 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Neural Interactive Proofs
Dec 12, 2024We consider the problem of how a trusted, but computationally bounded agent (a 'verifier') can learn to interact with one or more powerful but untrusted agents ('provers') in order to solve a given task. More specifically, we study the case in which agents are represented using neural networks and refer to solutions of this problem as neural interactive proofs. First we introduce a unifying framework based on prover-verifier games, which generalises previously proposed interaction protocols. We then describe several new protocols for generating neural interactive proofs, and provide a theoretical comparison of both new and existing approaches. Finally, we support this theory with experiments in two domains: a toy graph isomorphism problem that illustrates the key ideas, and a code validation task using large language models. In so doing, we aim to create a foundation for future work on neural interactive proofs and their application in building safer AI systems.
Game Theory with Simulation in the Presence of Unpredictable Randomisation
Oct 18, 2024
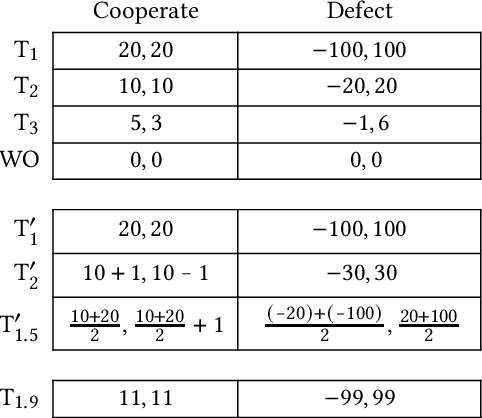
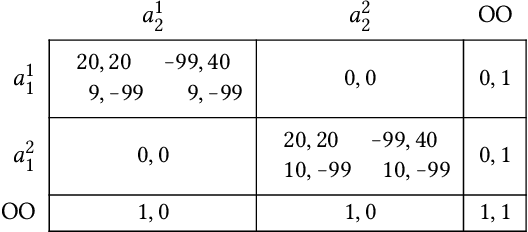

AI agents will be predictable in certain ways that traditional agents are not. Where and how can we leverage this predictability in order to improve social welfare? We study this question in a game-theoretic setting where one agent can pay a fixed cost to simulate the other in order to learn its mixed strategy. As a negative result, we prove that, in contrast to prior work on pure-strategy simulation, enabling mixed-strategy simulation may no longer lead to improved outcomes for both players in all so-called "generalised trust games". In fact, mixed-strategy simulation does not help in any game where the simulatee's action can depend on that of the simulator. We also show that, in general, deciding whether simulation introduces Pareto-improving Nash equilibria in a given game is NP-hard. As positive results, we establish that mixed-strategy simulation can improve social welfare if the simulator has the option to scale their level of trust, if the players face challenges with both trust and coordination, or if maintaining some level of privacy is essential for enabling cooperation.
IDs for AI Systems
Jun 17, 2024



AI systems are increasingly pervasive, yet information needed to decide whether and how to engage with them may not exist or be accessible. A user may not be able to verify whether a system satisfies certain safety standards. An investigator may not know whom to investigate when a system causes an incident. A platform may find it difficult to penalize repeated negative interactions with the same system. Across a number of domains, IDs address analogous problems by identifying \textit{particular} entities (e.g., a particular Boeing 747) and providing information about other entities of the same class (e.g., some or all Boeing 747s). We propose a framework in which IDs are ascribed to \textbf{instances} of AI systems (e.g., a particular chat session with Claude 3), and associated information is accessible to parties seeking to interact with that system. We characterize IDs for AI systems, argue that there could be significant demand for IDs from key actors, analyze how those actors could incentivize ID adoption, explore potential implementations of our framework, and highlight limitations and risks. IDs seem most warranted in high-stakes settings, where certain actors (e.g., those that enable AI systems to make financial transactions) could experiment with incentives for ID use. Deployers of AI systems could experiment with developing ID implementations. With further study, IDs could help to manage a world where AI systems pervade society.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Cooperation and Control in Delegation Games
Feb 24, 2024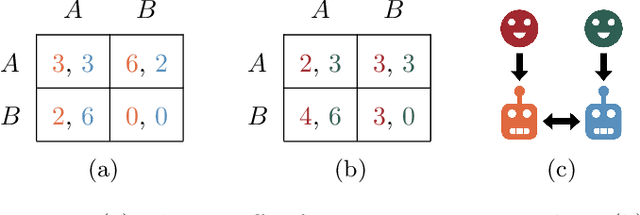
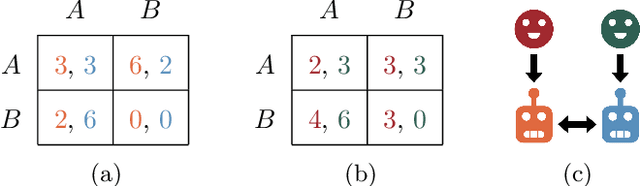


Many settings of interest involving humans and machines -- from virtual personal assistants to autonomous vehicles -- can naturally be modelled as principals (humans) delegating to agents (machines), which then interact with each other on their principals' behalf. We refer to these multi-principal, multi-agent scenarios as delegation games. In such games, there are two important failure modes: problems of control (where an agent fails to act in line their principal's preferences) and problems of cooperation (where the agents fail to work well together). In this paper we formalise and analyse these problems, further breaking them down into issues of alignment (do the players have similar preferences?) and capabilities (how competent are the players at satisfying those preferences?). We show -- theoretically and empirically -- how these measures determine the principals' welfare, how they can be estimated using limited observations, and thus how they might be used to help us design more aligned and cooperative AI systems.
Secret Collusion Among Generative AI Agents
Feb 12, 2024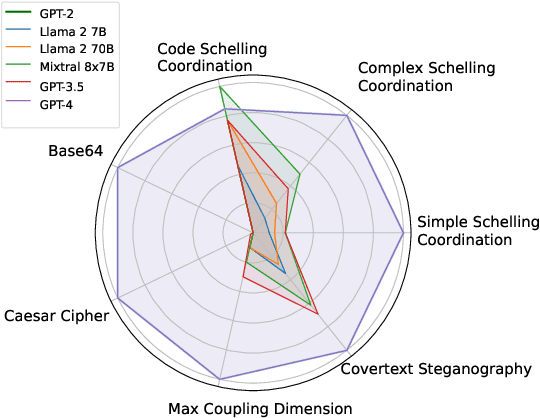
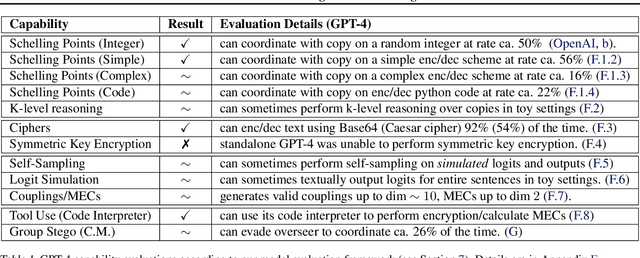

Recent capability increases in large language models (LLMs) open up applications in which teams of communicating generative AI agents solve joint tasks. This poses privacy and security challenges concerning the unauthorised sharing of information, or other unwanted forms of agent coordination. Modern steganographic techniques could render such dynamics hard to detect. In this paper, we comprehensively formalise the problem of secret collusion in systems of generative AI agents by drawing on relevant concepts from both the AI and security literature. We study incentives for the use of steganography, and propose a variety of mitigation measures. Our investigations result in a model evaluation framework that systematically tests capabilities required for various forms of secret collusion. We provide extensive empirical results across a range of contemporary LLMs. While the steganographic capabilities of current models remain limited, GPT-4 displays a capability jump suggesting the need for continuous monitoring of steganographic frontier model capabilities. We conclude by laying out a comprehensive research program to mitigate future risks of collusion between generative AI models.
Visibility into AI Agents
Feb 04, 2024

Increased delegation of commercial, scientific, governmental, and personal activities to AI agents -- systems capable of pursuing complex goals with limited supervision -- may exacerbate existing societal risks and introduce new risks. Understanding and mitigating these risks involves critically evaluating existing governance structures, revising and adapting these structures where needed, and ensuring accountability of key stakeholders. Information about where, why, how, and by whom certain AI agents are used, which we refer to as visibility, is critical to these objectives. In this paper, we assess three categories of measures to increase visibility into AI agents: agent identifiers, real-time monitoring, and activity logging. For each, we outline potential implementations that vary in intrusiveness and informativeness. We analyze how the measures apply across a spectrum of centralized through decentralized deployment contexts, accounting for various actors in the supply chain including hardware and software service providers. Finally, we discuss the implications of our measures for privacy and concentration of power. Further work into understanding the measures and mitigating their negative impacts can help to build a foundation for the governance of AI agents.
Welfare Diplomacy: Benchmarking Language Model Cooperation
Oct 13, 2023
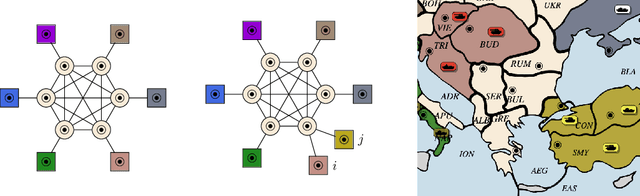

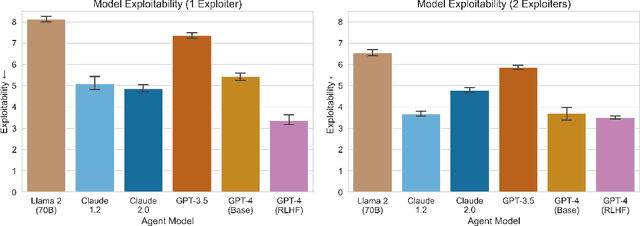
The growing capabilities and increasingly widespread deployment of AI systems necessitate robust benchmarks for measuring their cooperative capabilities. Unfortunately, most multi-agent benchmarks are either zero-sum or purely cooperative, providing limited opportunities for such measurements. We introduce a general-sum variant of the zero-sum board game Diplomacy -- called Welfare Diplomacy -- in which players must balance investing in military conquest and domestic welfare. We argue that Welfare Diplomacy facilitates both a clearer assessment of and stronger training incentives for cooperative capabilities. Our contributions are: (1) proposing the Welfare Diplomacy rules and implementing them via an open-source Diplomacy engine; (2) constructing baseline agents using zero-shot prompted language models; and (3) conducting experiments where we find that baselines using state-of-the-art models attain high social welfare but are exploitable. Our work aims to promote societal safety by aiding researchers in developing and assessing multi-agent AI systems. Code to evaluate Welfare Diplomacy and reproduce our experiments is available at https://github.com/mukobi/welfare-diplomacy.
On Imperfect Recall in Multi-Agent Influence Diagrams
Jul 11, 2023

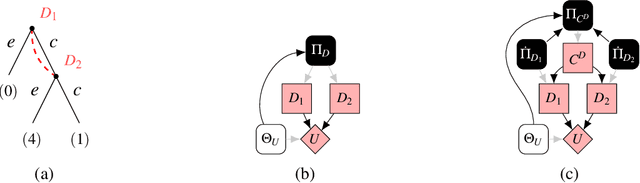

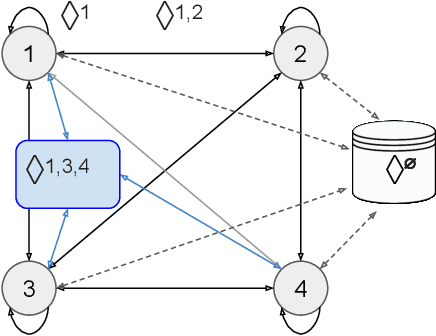
Multi-agent influence diagrams (MAIDs) are a popular game-theoretic model based on Bayesian networks. In some settings, MAIDs offer significant advantages over extensive-form game representations. Previous work on MAIDs has assumed that agents employ behavioural policies, which set independent conditional probability distributions over actions for each of their decisions. In settings with imperfect recall, however, a Nash equilibrium in behavioural policies may not exist. We overcome this by showing how to solve MAIDs with forgetful and absent-minded agents using mixed policies and two types of correlated equilibrium. We also analyse the computational complexity of key decision problems in MAIDs, and explore tractable cases. Finally, we describe applications of MAIDs to Markov games and team situations, where imperfect recall is often unavoidable.
* In Proceedings TARK 2023, arXiv:2307.04005