 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dynamic Shielding for Parametric Safety Specifications
May 28, 2025Shielding has emerged as a promising approach for ensuring safety of AI-controlled autonomous systems. The algorithmic goal is to compute a shield, which is a runtime safety enforcement tool that needs to monitor and intervene the AI controller's actions if safety could be compromised otherwise. Traditional shields are designed statically for a specific safety requirement. Therefore, if the safety requirement changes at runtime due to changing operating conditions, the shield needs to be recomputed from scratch, causing delays that could be fatal. We introduce dynamic shields for parametric safety specifications, which are succinctly represented sets of all possible safety specifications that may be encountered at runtime. Our dynamic shields are statically designed for a given safety parameter set, and are able to dynamically adapt as the true safety specification (permissible by the parameters) is revealed at runtime. The main algorithmic novelty lies in the dynamic adaptation procedure, which is a simple and fast algorithm that utilizes known features of standard safety shields, like maximal permissiveness. We report experimental results for a robot navigation problem in unknown territories, where the safety specification evolves as new obstacles are discovered at runtime. In our experiments, the dynamic shields took a few minutes for their offline design, and took between a fraction of a second and a few seconds for online adaptation at each step, whereas the brute-force online recomputation approach was up to 5 times slower.
Adapting World Models with Latent-State Dynamics Residuals
Apr 03, 2025Simulation-to-reality reinforcement learning (RL) faces the critical challenge of reconciling discrepancies between simulated and real-world dynamics, which can severely degrade agent performance. A promising approach involves learning corrections to simulator forward dynamics represented as a residual error function, however this operation is impractical with high-dimensional states such as images. To overcome this, we propose ReDRAW, a latent-state autoregressive world model pretrained in simulation and calibrated to target environments through residual corrections of latent-state dynamics rather than of explicit observed states. Using this adapted world model, ReDRAW enables RL agents to be optimized with imagined rollouts under corrected dynamics and then deployed in the real world. In multiple vision-based MuJoCo domains and a physical robot visual lane-following task, ReDRAW effectively models changes to dynamics and avoids overfitting in low data regimes where traditional transfer methods fail.
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Oct 02, 2024



While Deep Reinforcement Learning (DRL) has achieved remarkable success across various domains, it remains vulnerable to occasional catastrophic failures without additional safeguards. One effective solution to prevent these failures is to use a shield that validates and adjusts the agent's actions to ensure compliance with a provided set of safety specifications. For real-life robot domains, it is desirable to be able to define such safety specifications over continuous state and action spaces to accurately account for system dynamics and calculate new safe actions that minimally alter the agent's output. In this paper, we propose the first shielding approach to automatically guarantee the realizability of safety requirements for continuous state and action spaces. Realizability is an essential property that confirms the shield will always be able to generate a safe action for any state in the environment. We formally prove that realizability can also be verified with a stateful shield, enabling the incorporation of non-Markovian safety requirements. Finally, we demonstrate the effectiveness of our approach in ensuring safety without compromising policy accuracy by applying it to a navigation problem and a multi-agent particle environment.
Verification-Guided Shielding for Deep Reinforcement Learning
Jun 10, 2024



In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, which limits their deployment in safety-critical domains. As a result, various methods have been put forth to address this issue by providing formal safety guarantees. Two main approaches include shielding and verification. While shielding ensures the safe behavior of the policy by employing an external online component (i.e., a ``shield'') that overruns potentially dangerous actions, this approach has a significant computational cost as the shield must be invoked at runtime to validate every decision. On the other hand, verification is an offline process that can identify policies that are unsafe, prior to their deployment, yet, without providing alternative actions when such a policy is deemed unsafe. In this work, we present verification-guided shielding -- a novel approach that bridges the DRL reliability gap by integrating these two methods. Our approach combines both formal and probabilistic verification tools to partition the input domain into safe and unsafe regions. In addition, we employ clustering and symbolic representation procedures that compress the unsafe regions into a compact representation. This, in turn, allows to temporarily activate the shield solely in (potentially) unsafe regions, in an efficient manner. Our novel approach allows to significantly reduce runtime overhead while still preserving formal safety guarantees. We extensively evaluate our approach on two benchmarks from the robotic navigation domain, as well as provide an in-depth analysis of its scalability and completeness.
Shield Synthesis for LTL Modulo Theories
Jun 06, 2024



In recent years, Machine Learning (ML) models have achieved remarkable success in various domains. However, these models also tend to demonstrate unsafe behaviors, precluding their deployment in safety-critical systems. To cope with this issue, ample research focuses on developing methods that guarantee the safe behaviour of a given ML model. A prominent example is shielding which incorporates an external component (a "shield") that blocks unwanted behavior. Despite significant progress, shielding suffers from a main setback: it is currently geared towards properties encoded solely in propositional logics (e.g., LTL) and is unsuitable for richer logics. This, in turn, limits the widespread applicability of shielding in many real-world systems. In this work, we address this gap, and extend shielding to LTL modulo theories, by building upon recent advances in reactive synthesis modulo theories. This allowed us to develop a novel approach for generating shields conforming to complex safety specifications in these more expressive, logics. We evaluated our shields and demonstrate their ability to handle rich data with temporal dynamics. To the best of our knowledge, this is the first approach for synthesizing shields for such expressivity.
Aquatic Navigation: A Challenging Benchmark for Deep Reinforcement Learning
May 30, 2024



An exciting and promising frontier for Deep Reinforcement Learning (DRL) is its application to real-world robotic systems. While modern DRL approaches achieved remarkable successes in many robotic scenarios (including mobile robotics, surgical assistance, and autonomous driving) unpredictable and non-stationary environments can pose critical challenges to such methods. These features can significantly undermine fundamental requirements for a successful training process, such as the Markovian properties of the transition model. To address this challenge, we propose a new benchmarking environment for aquatic navigation using recent advances in the integration between game engines and DRL. In more detail, we show that our benchmarking environment is problematic even for state-of-the-art DRL approaches that may struggle to generate reliable policies in terms of generalization power and safety. Specifically, we focus on PPO, one of the most widely accepted algorithms, and we propose advanced training techniques (such as curriculum learning and learnable hyperparameters). Our extensive empirical evaluation shows that a well-designed combination of these ingredients can achieve promising results. Our simulation environment and training baselines are freely available to facilitate further research on this open problem and encourage collaboration in the field.
Analyzing Adversarial Inputs in Deep Reinforcement Learning
Feb 07, 2024In recent years, Deep Reinforcement Learning (DRL) has become a popular paradigm in machine learning due to its successful applications to real-world and complex systems. However, even the state-of-the-art DRL models have been shown to suffer from reliability concerns -- for example, their susceptibility to adversarial inputs, i.e., small and abundant input perturbations that can fool the models into making unpredictable and potentially dangerous decisions. This drawback limits the deployment of DRL systems in safety-critical contexts, where even a small error cannot be tolerated. In this work, we present a comprehensive analysis of the characterization of adversarial inputs, through the lens of formal verification. Specifically, we introduce a novel metric, the Adversarial Rate, to classify models based on their susceptibility to such perturbations, and present a set of tools and algorithms for its computation. Our analysis empirically demonstrates how adversarial inputs can affect the safety of a given DRL system with respect to such perturbations. Moreover, we analyze the behavior of these configurations to suggest several useful practices and guidelines to help mitigate the vulnerability of trained DRL networks.
Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic Guarantees
Aug 18, 2023



Identifying safe areas is a key point to guarantee trust for systems that are based on Deep Neural Networks (DNNs). To this end, we introduce the AllDNN-Verification problem: given a safety property and a DNN, enumerate the set of all the regions of the property input domain which are safe, i.e., where the property does hold. Due to the #P-hardness of the problem, we propose an efficient approximation method called epsilon-ProVe. Our approach exploits a controllable underestimation of the output reachable sets obtained via statistical prediction of tolerance limits, and can provide a tight (with provable probabilistic guarantees) lower estimate of the safe areas. Our empirical evaluation on different standard benchmarks shows the scalability and effectiveness of our method, offering valuable insights for this new type of verification of DNNs.
Formally Explaining Neural Networks within Reactive Systems
Aug 06, 2023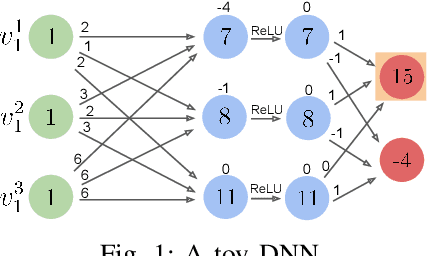
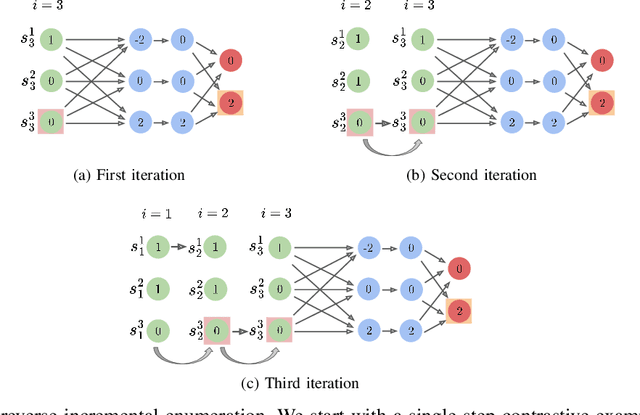
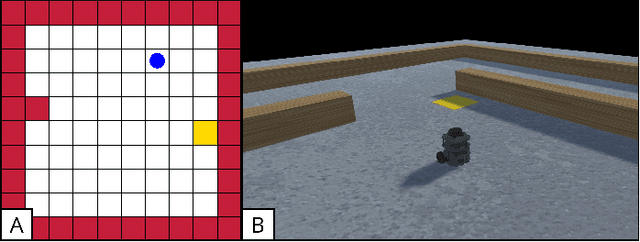
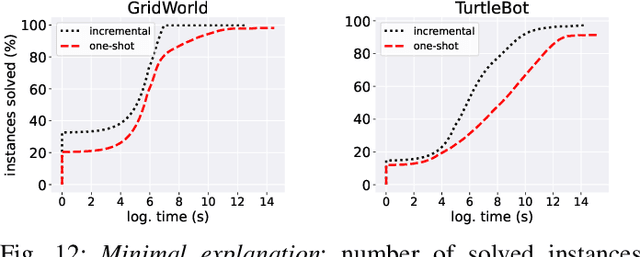
Deep neural networks (DNNs) are increasingly being used as controllers in reactive systems. However, DNNs are highly opaque, which renders it difficult to explain and justify their actions. To mitigate this issue, there has been a surge of interest in explainable AI (XAI) techniques, capable of pinpointing the input features that caused the DNN to act as it did. Existing XAI techniques typically face two limitations: (i) they are heuristic, and do not provide formal guarantees that the explanations are correct; and (ii) they often apply to ``one-shot'' systems, where the DNN is invoked independently of past invocations, as opposed to reactive systems. Here, we begin bridging this gap, and propose a formal DNN-verification-based XAI technique for reasoning about multi-step, reactive systems. We suggest methods for efficiently calculating succinct explanations, by exploiting the system's transition constraints in order to curtail the search space explored by the underlying verifier. We evaluate our approach on two popular benchmarks from the domain of automated navigation; and observe that our methods allow the efficient computation of minimal and minimum explanations, significantly outperforming the state of the art. We also demonstrate that our methods produce formal explanations that are more reliable than competing, non-verification-based XAI techniques.
Constrained Reinforcement Learning and Formal Verification for Safe Colonoscopy Navigation
Mar 16, 2023



The field of robotic Flexible Endoscopes (FEs) has progressed significantly, offering a promising solution to reduce patient discomfort. However, the limited autonomy of most robotic FEs results in non-intuitive and challenging manoeuvres, constraining their application in clinical settings. While previous studies have employed lumen tracking for autonomous navigation, they fail to adapt to the presence of obstructions and sharp turns when the endoscope faces the colon wall. In this work, we propose a Deep Reinforcement Learning (DRL)-based navigation strategy that eliminates the need for lumen tracking. However, the use of DRL methods poses safety risks as they do not account for potential hazards associated with the actions taken. To ensure safety, we exploit a Constrained Reinforcement Learning (CRL) method to restrict the policy in a predefined safety regime. Moreover, we present a model selection strategy that utilises Formal Verification (FV) to choose a policy that is entirely safe before deployment. We validate our approach in a virtual colonoscopy environment and report that out of the 300 trained policies, we could identify three policies that are entirely safe. Our work demonstrates that CRL, combined with model selection through FV, can improve the robustness and safety of robotic behaviour in surgical applications.