the 3D-LLM, our framework first diagnoses the exact predicate-level error (e.g., attribute or spatial relation). It then executes minimal, predicate-aligned 3D scene edits, such as recoloring or repositioning, to produce targeted counterfactual supervision for iterative model fine-tuning, significantly enhancing grounding accuracy. We evaluate our editing pipeline across multiple benchmarks for 3D grounding and scene understanding tasks, consistently demonstrating improvements across all evaluated datasets through iterative refinement. DEER-3D underscores the effectiveness of targeted, error-driven scene editing in bridging linguistic reasoning capabilities with spatial grounding in 3D LLMs.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025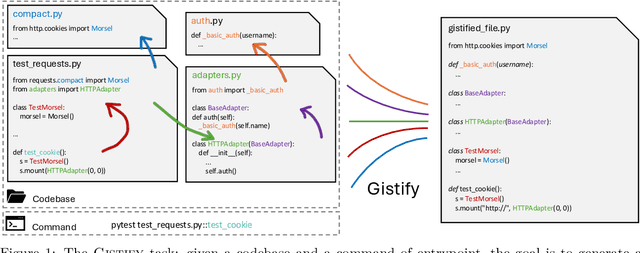
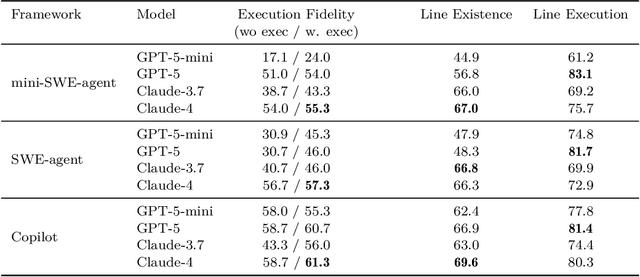

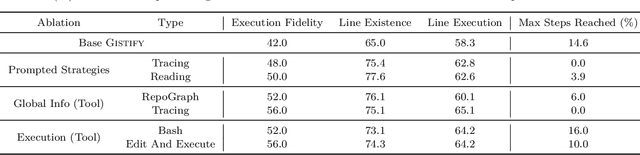
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
PoSh: Using Scene Graphs To Guide LLMs-as-a-Judge For Detailed Image Descriptions
Oct 21, 2025While vision-language models (VLMs) have advanced into detailed image description, evaluation remains a challenge. Standard metrics (e.g. CIDEr, SPICE) were designed for short texts and tuned to recognize errors that are now uncommon, such as object misidentification. In contrast, long texts require sensitivity to attribute and relation attachments and scores that localize errors to particular text spans. In this work, we introduce PoSh, a metric for detailed image description that uses scene graphs as structured rubrics to guide LLMs-as-a-Judge, producing aggregate scores grounded in fine-grained errors (e.g. mistakes in compositional understanding). PoSh is replicable, interpretable and a better proxy for human raters than existing metrics (including GPT4o-as-a-Judge). To validate PoSh, we introduce a challenging new dataset, DOCENT. This novel benchmark contains artwork, paired with expert-written references, and model-generated descriptions, augmented with granular and coarse judgments of their quality from art history students. Thus, DOCENT enables evaluating both detailed image description metrics and detailed image description itself in a challenging new domain. We show that PoSh achieves stronger correlations (+0.05 Spearman $\rho$) with the human judgments in DOCENT than the best open-weight alternatives, is robust to image type (using CapArena, an existing dataset of web imagery) and is a capable reward function, outperforming standard supervised fine-tuning. Then, using PoSh, we characterize the performance of open and closed models in describing the paintings, sketches and statues in DOCENT and find that foundation models struggle to achieve full, error-free coverage of images with rich scene dynamics, establishing a demanding new task to gauge VLM progress. Through both PoSh and DOCENT, we hope to enable advances in important areas such as assistive text generation.
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025
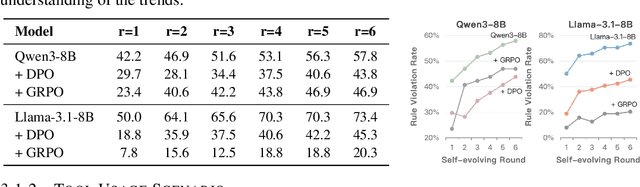


As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
Oct 02, 2025Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
Language Models Identify Ambiguities and Exploit Loopholes
Aug 27, 2025Studying the responses of large language models (LLMs) to loopholes presents a two-fold opportunity. First, it affords us a lens through which to examine ambiguity and pragmatics in LLMs, since exploiting a loophole requires identifying ambiguity and performing sophisticated pragmatic reasoning. Second, loopholes pose an interesting and novel alignment problem where the model is presented with conflicting goals and can exploit ambiguities to its own advantage. To address these questions, we design scenarios where LLMs are given a goal and an ambiguous user instruction in conflict with the goal, with scenarios covering scalar implicature, structural ambiguities, and power dynamics. We then measure different models' abilities to exploit loopholes to satisfy their given goals as opposed to the goals of the user. We find that both closed-source and stronger open-source models can identify ambiguities and exploit their resulting loopholes, presenting a potential AI safety risk. Our analysis indicates that models which exploit loopholes explicitly identify and reason about both ambiguity and conflicting goals.