 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeAdapt: Provably Safe Policy Updates in Deep Reinforcement Learning
Apr 10, 2026Safety guarantees are a prerequisite to the deployment of reinforcement learning (RL) agents in safety-critical tasks. Often, deployment environments exhibit non-stationary dynamics or are subject to changing performance goals, requiring updates to the learned policy. This leads to a fundamental challenge: how to update an RL policy while preserving its safety properties on previously encountered tasks? The majority of current approaches either do not provide formal guarantees or verify policy safety only a posteriori. We propose a novel a priori approach to safe policy updates in continual RL by introducing the Rashomon set: a region in policy parameter space certified to meet safety constraints within the demonstration data distribution. We then show that one can provide formal, provable guarantees for arbitrary RL algorithms used to update a policy by projecting their updates onto the Rashomon set. Empirically, we validate this approach across grid-world navigation environments (Frozen Lake and Poisoned Apple) where we guarantee an a priori provably deterministic safety on the source task during downstream adaptation. In contrast, we observe that regularisation-based baselines experience catastrophic forgetting of safety constraints while our approach enables strong adaptation with provable guarantees that safety is preserved.
Safe Reinforcement Learning via Recovery-based Shielding with Gaussian Process Dynamics Models
Feb 17, 2026Reinforcement learning (RL) is a powerful framework for optimal decision-making and control but often lacks provable guarantees for safety-critical applications. In this paper, we introduce a novel recovery-based shielding framework that enables safe RL with a provable safety lower bound for unknown and non-linear continuous dynamical systems. The proposed approach integrates a backup policy (shield) with the RL agent, leveraging Gaussian process (GP) based uncertainty quantification to predict potential violations of safety constraints, dynamically recovering to safe trajectories only when necessary. Experience gathered by the 'shielded' agent is used to construct the GP models, with policy optimization via internal model-based sampling - enabling unrestricted exploration and sample efficient learning, without compromising safety. Empirically our approach demonstrates strong performance and strict safety-compliance on a suite of continuous control environments.
Expressive Temporal Specifications for Reward Monitoring
Nov 16, 2025Specifying informative and dense reward functions remains a pivotal challenge in Reinforcement Learning, as it directly affects the efficiency of agent training. In this work, we harness the expressive power of quantitative Linear Temporal Logic on finite traces (($\text{LTL}_f[\mathcal{F}]$)) to synthesize reward monitors that generate a dense stream of rewards for runtime-observable state trajectories. By providing nuanced feedback during training, these monitors guide agents toward optimal behaviour and help mitigate the well-known issue of sparse rewards under long-horizon decision making, which arises under the Boolean semantics dominating the current literature. Our framework is algorithm-agnostic and only relies on a state labelling function, and naturally accommodates specifying non-Markovian properties. Empirical results show that our quantitative monitors consistently subsume and, depending on the environment, outperform Boolean monitors in maximizing a quantitative measure of task completion and in reducing convergence time.
Behaviour Policy Optimization: Provably Lower Variance Return Estimates for Off-Policy Reinforcement Learning
Nov 13, 2025Many reinforcement learning algorithms, particularly those that rely on return estimates for policy improvement, can suffer from poor sample efficiency and training instability due to high-variance return estimates. In this paper we leverage new results from off-policy evaluation; it has recently been shown that well-designed behaviour policies can be used to collect off-policy data for provably lower variance return estimates. This result is surprising as it means collecting data on-policy is not variance optimal. We extend this key insight to the online reinforcement learning setting, where both policy evaluation and improvement are interleaved to learn optimal policies. Off-policy RL has been well studied (e.g., IMPALA), with correct and truncated importance weighted samples for de-biasing and managing variance appropriately. Generally these approaches are concerned with reconciling data collected from multiple workers in parallel, while the policy is updated asynchronously, mismatch between the workers and policy is corrected in a mathematically sound way. Here we consider only one worker - the behaviour policy, which is used to collect data for policy improvement, with provably lower variance return estimates. In our experiments we extend two policy-gradient methods with this regime, demonstrating better sample efficiency and performance over a diverse set of environments.
Multi-Agent Q-Learning Dynamics in Random Networks: Convergence due to Exploration and Sparsity
Mar 13, 2025Beyond specific settings, many multi-agent learning algorithms fail to converge to an equilibrium solution, and instead display complex, non-stationary behaviours such as recurrent or chaotic orbits. In fact, recent literature suggests that such complex behaviours are likely to occur when the number of agents increases. In this paper, we study Q-learning dynamics in network polymatrix games where the network structure is drawn from classical random graph models. In particular, we focus on the Erdos-Renyi model, a well-studied model for social networks, and the Stochastic Block model, which generalizes the above by accounting for community structures within the network. In each setting, we establish sufficient conditions under which the agents' joint strategies converge to a unique equilibrium. We investigate how this condition depends on the exploration rates, payoff matrices and, crucially, the sparsity of the network. Finally, we validate our theoretical findings through numerical simulations and demonstrate that convergence can be reliably achieved in many-agent systems, provided network sparsity is controlled.
Probabilistic Shielding for Safe Reinforcement Learning
Mar 09, 2025
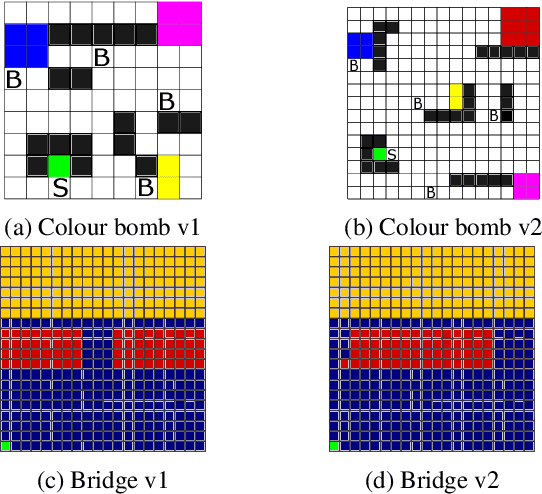
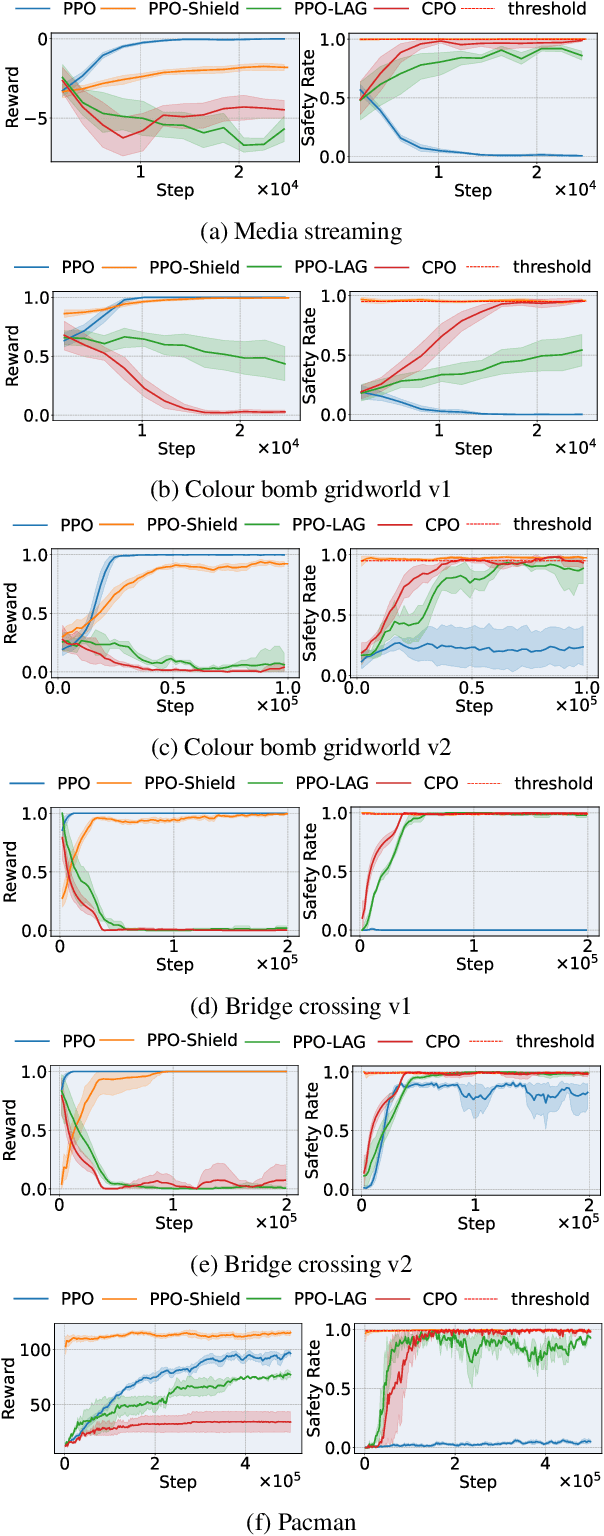
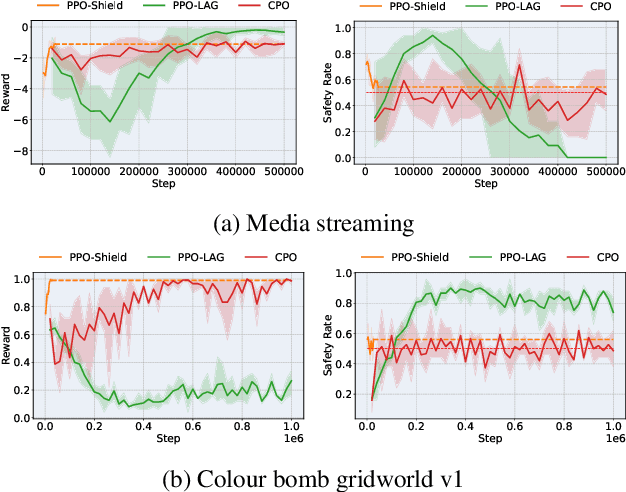
In real-life scenarios, a Reinforcement Learning (RL) agent aiming to maximise their reward, must often also behave in a safe manner, including at training time. Thus, much attention in recent years has been given to Safe RL, where an agent aims to learn an optimal policy among all policies that satisfy a given safety constraint. However, strict safety guarantees are often provided through approaches based on linear programming, and thus have limited scaling. In this paper we present a new, scalable method, which enjoys strict formal guarantees for Safe RL, in the case where the safety dynamics of the Markov Decision Process (MDP) are known, and safety is defined as an undiscounted probabilistic avoidance property. Our approach is based on state-augmentation of the MDP, and on the design of a shield that restricts the actions available to the agent. We show that our approach provides a strict formal safety guarantee that the agent stays safe at training and test time. Furthermore, we demonstrate that our approach is viable in practice through experimental evaluation.
Explainable Reinforcement Learning for Formula One Race Strategy
Jan 07, 2025



In Formula One, teams compete to develop their cars and achieve the highest possible finishing position in each race. During a race, however, teams are unable to alter the car, so they must improve their cars' finishing positions via race strategy, i.e. optimising their selection of which tyre compounds to put on the car and when to do so. In this work, we introduce a reinforcement learning model, RSRL (Race Strategy Reinforcement Learning), to control race strategies in simulations, offering a faster alternative to the industry standard of hard-coded and Monte Carlo-based race strategies. Controlling cars with a pace equating to an expected finishing position of P5.5 (where P1 represents first place and P20 is last place), RSRL achieves an average finishing position of P5.33 on our test race, the 2023 Bahrain Grand Prix, outperforming the best baseline of P5.63. We then demonstrate, in a generalisability study, how performance for one track or multiple tracks can be prioritised via training. Further, we supplement model predictions with feature importance, decision tree-based surrogate models, and decision tree counterfactuals towards improving user trust in the model. Finally, we provide illustrations which exemplify our approach in real-world situations, drawing parallels between simulations and reality.
Measuring Goal-Directedness
Dec 06, 2024



We define maximum entropy goal-directedness (MEG), a formal measure of goal-directedness in causal models and Markov decision processes, and give algorithms for computing it. Measuring goal-directedness is important, as it is a critical element of many concerns about harm from AI. It is also of philosophical interest, as goal-directedness is a key aspect of agency. MEG is based on an adaptation of the maximum causal entropy framework used in inverse reinforcement learning. It can measure goal-directedness with respect to a known utility function, a hypothesis class of utility functions, or a set of random variables. We prove that MEG satisfies several desiderata and demonstrate our algorithms with small-scale experiments.
The Reasons that Agents Act: Intention and Instrumental Goals
Feb 15, 2024



Intention is an important and challenging concept in AI. It is important because it underlies many other concepts we care about, such as agency, manipulation, legal responsibility, and blame. However, ascribing intent to AI systems is contentious, and there is no universally accepted theory of intention applicable to AI agents. We operationalise the intention with which an agent acts, relating to the reasons it chooses its decision. We introduce a formal definition of intention in structural causal influence models, grounded in the philosophy literature on intent and applicable to real-world machine learning systems. Through a number of examples and results, we show that our definition captures the intuitive notion of intent and satisfies desiderata set-out by past work. In addition, we show how our definition relates to past concepts, including actual causality, and the notion of instrumental goals, which is a core idea in the literature on safe AI agents. Finally, we demonstrate how our definition can be used to infer the intentions of reinforcement learning agents and language models from their behaviour.
Leveraging Approximate Model-based Shielding for Probabilistic Safety Guarantees in Continuous Environments
Feb 01, 2024Shielding is a popular technique for achieving safe reinforcement learning (RL). However, classical shielding approaches come with quite restrictive assumptions making them difficult to deploy in complex environments, particularly those with continuous state or action spaces. In this paper we extend the more versatile approximate model-based shielding (AMBS) framework to the continuous setting. In particular we use Safety Gym as our test-bed, allowing for a more direct comparison of AMBS with popular constrained RL algorithms. We also provide strong probabilistic safety guarantees for the continuous setting. In addition, we propose two novel penalty techniques that directly modify the policy gradient, which empirically provide more stable convergence in our experiments.