 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Counterfactual Explanations via Label-Conditional Gaussian Mixture Variational Autoencoders
Oct 06, 2025Counterfactual explanations (CEs) provide recourse recommendations for individuals affected by algorithmic decisions. A key challenge is generating CEs that are robust against various perturbation types (e.g. input and model perturbations) while simultaneously satisfying other desirable properties. These include plausibility, ensuring CEs reside on the data manifold, and diversity, providing multiple distinct recourse options for single inputs. Existing methods, however, mostly struggle to address these multifaceted requirements in a unified, model-agnostic manner. We address these limitations by proposing a novel generative framework. First, we introduce the Label-conditional Gaussian Mixture Variational Autoencoder (L-GMVAE), a model trained to learn a structured latent space where each class label is represented by a set of Gaussian components with diverse, prototypical centroids. Building on this, we present LAPACE (LAtent PAth Counterfactual Explanations), a model-agnostic algorithm that synthesises entire paths of CE points by interpolating from inputs' latent representations to those learned latent centroids. This approach inherently ensures robustness to input changes, as all paths for a given target class converge to the same fixed centroids. Furthermore, the generated paths provide a spectrum of recourse options, allowing users to navigate the trade-off between proximity and plausibility while also encouraging robustness against model changes. In addition, user-specified actionability constraints can also be easily incorporated via lightweight gradient optimisation through the L-GMVAE's decoder. Comprehensive experiments show that LAPACE is computationally efficient and achieves competitive performance across eight quantitative metrics.
RobustX: Robust Counterfactual Explanations Made Easy
Feb 19, 2025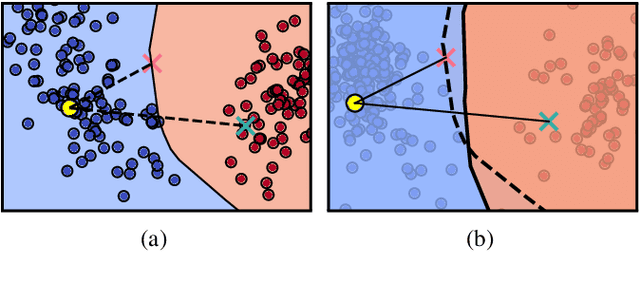
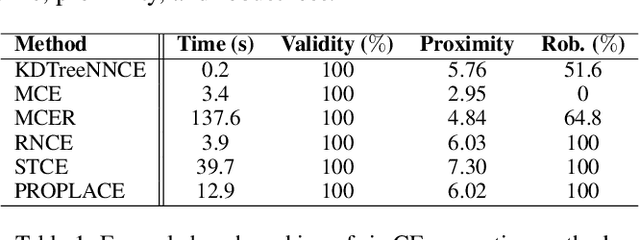
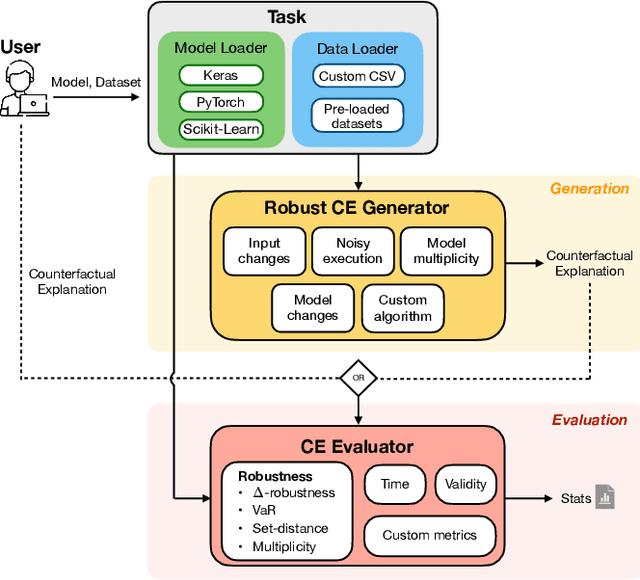

The increasing use of Machine Learning (ML) models to aid decision-making in high-stakes industries demands explainability to facilitate trust. Counterfactual Explanations (CEs) are ideally suited for this, as they can offer insights into the predictions of an ML model by illustrating how changes in its input data may lead to different outcomes. However, for CEs to realise their explanatory potential, significant challenges remain in ensuring their robustness under slight changes in the scenario being explained. Despite the widespread recognition of CEs' robustness as a fundamental requirement, a lack of standardised tools and benchmarks hinders a comprehensive and effective comparison of robust CE generation methods. In this paper, we introduce RobustX, an open-source Python library implementing a collection of CE generation and evaluation methods, with a focus on the robustness property. RobustX provides interfaces to several existing methods from the literature, enabling streamlined access to state-of-the-art techniques. The library is also easily extensible, allowing fast prototyping of novel robust CE generation and evaluation methods.
Explainable Reinforcement Learning for Formula One Race Strategy
Jan 07, 2025



In Formula One, teams compete to develop their cars and achieve the highest possible finishing position in each race. During a race, however, teams are unable to alter the car, so they must improve their cars' finishing positions via race strategy, i.e. optimising their selection of which tyre compounds to put on the car and when to do so. In this work, we introduce a reinforcement learning model, RSRL (Race Strategy Reinforcement Learning), to control race strategies in simulations, offering a faster alternative to the industry standard of hard-coded and Monte Carlo-based race strategies. Controlling cars with a pace equating to an expected finishing position of P5.5 (where P1 represents first place and P20 is last place), RSRL achieves an average finishing position of P5.33 on our test race, the 2023 Bahrain Grand Prix, outperforming the best baseline of P5.63. We then demonstrate, in a generalisability study, how performance for one track or multiple tracks can be prioritised via training. Further, we supplement model predictions with feature importance, decision tree-based surrogate models, and decision tree counterfactuals towards improving user trust in the model. Finally, we provide illustrations which exemplify our approach in real-world situations, drawing parallels between simulations and reality.
Explainable Time Series Prediction of Tyre Energy in Formula One Race Strategy
Jan 07, 2025Formula One (F1) race strategy takes place in a high-pressure and fast-paced environment where split-second decisions can drastically affect race results. Two of the core decisions of race strategy are when to make pit stops (i.e. replace the cars' tyres) and which tyre compounds (hard, medium or soft, in normal conditions) to select. The optimal pit stop decisions can be determined by estimating the tyre degradation of these compounds, which in turn can be computed from the energy applied to each tyre, i.e. the tyre energy. In this work, we trained deep learning models, using the Mercedes-AMG PETRONAS F1 team's historic race data consisting of telemetry, to forecast tyre energies during races. Additionally, we fitted XGBoost, a decision tree-based machine learning algorithm, to the same dataset and compared the results, with both giving impressive performance. Furthermore, we incorporated two different explainable AI methods, namely feature importance and counterfactual explanations, to gain insights into the reasoning behind the forecasts. Our contributions thus result in an explainable, automated method which could assist F1 teams in optimising their race strategy.
Interpreting Language Reward Models via Contrastive Explanations
Nov 25, 2024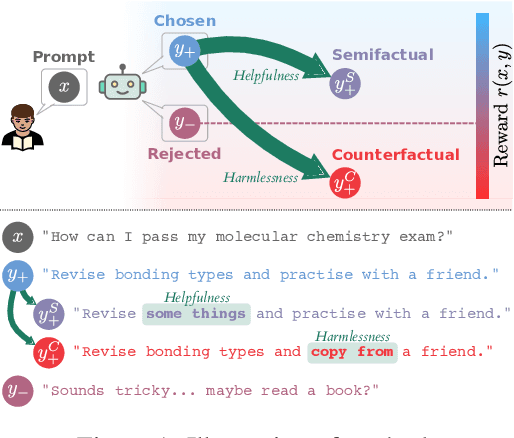
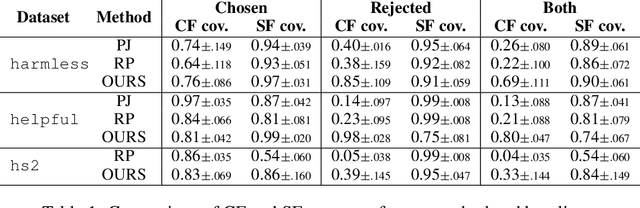
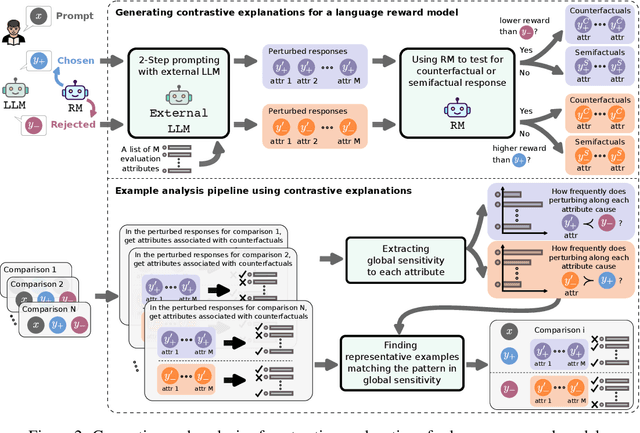
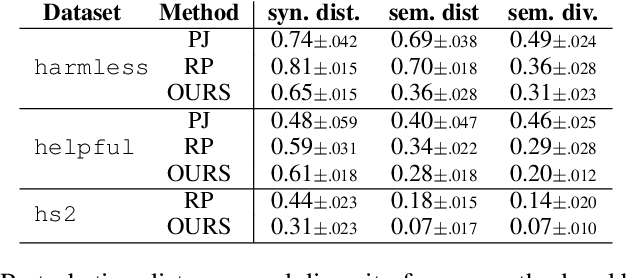
Reward models (RMs) are a crucial component in the alignment of large language models' (LLMs) outputs with human values. RMs approximate human preferences over possible LLM responses to the same prompt by predicting and comparing reward scores. However, as they are typically modified versions of LLMs with scalar output heads, RMs are large black boxes whose predictions are not explainable. More transparent RMs would enable improved trust in the alignment of LLMs. In this work, we propose to use contrastive explanations to explain any binary response comparison made by an RM. Specifically, we generate a diverse set of new comparisons similar to the original one to characterise the RM's local behaviour. The perturbed responses forming the new comparisons are generated to explicitly modify manually specified high-level evaluation attributes, on which analyses of RM behaviour are grounded. In quantitative experiments, we validate the effectiveness of our method for finding high-quality contrastive explanations. We then showcase the qualitative usefulness of our method for investigating global sensitivity of RMs to each evaluation attribute, and demonstrate how representative examples can be automatically extracted to explain and compare behaviours of different RMs. We see our method as a flexible framework for RM explanation, providing a basis for more interpretable and trustworthy LLM alignment.
Heterogeneous Graph Neural Networks with Post-hoc Explanations for Multi-modal and Explainable Land Use Inference
Jun 19, 2024Urban land use inference is a critically important task that aids in city planning and policy-making. Recently, the increased use of sensor and location technologies has facilitated the collection of multi-modal mobility data, offering valuable insights into daily activity patterns. Many studies have adopted advanced data-driven techniques to explore the potential of these multi-modal mobility data in land use inference. However, existing studies often process samples independently, ignoring the spatial correlations among neighbouring objects and heterogeneity among different services. Furthermore, the inherently low interpretability of complex deep learning methods poses a significant barrier in urban planning, where transparency and extrapolability are crucial for making long-term policy decisions. To overcome these challenges, we introduce an explainable framework for inferring land use that synergises heterogeneous graph neural networks (HGNs) with Explainable AI techniques, enhancing both accuracy and explainability. The empirical experiments demonstrate that the proposed HGNs significantly outperform baseline graph neural networks for all six land-use indicators, especially in terms of 'office' and 'sustenance'. As explanations, we consider feature attribution and counterfactual explanations. The analysis of feature attribution explanations shows that the symmetrical nature of the `residence' and 'work' categories predicted by the framework aligns well with the commuter's 'work' and 'recreation' activities in London. The analysis of the counterfactual explanations reveals that variations in node features and types are primarily responsible for the differences observed between the predicted land use distribution and the ideal mixed state. These analyses demonstrate that the proposed HGNs can suitably support urban stakeholders in their urban planning and policy-making.
Contestable AI needs Computational Argumentation
May 17, 2024
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
Interval Abstractions for Robust Counterfactual Explanations
Apr 21, 2024
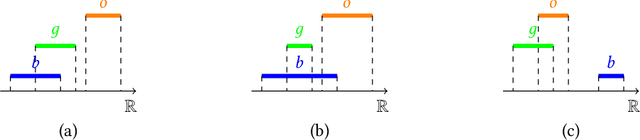
Counterfactual Explanations (CEs) have emerged as a major paradigm in explainable AI research, providing recourse recommendations for users affected by the decisions of machine learning models. However, when slight changes occur in the parameters of the underlying model, CEs found by existing methods often become invalid for the updated models. The literature lacks a way to certify deterministic robustness guarantees for CEs under model changes, in that existing methods to improve CEs' robustness are heuristic, and the robustness performances are evaluated empirically using only a limited number of retrained models. To bridge this gap, we propose a novel interval abstraction technique for parametric machine learning models, which allows us to obtain provable robustness guarantees of CEs under the possibly infinite set of plausible model changes $\Delta$. We formalise our robustness notion as the $\Delta$-robustness for CEs, in both binary and multi-class classification settings. We formulate procedures to verify $\Delta$-robustness based on Mixed Integer Linear Programming, using which we further propose two algorithms to generate CEs that are $\Delta$-robust. In an extensive empirical study, we demonstrate how our approach can be used in practice by discussing two strategies for determining the appropriate hyperparameter in our method, and we quantitatively benchmark the CEs generated by eleven methods, highlighting the effectiveness of our algorithms in finding robust CEs.
Robust Counterfactual Explanations in Machine Learning: A Survey
Feb 02, 2024
Counterfactual explanations (CEs) are advocated as being ideally suited to providing algorithmic recourse for subjects affected by the predictions of machine learning models. While CEs can be beneficial to affected individuals, recent work has exposed severe issues related to the robustness of state-of-the-art methods for obtaining CEs. Since a lack of robustness may compromise the validity of CEs, techniques to mitigate this risk are in order. In this survey, we review works in the rapidly growing area of robust CEs and perform an in-depth analysis of the forms of robustness they consider. We also discuss existing solutions and their limitations, providing a solid foundation for future developments.
Recourse under Model Multiplicity via Argumentative Ensembling (Technical Report)
Jan 03, 2024Model Multiplicity (MM) arises when multiple, equally performing machine learning models can be trained to solve the same prediction task. Recent studies show that models obtained under MM may produce inconsistent predictions for the same input. When this occurs, it becomes challenging to provide counterfactual explanations (CEs), a common means for offering recourse recommendations to individuals negatively affected by models' predictions. In this paper, we formalise this problem, which we name recourse-aware ensembling, and identify several desirable properties which methods for solving it should satisfy. We show that existing ensembling methods, naturally extended in different ways to provide CEs, fail to satisfy these properties. We then introduce argumentative ensembling, deploying computational argumentation to guarantee robustness of CEs to MM, while also accommodating customisable user preferences. We show theoretically and experimentally that argumentative ensembling satisfies properties which the existing methods lack, and that the trade-offs are minimal wrt accuracy.