 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigorous Probabilistic Guarantees for Robust Counterfactual Explanations
Paper and Code
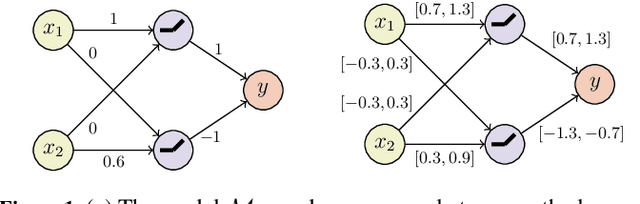

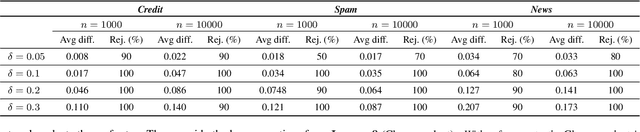
We study the problem of assessing the robustness of counterfactual explanations for deep learning models. We focus on $\textit{plausible model shifts}$ altering model parameters and propose a novel framework to reason about the robustness property in this setting. To motivate our solution, we begin by showing for the first time that computing the robustness of counterfactuals with respect to plausible model shifts is NP-complete. As this (practically) rules out the existence of scalable algorithms for exactly computing robustness, we propose a novel probabilistic approach which is able to provide tight estimates of robustness with strong guarantees while preserving scalability. Remarkably, and differently from existing solutions targeting plausible model shifts, our approach does not impose requirements on the network to be analyzed, thus enabling robustness analysis on a wider range of architectures. Experiments on four binary classification datasets indicate that our method improves the state of the art in generating robust explanations, outperforming existing methods on a range of metrics.