 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Autonomous Gas Monitoring for Volcanic Environments: A Legged Robot on Mount Etna
Jan 12, 2026Volcanic gas emissions are key precursors of eruptive activity. Yet, obtaining accurate near-surface measurements remains hazardous and logistically challenging, motivating the need for autonomous solutions. Limited mobility in rough volcanic terrain has prevented wheeled systems from performing reliable in situ gas measurements, reducing their usefulness as sensing platforms. We present a legged robotic system for autonomous volcanic gas analysis, utilizing the quadruped ANYmal, equipped with a quadrupole mass spectrometer system. Our modular autonomy stack integrates a mission planning interface, global planner, localization framework, and terrain-aware local navigation. We evaluated the system on Mount Etna across three autonomous missions in varied terrain, achieving successful gas-source detections with autonomy rates of 93-100%. In addition, we conducted a teleoperated mission in which the robot measured natural fumaroles, detecting sulfur dioxide and carbon dioxide. We discuss lessons learned from the gas-analysis and autonomy perspectives, emphasizing the need for adaptive sensing strategies, tighter integration of global and local planning, and improved hardware design.
Measuring Goal-Directedness
Dec 06, 2024



We define maximum entropy goal-directedness (MEG), a formal measure of goal-directedness in causal models and Markov decision processes, and give algorithms for computing it. Measuring goal-directedness is important, as it is a critical element of many concerns about harm from AI. It is also of philosophical interest, as goal-directedness is a key aspect of agency. MEG is based on an adaptation of the maximum causal entropy framework used in inverse reinforcement learning. It can measure goal-directedness with respect to a known utility function, a hypothesis class of utility functions, or a set of random variables. We prove that MEG satisfies several desiderata and demonstrate our algorithms with small-scale experiments.
Strategic Insights from Simulation Gaming of AI Race Dynamics
Oct 04, 2024

We present insights from "Intelligence Rising", a scenario exploration exercise about possible AI futures. Drawing on the experiences of facilitators who have overseen 43 games over a four-year period, we illuminate recurring patterns, strategies, and decision-making processes observed during gameplay. Our analysis reveals key strategic considerations about AI development trajectories in this simulated environment, including: the destabilising effects of AI races, the crucial role of international cooperation in mitigating catastrophic risks, the challenges of aligning corporate and national interests, and the potential for rapid, transformative change in AI capabilities. We highlight places where we believe the game has been effective in exposing participants to the complexities and uncertainties inherent in AI governance. Key recurring gameplay themes include the emergence of international agreements, challenges to the robustness of such agreements, the critical role of cybersecurity in AI development, and the potential for unexpected crises to dramatically alter AI trajectories. By documenting these insights, we aim to provide valuable foresight for policymakers, industry leaders, and researchers navigating the complex landscape of AI development and governance.
Characterising Interventions in Causal Games
Jun 13, 2024
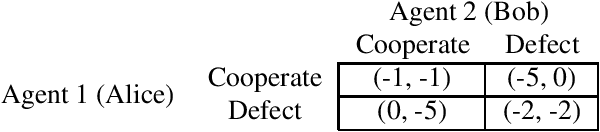
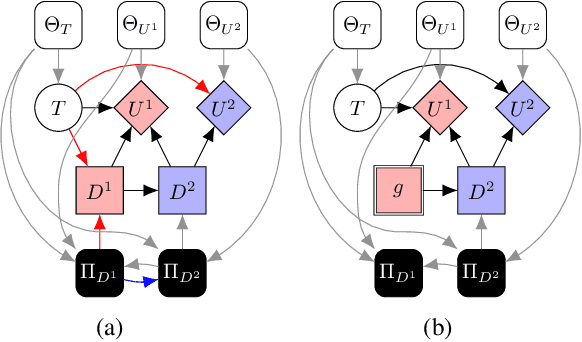
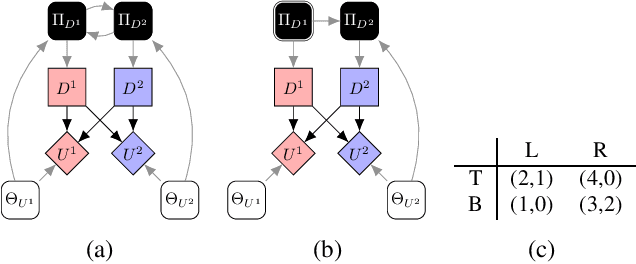
Causal games are probabilistic graphical models that enable causal queries to be answered in multi-agent settings. They extend causal Bayesian networks by specifying decision and utility variables to represent the agents' degrees of freedom and objectives. In multi-agent settings, whether each agent decides on their policy before or after knowing the causal intervention is important as this affects whether they can respond to the intervention by adapting their policy. Consequently, previous work in causal games imposed chronological constraints on permissible interventions. We relax this by outlining a sound and complete set of primitive causal interventions so the effect of any arbitrarily complex interventional query can be studied in multi-agent settings. We also demonstrate applications to the design of safe AI systems by considering causal mechanism design and commitment.
An International Consortium for Evaluations of Societal-Scale Risks from Advanced AI
Nov 06, 2023



Given rapid progress toward advanced AI and risks from frontier AI systems (advanced AI systems pushing the boundaries of the AI capabilities frontier), the creation and implementation of AI governance and regulatory schemes deserves prioritization and substantial investment. However, the status quo is untenable and, frankly, dangerous. A regulatory gap has permitted AI labs to conduct research, development, and deployment activities with minimal oversight. In response, frontier AI system evaluations have been proposed as a way of assessing risks from the development and deployment of frontier AI systems. Yet, the budding AI risk evaluation ecosystem faces significant coordination challenges, such as a limited diversity of evaluators, suboptimal allocation of effort, and perverse incentives. This paper proposes a solution in the form of an international consortium for AI risk evaluations, comprising both AI developers and third-party AI risk evaluators. Such a consortium could play a critical role in international efforts to mitigate societal-scale risks from advanced AI, including in managing responsible scaling policies and coordinated evaluation-based risk response. In this paper, we discuss the current evaluation ecosystem and its shortcomings, propose an international consortium for advanced AI risk evaluations, discuss issues regarding its implementation, discuss lessons that can be learnt from previous international institutions and existing proposals for international AI governance institutions, and, finally, we recommend concrete steps to advance the establishment of the proposed consortium: (i) solicit feedback from stakeholders, (ii) conduct additional research, (iii) conduct a workshop(s) for stakeholders, (iv) analyze feedback and create final proposal, (v) solicit funding, and (vi) create a consortium.
On Imperfect Recall in Multi-Agent Influence Diagrams
Jul 11, 2023Multi-agent influence diagrams (MAIDs) are a popular game-theoretic model based on Bayesian networks. In some settings, MAIDs offer significant advantages over extensive-form game representations. Previous work on MAIDs has assumed that agents employ behavioural policies, which set independent conditional probability distributions over actions for each of their decisions. In settings with imperfect recall, however, a Nash equilibrium in behavioural policies may not exist. We overcome this by showing how to solve MAIDs with forgetful and absent-minded agents using mixed policies and two types of correlated equilibrium. We also analyse the computational complexity of key decision problems in MAIDs, and explore tractable cases. Finally, we describe applications of MAIDs to Markov games and team situations, where imperfect recall is often unavoidable.
* In Proceedings TARK 2023, arXiv:2307.04005
Reasoning about Causality in Games
Jan 05, 2023



Causal reasoning and game-theoretic reasoning are fundamental topics in artificial intelligence, among many other disciplines: this paper is concerned with their intersection. Despite their importance, a formal framework that supports both these forms of reasoning has, until now, been lacking. We offer a solution in the form of (structural) causal games, which can be seen as extending Pearl's causal hierarchy to the game-theoretic domain, or as extending Koller and Milch's multi-agent influence diagrams to the causal domain. We then consider three key questions: i) How can the (causal) dependencies in games - either between variables, or between strategies - be modelled in a uniform, principled manner? ii) How may causal queries be computed in causal games, and what assumptions does this require? iii) How do causal games compare to existing formalisms? To address question i), we introduce mechanised games, which encode dependencies between agents' decision rules and the distributions governing the game. In response to question ii), we present definitions of predictions, interventions, and counterfactuals, and discuss the assumptions required for each. Regarding question iii), we describe correspondences between causal games and other formalisms, and explain how causal games can be used to answer queries that other causal or game-theoretic models do not support. Finally, we highlight possible applications of causal games, aided by an extensive open-source Python library.
Learning Task Automata for Reinforcement Learning using Hidden Markov Models
Aug 25, 2022

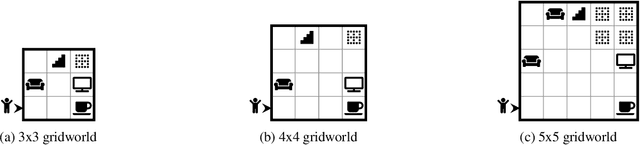

Training reinforcement learning (RL) agents using scalar reward signals is often infeasible when an environment has sparse and non-Markovian rewards. Moreover, handcrafting these reward functions before training is prone to misspecification, especially when the environment's dynamics are only partially known. This paper proposes a novel pipeline for learning non-Markovian task specifications as succinct finite-state `task automata' from episodes of agent experience within unknown environments. We leverage two key algorithmic insights. First, we learn a product MDP, a model composed of the specification's automaton and the environment's MDP (both initially unknown), by treating it as a partially observable MDP and using off-the-shelf algorithms for hidden Markov models. Second, we propose a novel method for distilling the task automaton (assumed to be a deterministic finite automaton) from the learnt product MDP. Our learnt task automaton enables the decomposition of a task into its constituent sub-tasks, which improves the rate at which an RL agent can later synthesise an optimal policy. It also provides an interpretable encoding of high-level environmental and task features, so a human can readily verify that the agent has learnt coherent tasks with no misspecifications. In addition, we take steps towards ensuring that the learnt automaton is environment-agnostic, making it well-suited for use in transfer learning. Finally, we provide experimental results to illustrate our algorithm's performance in different environments and tasks and its ability to incorporate prior domain knowledge to facilitate more efficient learning.
Concentric Spherical GNN for 3D Representation Learning
Mar 18, 2021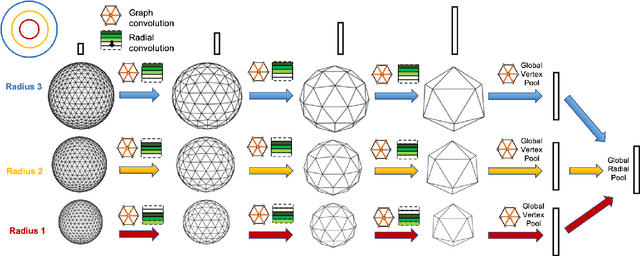
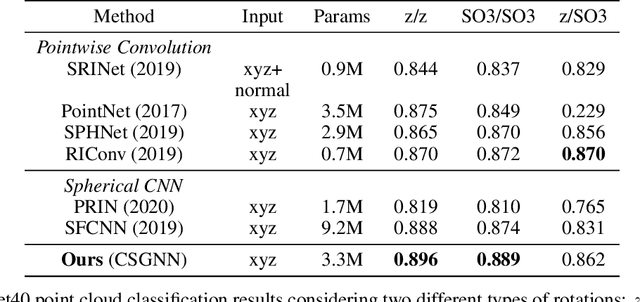
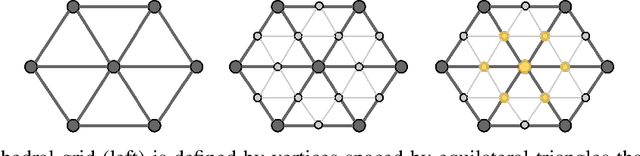
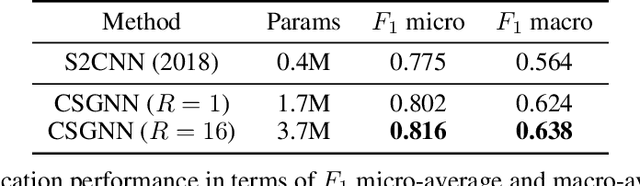
Learning 3D representations that generalize well to arbitrarily oriented inputs is a challenge of practical importance in applications varying from computer vision to physics and chemistry. We propose a novel multi-resolution convolutional architecture for learning over concentric spherical feature maps, of which the single sphere representation is a special case. Our hierarchical architecture is based on alternatively learning to incorporate both intra-sphere and inter-sphere information. We show the applicability of our method for two different types of 3D inputs, mesh objects, which can be regularly sampled, and point clouds, which are irregularly distributed. We also propose an efficient mapping of point clouds to concentric spherical images, thereby bridging spherical convolutions on grids with general point clouds. We demonstrate the effectiveness of our approach in improving state-of-the-art performance on 3D classification tasks with rotated data.
Equilibrium Refinements for Multi-Agent Influence Diagrams: Theory and Practice
Feb 09, 2021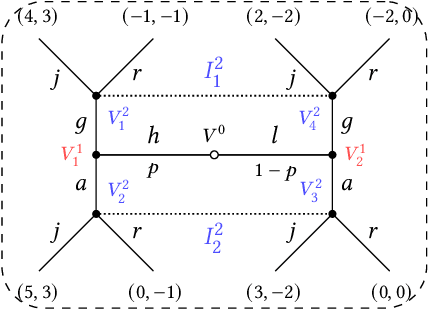
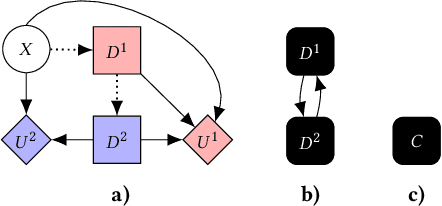
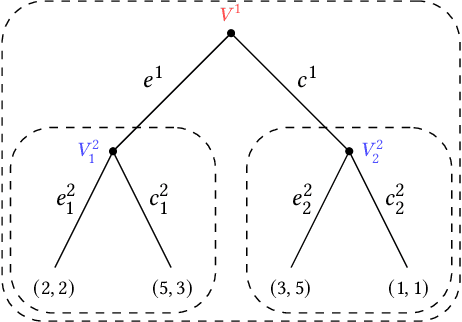
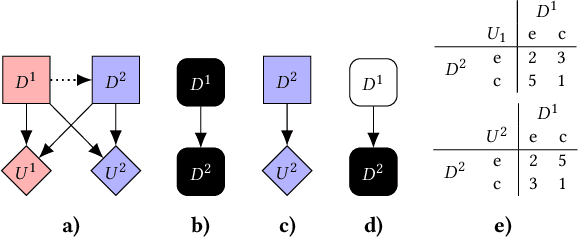
Multi-agent influence diagrams (MAIDs) are a popular form of graphical model that, for certain classes of games, have been shown to offer key complexity and explainability advantages over traditional extensive form game (EFG) representations. In this paper, we extend previous work on MAIDs by introducing the concept of a MAID subgame, as well as subgame perfect and trembling hand perfect equilibrium refinements. We then prove several equivalence results between MAIDs and EFGs. Finally, we describe an open source implementation for reasoning about MAIDs and computing their equilibria.