 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified SHAP: Provable Bounds for Exact Shapley Values of Neural Networks
May 22, 2026Shapley additive explanations (SHAP) are widely recognised as computationally intractable for neural networks, since they induce an exponential search space over the input features. In this work, we take a first step towards scaling exact SHAP computation to larger search spaces by introducing an algorithm that leverages recent advances in neural network verification to compute arbitrarily tight exact lower and upper bounds on SHAP values for neural networks, ultimately recovering the exact SHAP values. We demonstrate that our approach scales to orders of magnitude larger search spaces than state-of-the-art exact methods. This provides an important first step towards exact SHAP computation and establishes a principled cornerstone for evaluating statistical approximation methods on larger search spaces.
FAME: Formal Abstract Minimal Explanation for Neural Networks
Mar 11, 2026We propose FAME (Formal Abstract Minimal Explanations), a new class of abductive explanations grounded in abstract interpretation. FAME is the first method to scale to large neural networks while reducing explanation size. Our main contribution is the design of dedicated perturbation domains that eliminate the need for traversal order. FAME progressively shrinks these domains and leverages LiRPA-based bounds to discard irrelevant features, ultimately converging to a formal abstract minimal explanation. To assess explanation quality, we introduce a procedure that measures the worst-case distance between an abstract minimal explanation and a true minimal explanation. This procedure combines adversarial attacks with an optional VERIX+ refinement step. We benchmark FAME against VERIX+ and demonstrate consistent gains in both explanation size and runtime on medium- to large-scale neural networks.
Provably Explaining Neural Additive Models
Feb 19, 2026Despite significant progress in post-hoc explanation methods for neural networks, many remain heuristic and lack provable guarantees. A key approach for obtaining explanations with provable guarantees is by identifying a cardinally-minimal subset of input features which by itself is provably sufficient to determine the prediction. However, for standard neural networks, this task is often computationally infeasible, as it demands a worst-case exponential number of verification queries in the number of input features, each of which is NP-hard. In this work, we show that for Neural Additive Models (NAMs), a recent and more interpretable neural network family, we can efficiently generate explanations with such guarantees. We present a new model-specific algorithm for NAMs that generates provably cardinally-minimal explanations using only a logarithmic number of verification queries in the number of input features, after a parallelized preprocessing step with logarithmic runtime in the required precision is applied to each small univariate NAM component. Our algorithm not only makes the task of obtaining cardinally-minimal explanations feasible, but even outperforms existing algorithms designed to find the relaxed variant of subset-minimal explanations - which may be larger and less informative but easier to compute - despite our algorithm solving a much more difficult task. Our experiments demonstrate that, compared to previous algorithms, our approach provides provably smaller explanations than existing works and substantially reduces the computation time. Moreover, we show that our generated provable explanations offer benefits that are unattainable by standard sampling-based techniques typically used to interpret NAMs.
Formal Mechanistic Interpretability: Automated Circuit Discovery with Provable Guarantees
Feb 18, 2026*Automated circuit discovery* is a central tool in mechanistic interpretability for identifying the internal components of neural networks responsible for specific behaviors. While prior methods have made significant progress, they typically depend on heuristics or approximations and do not offer provable guarantees over continuous input domains for the resulting circuits. In this work, we leverage recent advances in neural network verification to propose a suite of automated algorithms that yield circuits with *provable guarantees*. We focus on three types of guarantees: (1) *input domain robustness*, ensuring the circuit agrees with the model across a continuous input region; (2) *robust patching*, certifying circuit alignment under continuous patching perturbations; and (3) *minimality*, formalizing and capturing a wide array of various notions of succinctness. Interestingly, we uncover a diverse set of novel theoretical connections among these three families of guarantees, with critical implications for the convergence of our algorithms. Finally, we conduct experiments with state-of-the-art verifiers on various vision models, showing that our algorithms yield circuits with substantially stronger robustness guarantees than standard circuit discovery methods, establishing a principled foundation for provable circuit discovery.
SHAP Meets Tensor Networks: Provably Tractable Explanations with Parallelism
Oct 24, 2025Although Shapley additive explanations (SHAP) can be computed in polynomial time for simple models like decision trees, they unfortunately become NP-hard to compute for more expressive black-box models like neural networks - where generating explanations is often most critical. In this work, we analyze the problem of computing SHAP explanations for *Tensor Networks (TNs)*, a broader and more expressive class of models than those for which current exact SHAP algorithms are known to hold, and which is widely used for neural network abstraction and compression. First, we introduce a general framework for computing provably exact SHAP explanations for general TNs with arbitrary structures. Interestingly, we show that, when TNs are restricted to a *Tensor Train (TT)* structure, SHAP computation can be performed in *poly-logarithmic* time using *parallel* computation. Thanks to the expressiveness power of TTs, this complexity result can be generalized to many other popular ML models such as decision trees, tree ensembles, linear models, and linear RNNs, therefore tightening previously reported complexity results for these families of models. Finally, by leveraging reductions of binarized neural networks to Tensor Network representations, we demonstrate that SHAP computation can become *efficiently tractable* when the network's *width* is fixed, while it remains computationally hard even with constant *depth*. This highlights an important insight: for this class of models, width - rather than depth - emerges as the primary computational bottleneck in SHAP computation.
Explaining, Fast and Slow: Abstraction and Refinement of Provable Explanations
Jun 10, 2025Despite significant advancements in post-hoc explainability techniques for neural networks, many current methods rely on heuristics and do not provide formally provable guarantees over the explanations provided. Recent work has shown that it is possible to obtain explanations with formal guarantees by identifying subsets of input features that are sufficient to determine that predictions remain unchanged using neural network verification techniques. Despite the appeal of these explanations, their computation faces significant scalability challenges. In this work, we address this gap by proposing a novel abstraction-refinement technique for efficiently computing provably sufficient explanations of neural network predictions. Our method abstracts the original large neural network by constructing a substantially reduced network, where a sufficient explanation of the reduced network is also provably sufficient for the original network, hence significantly speeding up the verification process. If the explanation is in sufficient on the reduced network, we iteratively refine the network size by gradually increasing it until convergence. Our experiments demonstrate that our approach enhances the efficiency of obtaining provably sufficient explanations for neural network predictions while additionally providing a fine-grained interpretation of the network's predictions across different abstraction levels.
What makes an Ensemble (Un) Interpretable?
Jun 09, 2025Ensemble models are widely recognized in the ML community for their limited interpretability. For instance, while a single decision tree is considered interpretable, ensembles of trees (e.g., boosted trees) are often treated as black-boxes. Despite this folklore recognition, there remains a lack of rigorous mathematical understanding of what particularly makes an ensemble (un)-interpretable, including how fundamental factors like the (1) *number*, (2) *size*, and (3) *type* of base models influence its interpretability. In this work, we seek to bridge this gap by applying concepts from computational complexity theory to study the challenges of generating explanations for various ensemble configurations. Our analysis uncovers nuanced complexity patterns influenced by various factors. For example, we demonstrate that under standard complexity assumptions like P$\neq$NP, interpreting ensembles remains intractable even when base models are of constant size. Surprisingly, the complexity changes drastically with the number of base models: small ensembles of decision trees are efficiently interpretable, whereas interpreting ensembles with even a constant number of linear models remains intractable. We believe that our findings provide a more robust foundation for understanding the interpretability of ensembles, emphasizing the benefits of examining it through a computational complexity lens.
CLATTER: Comprehensive Entailment Reasoning for Hallucination Detection
Jun 05, 2025A common approach to hallucination detection casts it as a natural language inference (NLI) task, often using LLMs to classify whether the generated text is entailed by corresponding reference texts. Since entailment classification is a complex reasoning task, one would expect that LLMs could benefit from generating an explicit reasoning process, as in CoT reasoning or the explicit ``thinking'' of recent reasoning models. In this work, we propose that guiding such models to perform a systematic and comprehensive reasoning process -- one that both decomposes the text into smaller facts and also finds evidence in the source for each fact -- allows models to execute much finer-grained and accurate entailment decisions, leading to increased performance. To that end, we define a 3-step reasoning process, consisting of (i) claim decomposition, (ii) sub-claim attribution and entailment classification, and (iii) aggregated classification, showing that such guided reasoning indeed yields improved hallucination detection. Following this reasoning framework, we introduce an analysis scheme, consisting of several metrics that measure the quality of the intermediate reasoning steps, which provided additional empirical evidence for the improved quality of our guided reasoning scheme.
On the Computational Tractability of the (Many) Shapley Values
Feb 17, 2025Recent studies have examined the computational complexity of computing Shapley additive explanations (also known as SHAP) across various models and distributions, revealing their tractability or intractability in different settings. However, these studies primarily focused on a specific variant called Conditional SHAP, though many other variants exist and address different limitations. In this work, we analyze the complexity of computing a much broader range of such variants, including Conditional, Interventional, and Baseline SHAP, while exploring both local and global computations. We show that both local and global Interventional and Baseline SHAP can be computed in polynomial time for various ML models under Hidden Markov Model distributions, extending popular algorithms such as TreeSHAP beyond empirical distributions. On the downside, we prove intractability results for these variants over a wide range of neural networks and tree ensembles. We believe that our results emphasize the intricate diversity of computing Shapley values, demonstrating how their complexity is substantially shaped by both the specific SHAP variant, the model type, and the distribution.
Explain Yourself, Briefly! Self-Explaining Neural Networks with Concise Sufficient Reasons
Feb 05, 2025

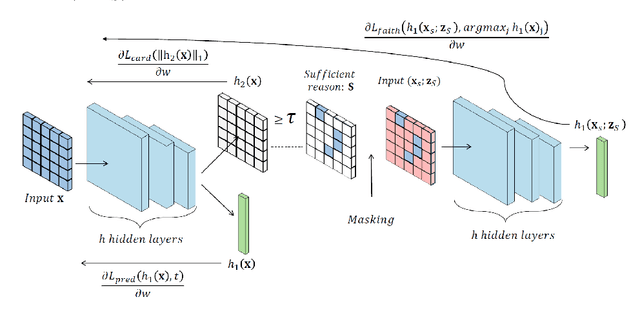
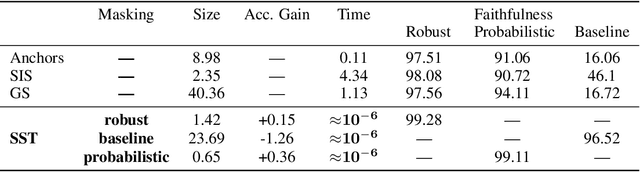
Minimal sufficient reasons represent a prevalent form of explanation - the smallest subset of input features which, when held constant at their corresponding values, ensure that the prediction remains unchanged. Previous post-hoc methods attempt to obtain such explanations but face two main limitations: (1) Obtaining these subsets poses a computational challenge, leading most scalable methods to converge towards suboptimal, less meaningful subsets; (2) These methods heavily rely on sampling out-of-distribution input assignments, potentially resulting in counterintuitive behaviors. To tackle these limitations, we propose in this work a self-supervised training approach, which we term *sufficient subset training* (SST). Using SST, we train models to generate concise sufficient reasons for their predictions as an integral part of their output. Our results indicate that our framework produces succinct and faithful subsets substantially more efficiently than competing post-hoc methods, while maintaining comparable predictive performance.