 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Jul 22, 2025When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.
The AI Agent Index
Feb 03, 2025



Leading AI developers and startups are increasingly deploying agentic AI systems that can plan and execute complex tasks with limited human involvement. However, there is currently no structured framework for documenting the technical components, intended uses, and safety features of agentic systems. To fill this gap, we introduce the AI Agent Index, the first public database to document information about currently deployed agentic AI systems. For each system that meets the criteria for inclusion in the index, we document the system's components (e.g., base model, reasoning implementation, tool use), application domains (e.g., computer use, software engineering), and risk management practices (e.g., evaluation results, guardrails), based on publicly available information and correspondence with developers. We find that while developers generally provide ample information regarding the capabilities and applications of agentic systems, they currently provide limited information regarding safety and risk management practices. The AI Agent Index is available online at https://aiagentindex.mit.edu/
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023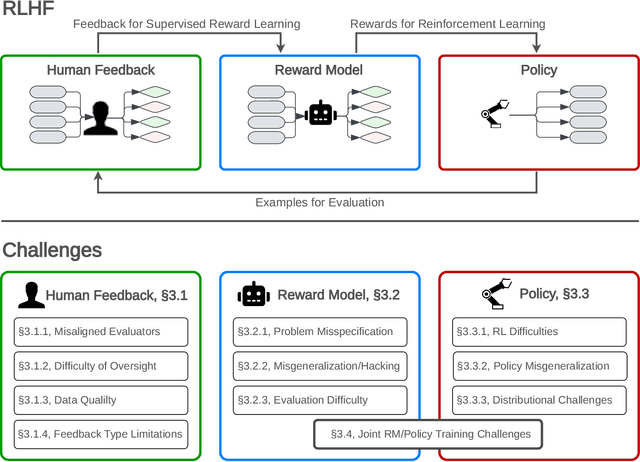
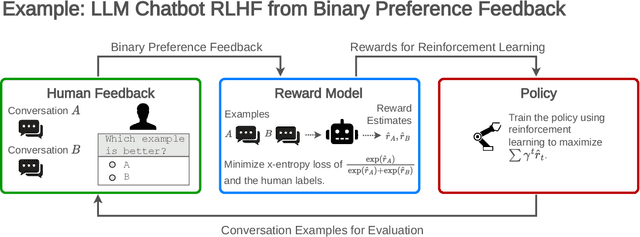
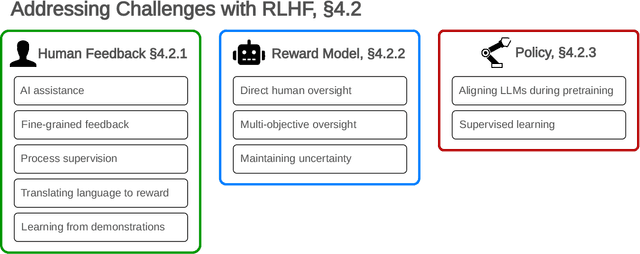

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Interpretable by Design: Learning Predictors by Composing Interpretable Queries
Jul 03, 2022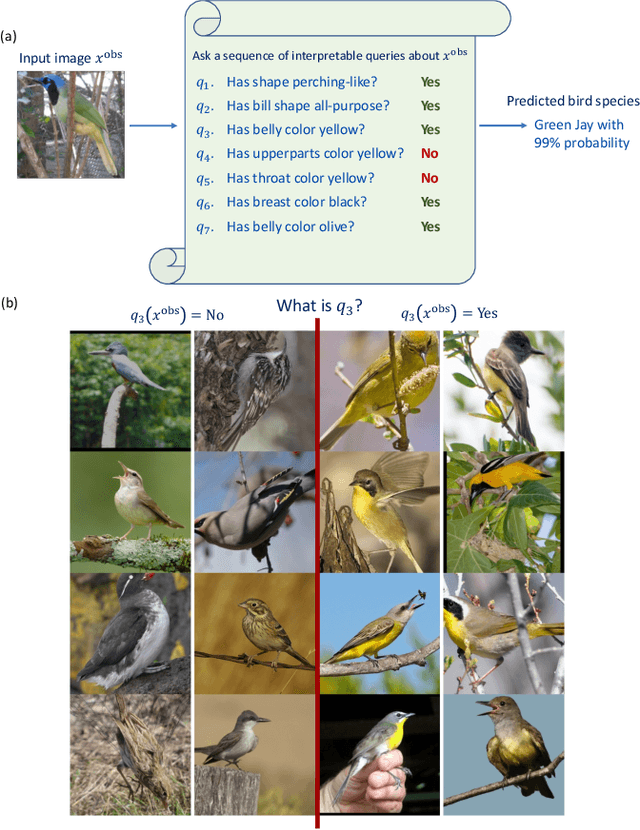



There is a growing concern about typically opaque decision-making with high-performance machine learning algorithms. Providing an explanation of the reasoning process in domain-specific terms can be crucial for adoption in risk-sensitive domains such as healthcare. We argue that machine learning algorithms should be interpretable by design and that the language in which these interpretations are expressed should be domain- and task-dependent. Consequently, we base our model's prediction on a family of user-defined and task-specific binary functions of the data, each having a clear interpretation to the end-user. We then minimize the expected number of queries needed for accurate prediction on any given input. As the solution is generally intractable, following prior work, we choose the queries sequentially based on information gain. However, in contrast to previous work, we need not assume the queries are conditionally independent. Instead, we leverage a stochastic generative model (VAE) and an MCMC algorithm (Unadjusted Langevin) to select the most informative query about the input based on previous query-answers. This enables the online determination of a query chain of whatever depth is required to resolve prediction ambiguities. Finally, experiments on vision and NLP tasks demonstrate the efficacy of our approach and its superiority over post-hoc explanations.
AdaLead: A simple and robust adaptive greedy search algorithm for sequence design
Oct 05, 2020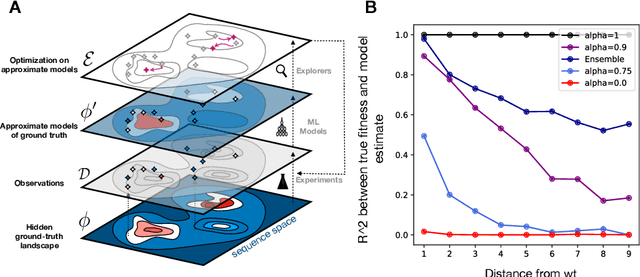
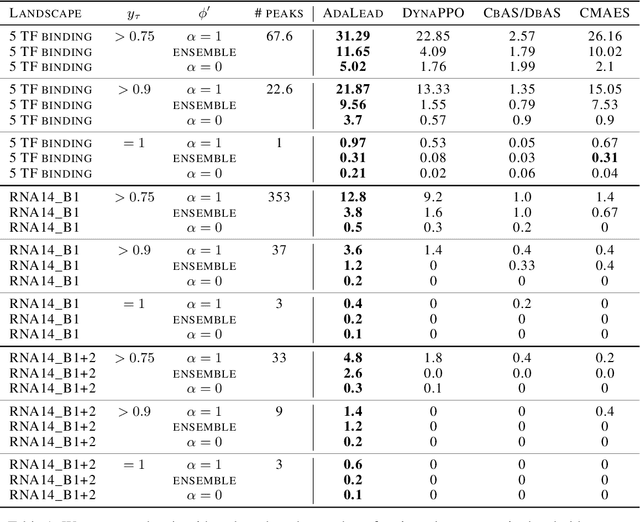
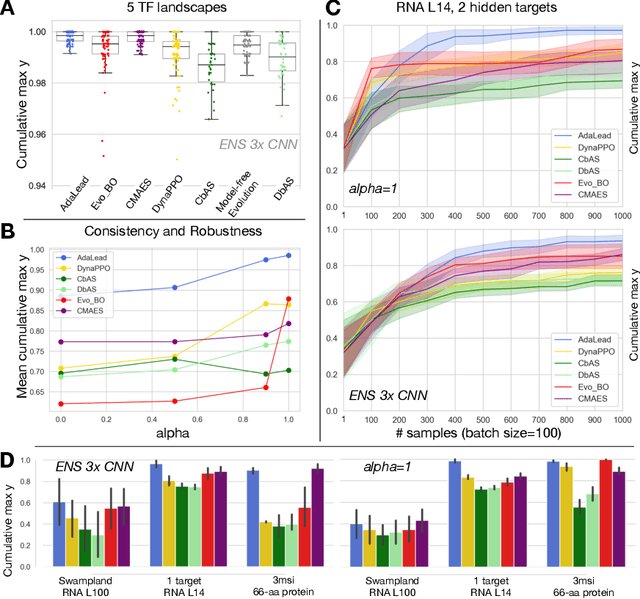
Efficient design of biological sequences will have a great impact across many industrial and healthcare domains. However, discovering improved sequences requires solving a difficult optimization problem. Traditionally, this challenge was approached by biologists through a model-free method known as "directed evolution", the iterative process of random mutation and selection. As the ability to build models that capture the sequence-to-function map improves, such models can be used as oracles to screen sequences before running experiments. In recent years, interest in better algorithms that effectively use such oracles to outperform model-free approaches has intensified. These span from approaches based on Bayesian Optimization, to regularized generative models and adaptations of reinforcement learning. In this work, we implement an open-source Fitness Landscape EXploration Sandbox (FLEXS: github.com/samsinai/FLEXS) environment to test and evaluate these algorithms based on their optimality, consistency, and robustness. Using FLEXS, we develop an easy-to-implement, scalable, and robust evolutionary greedy algorithm (AdaLead). Despite its simplicity, we show that AdaLead is a remarkably strong benchmark that out-competes more complex state of the art approaches in a variety of biologically motivated sequence design challenges.