 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning Navigation
Apr 30, 2025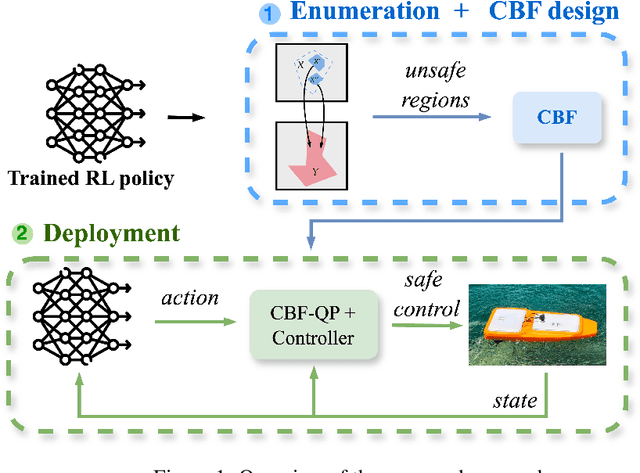


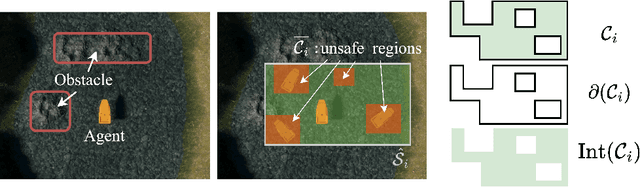
Achieving safe autonomous navigation systems is critical for deploying robots in dynamic and uncertain real-world environments. In this paper, we propose a hierarchical control framework leveraging neural network verification techniques to design control barrier functions (CBFs) and policy correction mechanisms that ensure safe reinforcement learning navigation policies. Our approach relies on probabilistic enumeration to identify unsafe regions of operation, which are then used to construct a safe CBF-based control layer applicable to arbitrary policies. We validate our framework both in simulation and on a real robot, using a standard mobile robot benchmark and a highly dynamic aquatic environmental monitoring task. These experiments demonstrate the ability of the proposed solution to correct unsafe actions while preserving efficient navigation behavior. Our results show the promise of developing hierarchical verification-based systems to enable safe and robust navigation behaviors in complex scenarios.
RL2Grid: Benchmarking Reinforcement Learning in Power Grid Operations
Mar 29, 2025Reinforcement learning (RL) can transform power grid operations by providing adaptive and scalable controllers essential for grid decarbonization. However, existing methods struggle with the complex dynamics, aleatoric uncertainty, long-horizon goals, and hard physical constraints that occur in real-world systems. This paper presents RL2Grid, a benchmark designed in collaboration with power system operators to accelerate progress in grid control and foster RL maturity. Built on a power simulation framework developed by RTE France, RL2Grid standardizes tasks, state and action spaces, and reward structures within a unified interface for a systematic evaluation and comparison of RL approaches. Moreover, we integrate real control heuristics and safety constraints informed by the operators' expertise to ensure RL2Grid aligns with grid operation requirements. We benchmark popular RL baselines on the grid control tasks represented within RL2Grid, establishing reference performance metrics. Our results and discussion highlight the challenges that power grids pose for RL methods, emphasizing the need for novel algorithms capable of handling real-world physical systems.
Safe Multiagent Coordination via Entropic Exploration
Dec 29, 2024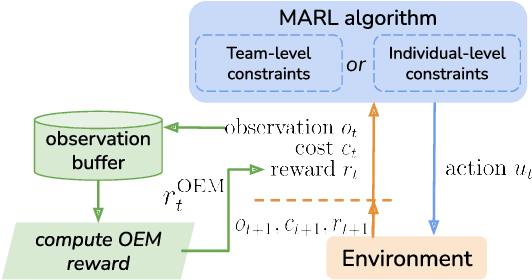
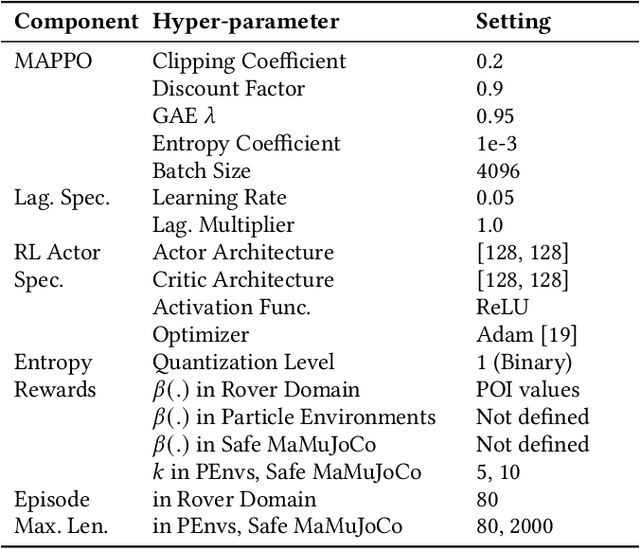
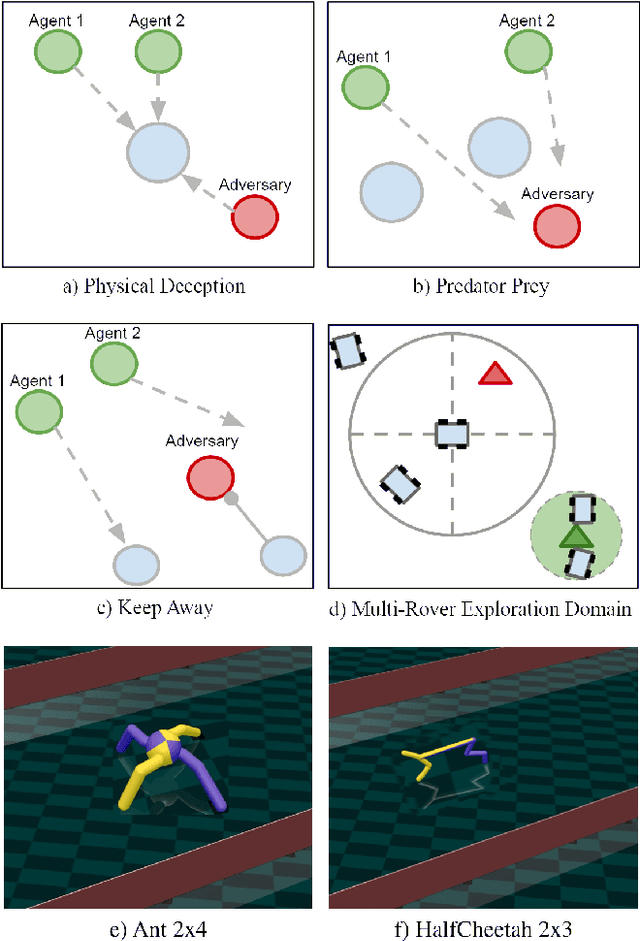
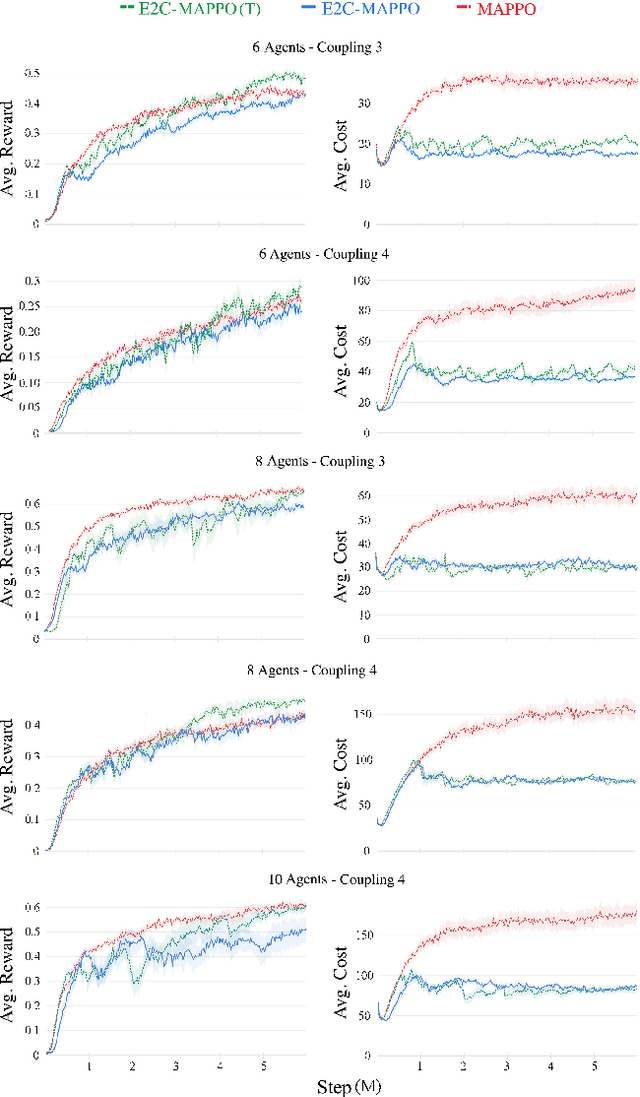
Many real-world multiagent learning problems involve safety concerns. In these setups, typical safe reinforcement learning algorithms constrain agents' behavior, limiting exploration -- a crucial component for discovering effective cooperative multiagent behaviors. Moreover, the multiagent literature typically models individual constraints for each agent and has yet to investigate the benefits of using joint team constraints. In this work, we analyze these team constraints from a theoretical and practical perspective and propose entropic exploration for constrained multiagent reinforcement learning (E2C) to address the exploration issue. E2C leverages observation entropy maximization to incentivize exploration and facilitate learning safe and effective cooperative behaviors. Experiments across increasingly complex domains show that E2C agents match or surpass common unconstrained and constrained baselines in task performance while reducing unsafe behaviors by up to $50\%$.
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Sep 09, 2024



Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
Improving Policy Optimization via $\varepsilon$-Retrain
Jun 12, 2024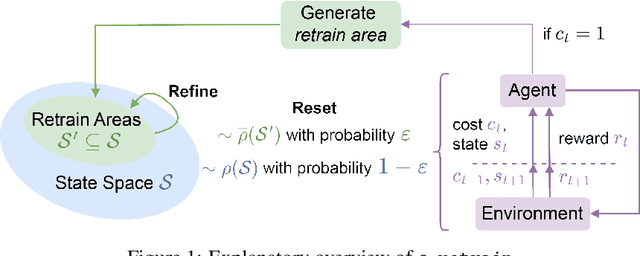
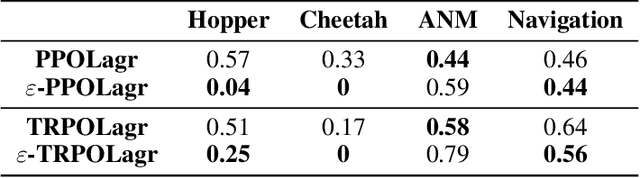
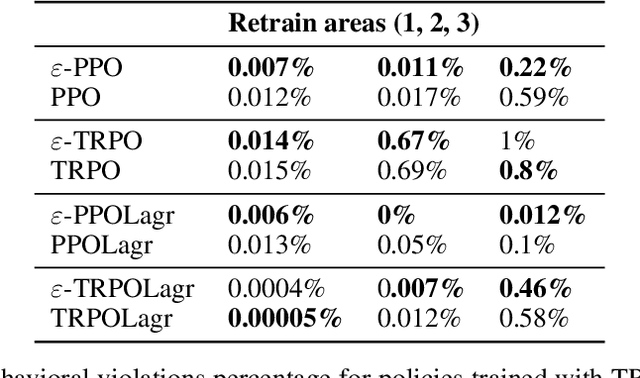
We present $\varepsilon$-retrain, an exploration strategy designed to encourage a behavioral preference while optimizing policies with monotonic improvement guarantees. To this end, we introduce an iterative procedure for collecting retrain areas -- parts of the state space where an agent did not follow the behavioral preference. Our method then switches between the typical uniform restart state distribution and the retrain areas using a decaying factor $\varepsilon$, allowing agents to retrain on situations where they violated the preference. Experiments over hundreds of seeds across locomotion, navigation, and power network tasks show that our method yields agents that exhibit significant performance and sample efficiency improvements. Moreover, we employ formal verification of neural networks to provably quantify the degree to which agents adhere to behavioral preferences.
Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic Guarantees
Aug 18, 2023



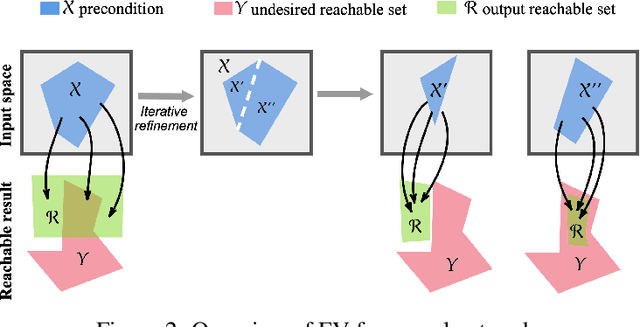
Identifying safe areas is a key point to guarantee trust for systems that are based on Deep Neural Networks (DNNs). To this end, we introduce the AllDNN-Verification problem: given a safety property and a DNN, enumerate the set of all the regions of the property input domain which are safe, i.e., where the property does hold. Due to the #P-hardness of the problem, we propose an efficient approximation method called epsilon-ProVe. Our approach exploits a controllable underestimation of the output reachable sets obtained via statistical prediction of tolerance limits, and can provide a tight (with provable probabilistic guarantees) lower estimate of the safe areas. Our empirical evaluation on different standard benchmarks shows the scalability and effectiveness of our method, offering valuable insights for this new type of verification of DNNs.
Improving Deep Policy Gradients with Value Function Search
Feb 20, 2023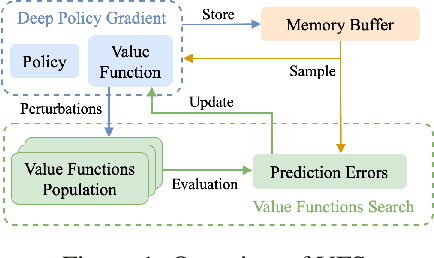
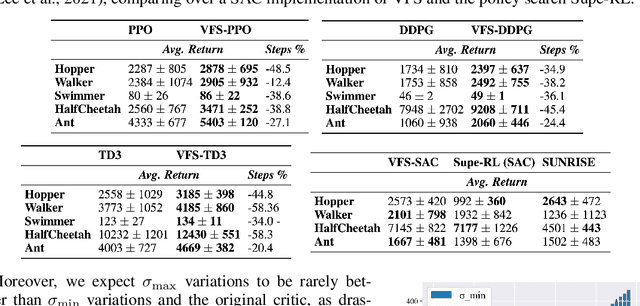
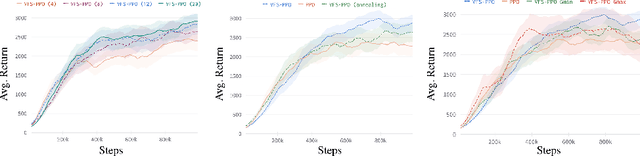
Deep Policy Gradient (PG) algorithms employ value networks to drive the learning of parameterized policies and reduce the variance of the gradient estimates. However, value function approximation gets stuck in local optima and struggles to fit the actual return, limiting the variance reduction efficacy and leading policies to sub-optimal performance. This paper focuses on improving value approximation and analyzing the effects on Deep PG primitives such as value prediction, variance reduction, and correlation of gradient estimates with the true gradient. To this end, we introduce a Value Function Search that employs a population of perturbed value networks to search for a better approximation. Our framework does not require additional environment interactions, gradient computations, or ensembles, providing a computationally inexpensive approach to enhance the supervised learning task on which value networks train. Crucially, we show that improving Deep PG primitives results in improved sample efficiency and policies with higher returns using common continuous control benchmark domains.
Safe Deep Reinforcement Learning by Verifying Task-Level Properties
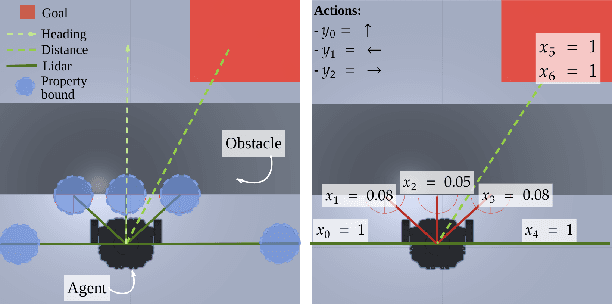
Feb 20, 2023Cost functions are commonly employed in Safe Deep Reinforcement Learning (DRL). However, the cost is typically encoded as an indicator function due to the difficulty of quantifying the risk of policy decisions in the state space. Such an encoding requires the agent to visit numerous unsafe states to learn a cost-value function to drive the learning process toward safety. Hence, increasing the number of unsafe interactions and decreasing sample efficiency. In this paper, we investigate an alternative approach that uses domain knowledge to quantify the risk in the proximity of such states by defining a violation metric. This metric is computed by verifying task-level properties, shaped as input-output conditions, and it is used as a penalty to bias the policy away from unsafe states without learning an additional value function. We investigate the benefits of using the violation metric in standard Safe DRL benchmarks and robotic mapless navigation tasks. The navigation experiments bridge the gap between Safe DRL and robotics, introducing a framework that allows rapid testing on real robots. Our experiments show that policies trained with the violation penalty achieve higher performance over Safe DRL baselines and significantly reduce the number of visited unsafe states.
Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless Navigation
Feb 13, 2023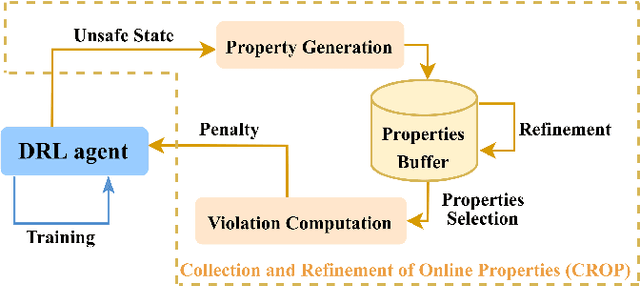
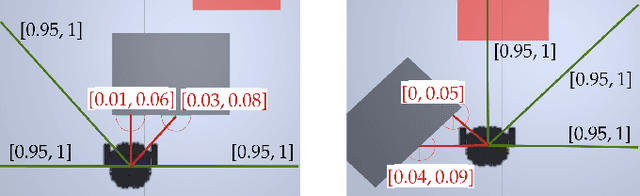
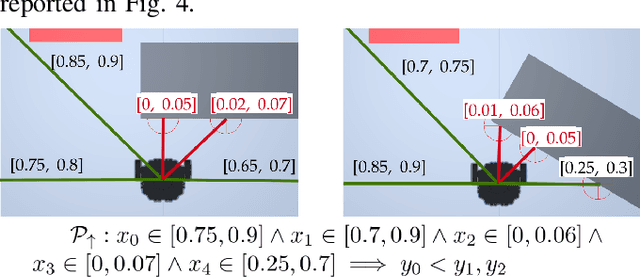
Safety is essential for deploying Deep Reinforcement Learning (DRL) algorithms in real-world scenarios. Recently, verification approaches have been proposed to allow quantifying the number of violations of a DRL policy over input-output relationships, called properties. However, such properties are hard-coded and require task-level knowledge, making their application intractable in challenging safety-critical tasks. To this end, we introduce the Collection and Refinement of Online Properties (CROP) framework to design properties at training time. CROP employs a cost signal to identify unsafe interactions and use them to shape safety properties. Hence, we propose a refinement strategy to combine properties that model similar unsafe interactions. Our evaluation compares the benefits of computing the number of violations using standard hard-coded properties and the ones generated with CROP. We evaluate our approach in several robotic mapless navigation tasks and demonstrate that the violation metric computed with CROP allows higher returns and lower violations over previous Safe DRL approaches.
Curriculum Learning for Safe Mapless Navigation
Dec 29, 2021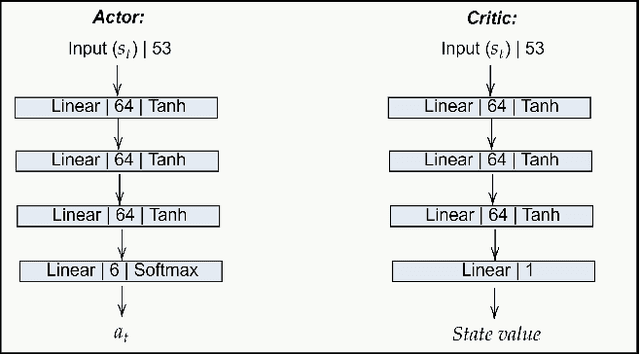

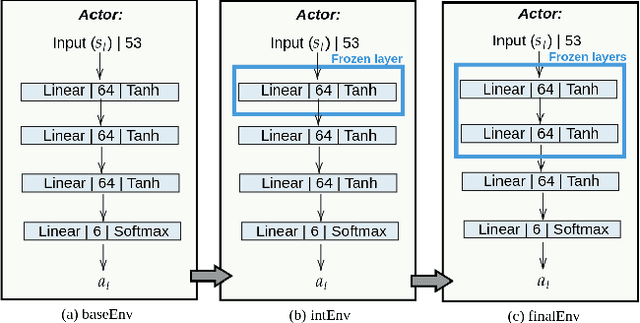
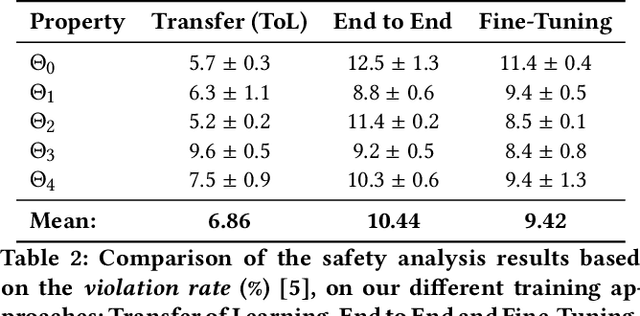
This work investigates the effects of Curriculum Learning (CL)-based approaches on the agent's performance. In particular, we focus on the safety aspect of robotic mapless navigation, comparing over a standard end-to-end (E2E) training strategy. To this end, we present a CL approach that leverages Transfer of Learning (ToL) and fine-tuning in a Unity-based simulation with the Robotnik Kairos as a robotic agent. For a fair comparison, our evaluation considers an equal computational demand for every learning approach (i.e., the same number of interactions and difficulty of the environments) and confirms that our CL-based method that uses ToL outperforms the E2E methodology. In particular, we improve the average success rate and the safety of the trained policy, resulting in 10% fewer collisions in unseen testing scenarios. To further confirm these results, we employ a formal verification tool to quantify the number of correct behaviors of Reinforcement Learning policies over desired specifications.