 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Inference Compute Shapes Frontier LLM Evaluation
Jun 16, 2026AI evaluations are shifting toward harder tasks that benefit from longer trajectories involving tool use and iterative problem solving. As a result, performance is increasingly sensitive to the amount and allocation of compute available at test time ("inference compute"). Yet many evaluations still report performance at a single restrictive budget, meaning that low scores may reflect the evaluation setup rather than the model's underlying capability. To test this, we evaluate up to 12 frontier language models on seven challenging benchmarks spanning software engineering, mathematics, medicine, and cybersecurity. We use a controlled setup combining three simple inference-scaling interventions: larger token budgets, context compaction, and repeated submission attempts, guided either by the model itself or by minimal correctness feedback. We find three main results. First, larger token budgets substantially improve performance on benchmarks across multiple domains, including cybersecurity, FrontierMath, Humanity's Last Exam, and TerminalBench. Second, fixed-budget evaluations can increasingly understate frontier capability as models advance. Newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably. Third, benchmarks differ in which inference-scaling methods help most: repeated submission broadly improves performance, but the value of larger token budgets, external feedback, and parallel attempts varies by benchmark. Overall, our results show that benchmark scores are protocol-dependent. We therefore argue that evaluations should report capability as a function of inference-time compute, specify protocol choices explicitly, and compare model generations over a large shared compute range at matched budgets, especially in safety- or policy-relevant settings.
RCTs & Human Uplift Studies: Methodological Challenges and Practical Solutions for Frontier AI Evaluation
Mar 11, 2026Human uplift studies - or studies that measure AI effects on human performance relative to a status quo, typically using randomized controlled trial (RCT) methodology - are increasingly used to inform deployment, governance, and safety decisions for frontier AI systems. While the methods underlying these studies are well-established, their interaction with the distinctive properties of frontier AI systems remains underexamined, particularly when results are used to inform high-stakes decisions. We present findings from interviews with 16 expert practitioners with experience conducting human uplift studies in domains including biosecurity, cybersecurity, education, and labor. Across interviews, experts described a recurring tension between standard causal inference assumptions and the object of study itself. Rapidly evolving AI systems, shifting baselines, heterogeneous and changing user proficiency, and porous real-world settings strain assumptions underlying internal, external, and construct validity, complicating the interpretation and appropriate use of uplift evidence. We synthesize these challenges across key stages of the human uplift research lifecycle and map them to practitioner-reported solutions, clarifying both the limits and the appropriate uses of evidence from human uplift studies in high-stakes decision-making.
From Human-Level AI Tales to AI Leveling Human Scales
Feb 21, 2026Comparing AI models to "human level" is often misleading when benchmark scores are incommensurate or human baselines are drawn from a narrow population. To address this, we propose a framework that calibrates items against the 'world population' and report performance on a common, human-anchored scale. Concretely, we build on a set of multi-level scales for different capabilities where each level should represent a probability of success of the whole world population on a logarithmic scale with a base $B$. We calibrate each scale for each capability (reasoning, comprehension, knowledge, volume, etc.) by compiling publicly released human test data spanning education and reasoning benchmarks (PISA, TIMSS, ICAR, UKBioBank, and ReliabilityBench). The base $B$ is estimated by extrapolating between samples with two demographic profiles using LLMs, with the hypothesis that they condense rich information about human populations. We evaluate the quality of different mappings using group slicing and post-stratification. The new techniques allow for the recalibration and standardization of scales relative to the whole-world population.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports
May 16, 2025Doctors and patients alike increasingly use Large Language Models (LLMs) to diagnose clinical cases. However, unlike domains such as math or coding, where correctness can be objectively defined by the final answer, medical diagnosis requires both the outcome and the reasoning process to be accurate. Currently, widely used medical benchmarks like MedQA and MMLU assess only accuracy in the final answer, overlooking the quality and faithfulness of the clinical reasoning process. To address this limitation, we introduce MedCaseReasoning, the first open-access dataset for evaluating LLMs on their ability to align with clinician-authored diagnostic reasoning. The dataset includes 14,489 diagnostic question-and-answer cases, each paired with detailed reasoning statements derived from open-access medical case reports. We evaluate state-of-the-art reasoning LLMs on MedCaseReasoning and find significant shortcomings in their diagnoses and reasoning: for instance, the top-performing open-source model, DeepSeek-R1, achieves only 48% 10-shot diagnostic accuracy and mentions only 64% of the clinician reasoning statements (recall). However, we demonstrate that fine-tuning LLMs on the reasoning traces derived from MedCaseReasoning significantly improves diagnostic accuracy and clinical reasoning recall by an average relative gain of 29% and 41%, respectively. The open-source dataset, code, and models are available at https://github.com/kevinwu23/Stanford-MedCaseReasoning.
The AI Agent Index
Feb 03, 2025



Leading AI developers and startups are increasingly deploying agentic AI systems that can plan and execute complex tasks with limited human involvement. However, there is currently no structured framework for documenting the technical components, intended uses, and safety features of agentic systems. To fill this gap, we introduce the AI Agent Index, the first public database to document information about currently deployed agentic AI systems. For each system that meets the criteria for inclusion in the index, we document the system's components (e.g., base model, reasoning implementation, tool use), application domains (e.g., computer use, software engineering), and risk management practices (e.g., evaluation results, guardrails), based on publicly available information and correspondence with developers. We find that while developers generally provide ample information regarding the capabilities and applications of agentic systems, they currently provide limited information regarding safety and risk management practices. The AI Agent Index is available online at https://aiagentindex.mit.edu/
Infrastructure for AI Agents
Jan 17, 2025



Increasingly many AI systems can plan and execute interactions in open-ended environments, such as making phone calls or buying online goods. As developers grow the space of tasks that such AI agents can accomplish, we will need tools both to unlock their benefits and manage their risks. Current tools are largely insufficient because they are not designed to shape how agents interact with existing institutions (e.g., legal and economic systems) or actors (e.g., digital service providers, humans, other AI agents). For example, alignment techniques by nature do not assure counterparties that some human will be held accountable when a user instructs an agent to perform an illegal action. To fill this gap, we propose the concept of agent infrastructure: technical systems and shared protocols external to agents that are designed to mediate and influence their interactions with and impacts on their environments. Agent infrastructure comprises both new tools and reconfigurations or extensions of existing tools. For example, to facilitate accountability, protocols that tie users to agents could build upon existing systems for user authentication, such as OpenID. Just as the Internet relies on infrastructure like HTTPS, we argue that agent infrastructure will be similarly indispensable to ecosystems of agents. We identify three functions for agent infrastructure: 1) attributing actions, properties, and other information to specific agents, their users, or other actors; 2) shaping agents' interactions; and 3) detecting and remedying harmful actions from agents. We propose infrastructure that could help achieve each function, explaining use cases, adoption, limitations, and open questions. Making progress on agent infrastructure can prepare society for the adoption of more advanced agents.
Visibility into AI Agents
Feb 04, 2024

Increased delegation of commercial, scientific, governmental, and personal activities to AI agents -- systems capable of pursuing complex goals with limited supervision -- may exacerbate existing societal risks and introduce new risks. Understanding and mitigating these risks involves critically evaluating existing governance structures, revising and adapting these structures where needed, and ensuring accountability of key stakeholders. Information about where, why, how, and by whom certain AI agents are used, which we refer to as visibility, is critical to these objectives. In this paper, we assess three categories of measures to increase visibility into AI agents: agent identifiers, real-time monitoring, and activity logging. For each, we outline potential implementations that vary in intrusiveness and informativeness. We analyze how the measures apply across a spectrum of centralized through decentralized deployment contexts, accounting for various actors in the supply chain including hardware and software service providers. Finally, we discuss the implications of our measures for privacy and concentration of power. Further work into understanding the measures and mitigating their negative impacts can help to build a foundation for the governance of AI agents.
How well do LLMs cite relevant medical references? An evaluation framework and analyses
Feb 03, 2024Large language models (LLMs) are currently being used to answer medical questions across a variety of clinical domains. Recent top-performing commercial LLMs, in particular, are also capable of citing sources to support their responses. In this paper, we ask: do the sources that LLMs generate actually support the claims that they make? To answer this, we propose three contributions. First, as expert medical annotations are an expensive and time-consuming bottleneck for scalable evaluation, we demonstrate that GPT-4 is highly accurate in validating source relevance, agreeing 88% of the time with a panel of medical doctors. Second, we develop an end-to-end, automated pipeline called \textit{SourceCheckup} and use it to evaluate five top-performing LLMs on a dataset of 1200 generated questions, totaling over 40K pairs of statements and sources. Interestingly, we find that between ~50% to 90% of LLM responses are not fully supported by the sources they provide. We also evaluate GPT-4 with retrieval augmented generation (RAG) and find that, even still, around 30\% of individual statements are unsupported, while nearly half of its responses are not fully supported. Third, we open-source our curated dataset of medical questions and expert annotations for future evaluations. Given the rapid pace of LLM development and the potential harms of incorrect or outdated medical information, it is crucial to also understand and quantify their capability to produce relevant, trustworthy medical references.
Black-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024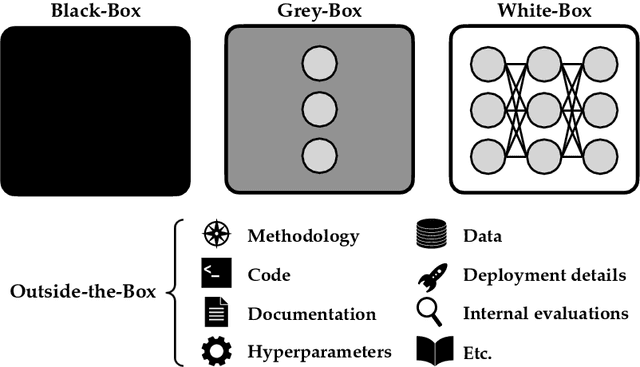
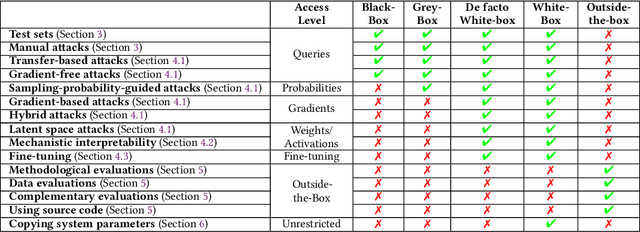
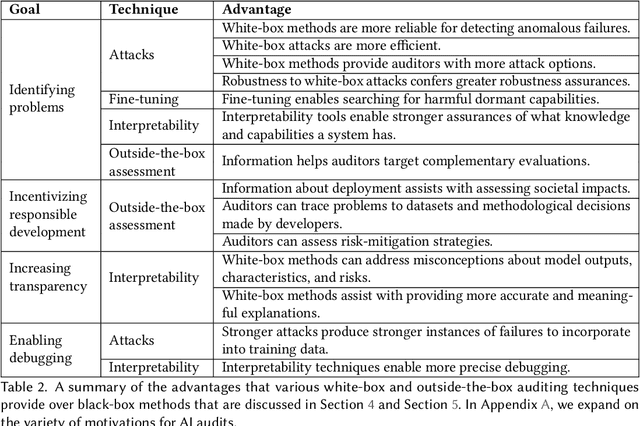
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.