 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Policy Optimization via $\varepsilon$-Retrain
Paper and Code
Jun 12, 2024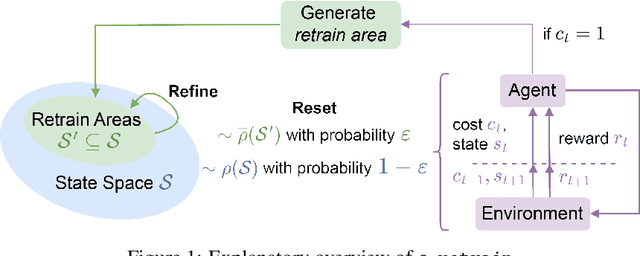
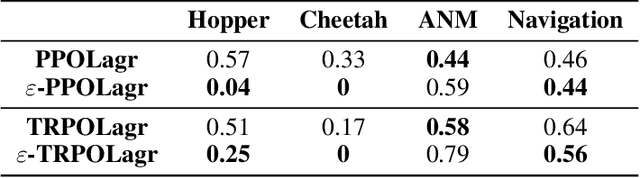
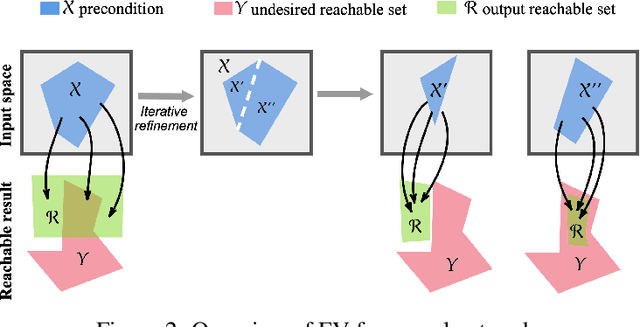
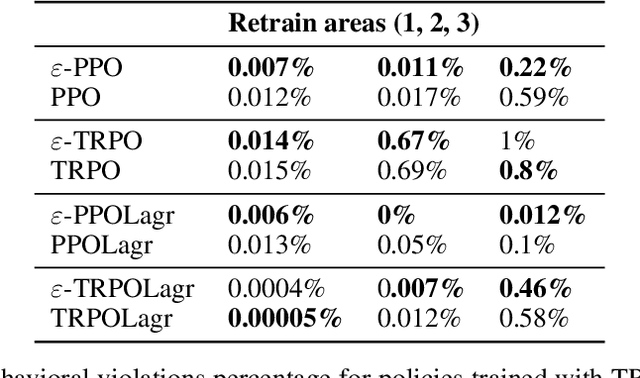
We present $\varepsilon$-retrain, an exploration strategy designed to encourage a behavioral preference while optimizing policies with monotonic improvement guarantees. To this end, we introduce an iterative procedure for collecting retrain areas -- parts of the state space where an agent did not follow the behavioral preference. Our method then switches between the typical uniform restart state distribution and the retrain areas using a decaying factor $\varepsilon$, allowing agents to retrain on situations where they violated the preference. Experiments over hundreds of seeds across locomotion, navigation, and power network tasks show that our method yields agents that exhibit significant performance and sample efficiency improvements. Moreover, we employ formal verification of neural networks to provably quantify the degree to which agents adhere to behavioral preferences.