 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Probabilistic Learnability of Compact Neural Network Preimage Bounds
Nov 10, 2025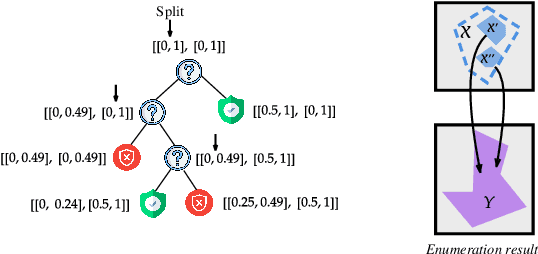
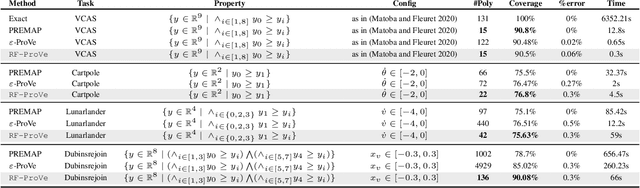
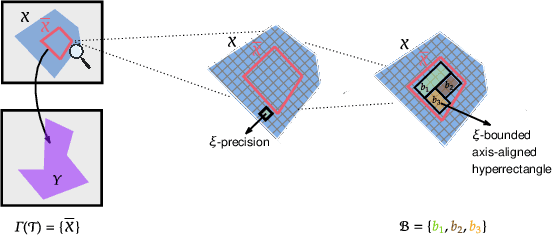
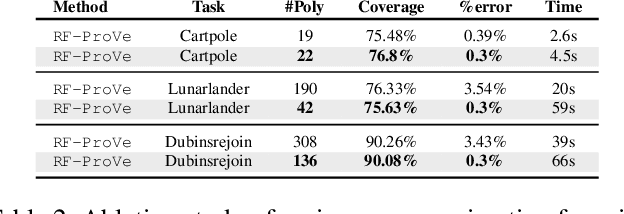
Although recent provable methods have been developed to compute preimage bounds for neural networks, their scalability is fundamentally limited by the #P-hardness of the problem. In this work, we adopt a novel probabilistic perspective, aiming to deliver solutions with high-confidence guarantees and bounded error. To this end, we investigate the potential of bootstrap-based and randomized approaches that are capable of capturing complex patterns in high-dimensional spaces, including input regions where a given output property holds. In detail, we introduce $\textbf{R}$andom $\textbf{F}$orest $\textbf{Pro}$perty $\textbf{Ve}$rifier ($\texttt{RF-ProVe}$), a method that exploits an ensemble of randomized decision trees to generate candidate input regions satisfying a desired output property and refines them through active resampling. Our theoretical derivations offer formal statistical guarantees on region purity and global coverage, providing a practical, scalable solution for computing compact preimage approximations in cases where exact solvers fail to scale.
Advancing Neural Network Verification through Hierarchical Safety Abstract Interpretation
May 08, 2025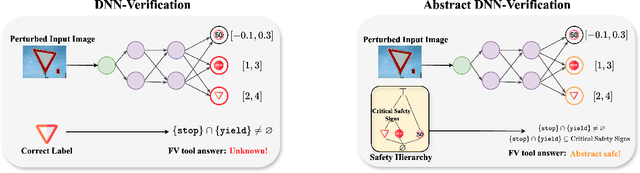
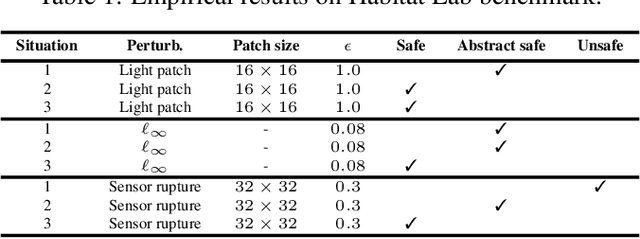
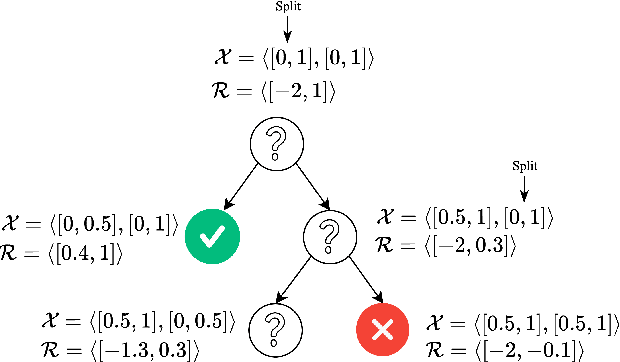
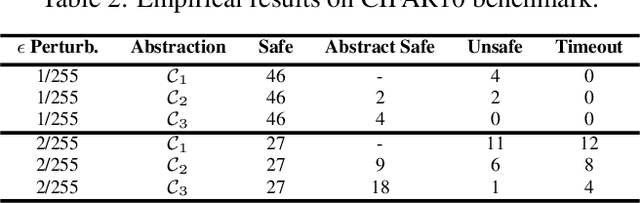
Traditional methods for formal verification (FV) of deep neural networks (DNNs) are constrained by a binary encoding of safety properties, where a model is classified as either safe or unsafe (robust or not robust). This binary encoding fails to capture the nuanced safety levels within a model, often resulting in either overly restrictive or too permissive requirements. In this paper, we introduce a novel problem formulation called Abstract DNN-Verification, which verifies a hierarchical structure of unsafe outputs, providing a more granular analysis of the safety aspect for a given DNN. Crucially, by leveraging abstract interpretation and reasoning about output reachable sets, our approach enables assessing multiple safety levels during the FV process, requiring the same (in the worst case) or even potentially less computational effort than the traditional binary verification approach. Specifically, we demonstrate how this formulation allows rank adversarial inputs according to their abstract safety level violation, offering a more detailed evaluation of the model's safety and robustness. Our contributions include a theoretical exploration of the relationship between our novel abstract safety formulation and existing approaches that employ abstract interpretation for robustness verification, complexity analysis of the novel problem introduced, and an empirical evaluation considering both a complex deep reinforcement learning task (based on Habitat 3.0) and standard DNN-Verification benchmarks.
Designing Control Barrier Function via Probabilistic Enumeration for Safe Reinforcement Learning Navigation
Apr 30, 2025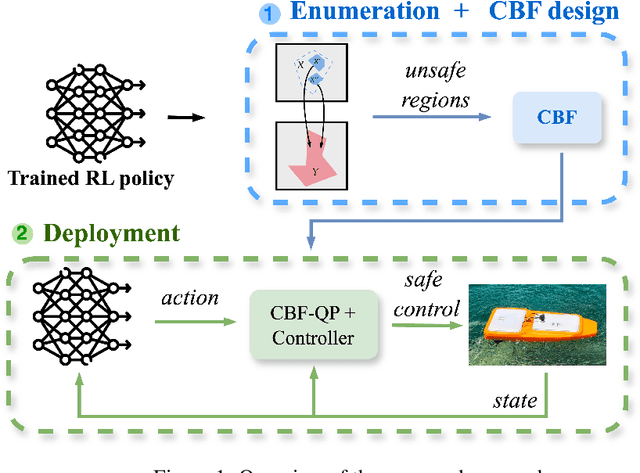


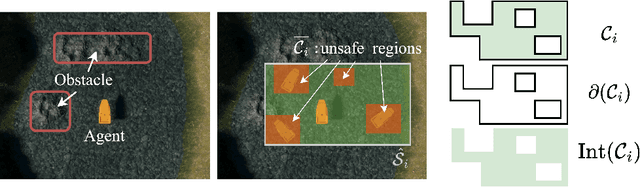
Achieving safe autonomous navigation systems is critical for deploying robots in dynamic and uncertain real-world environments. In this paper, we propose a hierarchical control framework leveraging neural network verification techniques to design control barrier functions (CBFs) and policy correction mechanisms that ensure safe reinforcement learning navigation policies. Our approach relies on probabilistic enumeration to identify unsafe regions of operation, which are then used to construct a safe CBF-based control layer applicable to arbitrary policies. We validate our framework both in simulation and on a real robot, using a standard mobile robot benchmark and a highly dynamic aquatic environmental monitoring task. These experiments demonstrate the ability of the proposed solution to correct unsafe actions while preserving efficient navigation behavior. Our results show the promise of developing hierarchical verification-based systems to enable safe and robust navigation behaviors in complex scenarios.
RobustX: Robust Counterfactual Explanations Made Easy
Feb 19, 2025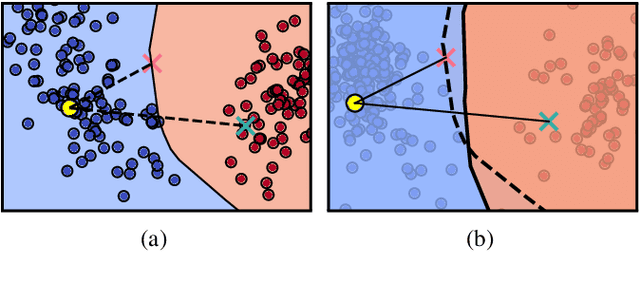
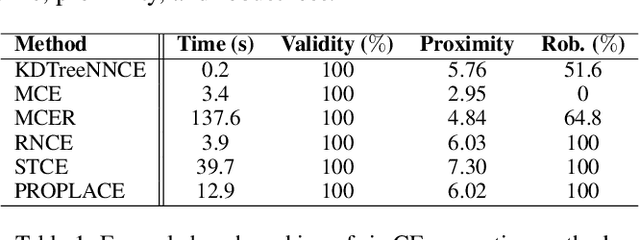
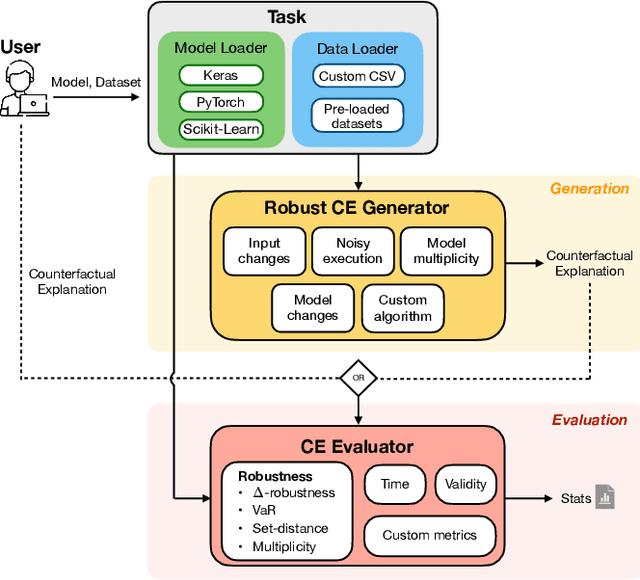

The increasing use of Machine Learning (ML) models to aid decision-making in high-stakes industries demands explainability to facilitate trust. Counterfactual Explanations (CEs) are ideally suited for this, as they can offer insights into the predictions of an ML model by illustrating how changes in its input data may lead to different outcomes. However, for CEs to realise their explanatory potential, significant challenges remain in ensuring their robustness under slight changes in the scenario being explained. Despite the widespread recognition of CEs' robustness as a fundamental requirement, a lack of standardised tools and benchmarks hinders a comprehensive and effective comparison of robust CE generation methods. In this paper, we introduce RobustX, an open-source Python library implementing a collection of CE generation and evaluation methods, with a focus on the robustness property. RobustX provides interfaces to several existing methods from the literature, enabling streamlined access to state-of-the-art techniques. The library is also easily extensible, allowing fast prototyping of novel robust CE generation and evaluation methods.
Rigorous Probabilistic Guarantees for Robust Counterfactual Explanations
Jul 10, 2024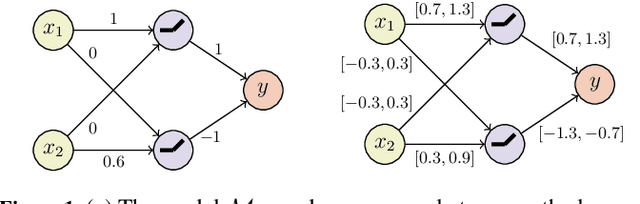

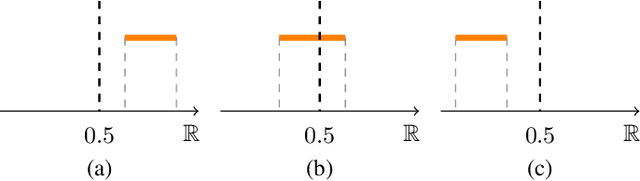
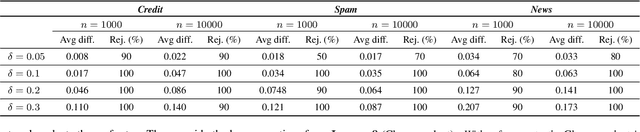
We study the problem of assessing the robustness of counterfactual explanations for deep learning models. We focus on $\textit{plausible model shifts}$ altering model parameters and propose a novel framework to reason about the robustness property in this setting. To motivate our solution, we begin by showing for the first time that computing the robustness of counterfactuals with respect to plausible model shifts is NP-complete. As this (practically) rules out the existence of scalable algorithms for exactly computing robustness, we propose a novel probabilistic approach which is able to provide tight estimates of robustness with strong guarantees while preserving scalability. Remarkably, and differently from existing solutions targeting plausible model shifts, our approach does not impose requirements on the network to be analyzed, thus enabling robustness analysis on a wider range of architectures. Experiments on four binary classification datasets indicate that our method improves the state of the art in generating robust explanations, outperforming existing methods on a range of metrics.
ModelVerification.jl: a Comprehensive Toolbox for Formally Verifying Deep Neural Networks
Jun 30, 2024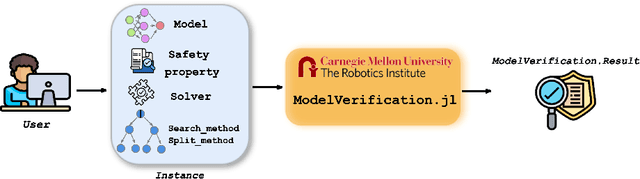

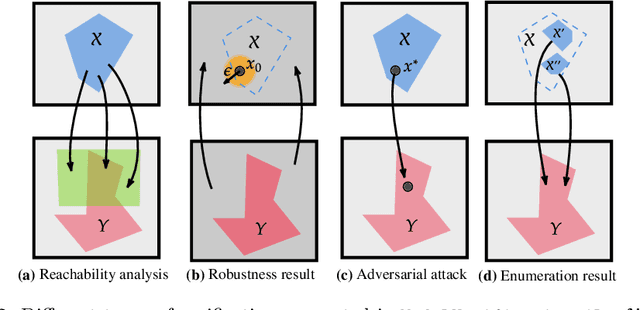
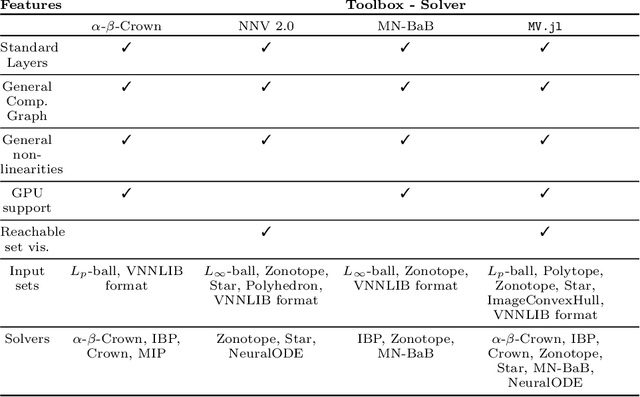
Deep Neural Networks (DNN) are crucial in approximating nonlinear functions across diverse applications, ranging from image classification to control. Verifying specific input-output properties can be a highly challenging task due to the lack of a single, self-contained framework that allows a complete range of verification types. To this end, we present \texttt{ModelVerification.jl (MV)}, the first comprehensive, cutting-edge toolbox that contains a suite of state-of-the-art methods for verifying different types of DNNs and safety specifications. This versatile toolbox is designed to empower developers and machine learning practitioners with robust tools for verifying and ensuring the trustworthiness of their DNN models.
Improving Policy Optimization via $\varepsilon$-Retrain
Jun 12, 2024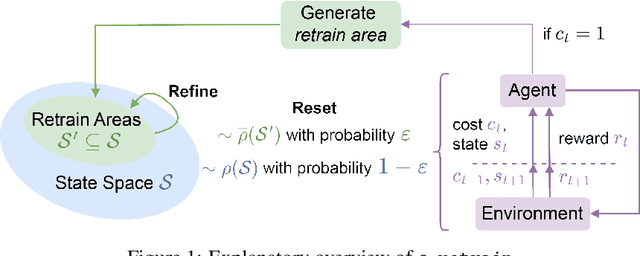
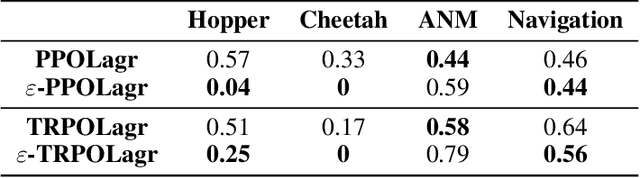
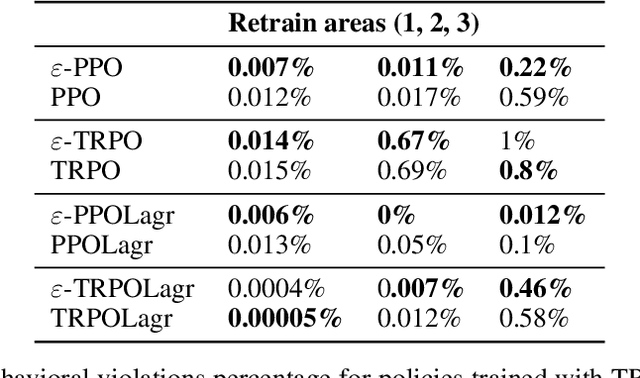
We present $\varepsilon$-retrain, an exploration strategy designed to encourage a behavioral preference while optimizing policies with monotonic improvement guarantees. To this end, we introduce an iterative procedure for collecting retrain areas -- parts of the state space where an agent did not follow the behavioral preference. Our method then switches between the typical uniform restart state distribution and the retrain areas using a decaying factor $\varepsilon$, allowing agents to retrain on situations where they violated the preference. Experiments over hundreds of seeds across locomotion, navigation, and power network tasks show that our method yields agents that exhibit significant performance and sample efficiency improvements. Moreover, we employ formal verification of neural networks to provably quantify the degree to which agents adhere to behavioral preferences.
Scaling #DNN-Verification Tools with Efficient Bound Propagation and Parallel Computing
Dec 10, 2023



Deep Neural Networks (DNNs) are powerful tools that have shown extraordinary results in many scenarios, ranging from pattern recognition to complex robotic problems. However, their intricate designs and lack of transparency raise safety concerns when applied in real-world applications. In this context, Formal Verification (FV) of DNNs has emerged as a valuable solution to provide provable guarantees on the safety aspect. Nonetheless, the binary answer (i.e., safe or unsafe) could be not informative enough for direct safety interventions such as safety model ranking or selection. To address this limitation, the FV problem has recently been extended to the counting version, called #DNN-Verification, for the computation of the size of the unsafe regions in a given safety property's domain. Still, due to the complexity of the problem, existing solutions struggle to scale on real-world robotic scenarios, where the DNN can be large and complex. To address this limitation, inspired by advances in FV, in this work, we propose a novel strategy based on reachability analysis combined with Symbolic Linear Relaxation and parallel computing to enhance the efficiency of existing exact and approximate FV for DNN counters. The empirical evaluation on standard FV benchmarks and realistic robotic scenarios shows a remarkable improvement in scalability and efficiency, enabling the use of such techniques even for complex robotic applications.
Enumerating Safe Regions in Deep Neural Networks with Provable Probabilistic Guarantees
Aug 18, 2023



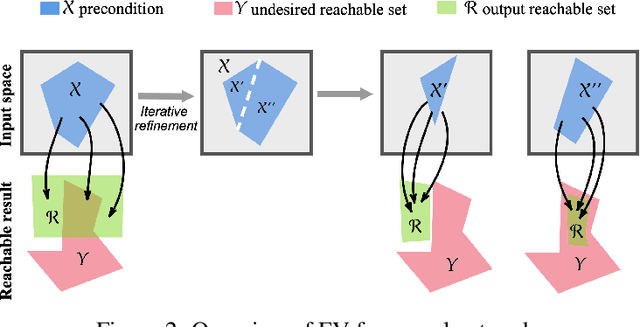
Identifying safe areas is a key point to guarantee trust for systems that are based on Deep Neural Networks (DNNs). To this end, we introduce the AllDNN-Verification problem: given a safety property and a DNN, enumerate the set of all the regions of the property input domain which are safe, i.e., where the property does hold. Due to the #P-hardness of the problem, we propose an efficient approximation method called epsilon-ProVe. Our approach exploits a controllable underestimation of the output reachable sets obtained via statistical prediction of tolerance limits, and can provide a tight (with provable probabilistic guarantees) lower estimate of the safe areas. Our empirical evaluation on different standard benchmarks shows the scalability and effectiveness of our method, offering valuable insights for this new type of verification of DNNs.
Constrained Reinforcement Learning and Formal Verification for Safe Colonoscopy Navigation
Mar 16, 2023



The field of robotic Flexible Endoscopes (FEs) has progressed significantly, offering a promising solution to reduce patient discomfort. However, the limited autonomy of most robotic FEs results in non-intuitive and challenging manoeuvres, constraining their application in clinical settings. While previous studies have employed lumen tracking for autonomous navigation, they fail to adapt to the presence of obstructions and sharp turns when the endoscope faces the colon wall. In this work, we propose a Deep Reinforcement Learning (DRL)-based navigation strategy that eliminates the need for lumen tracking. However, the use of DRL methods poses safety risks as they do not account for potential hazards associated with the actions taken. To ensure safety, we exploit a Constrained Reinforcement Learning (CRL) method to restrict the policy in a predefined safety regime. Moreover, we present a model selection strategy that utilises Formal Verification (FV) to choose a policy that is entirely safe before deployment. We validate our approach in a virtual colonoscopy environment and report that out of the 300 trained policies, we could identify three policies that are entirely safe. Our work demonstrates that CRL, combined with model selection through FV, can improve the robustness and safety of robotic behaviour in surgical applications.