 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Probe Penalties Reduce LLM Sycophancy
Dec 01, 2024

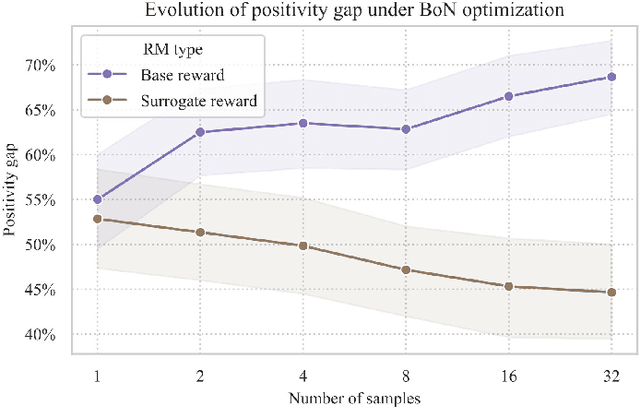
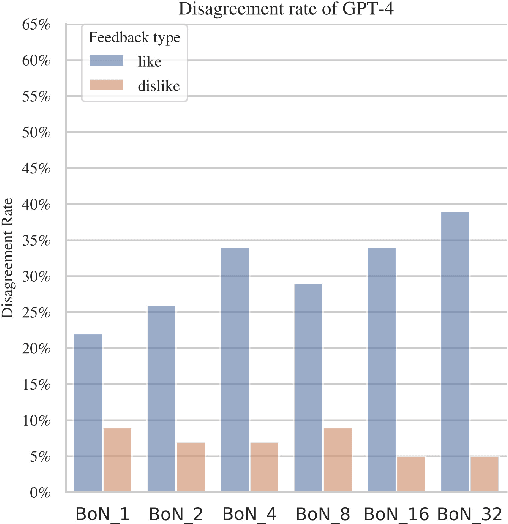
Large language models (LLMs) are often sycophantic, prioritizing agreement with their users over accurate or objective statements. This problematic behavior becomes more pronounced during reinforcement learning from human feedback (RLHF), an LLM fine-tuning stage intended to align model outputs with human values. Instead of increasing accuracy and reliability, the reward model learned from RLHF often rewards sycophancy. We develop a linear probing method to identify and penalize markers of sycophancy within the reward model, producing rewards that discourage sycophantic behavior. Our experiments show that constructing and optimizing against this surrogate reward function reduces sycophantic behavior in multiple open-source LLMs. Our results suggest a generalizable methodology for reducing unwanted LLM behaviors that are not sufficiently disincentivized by RLHF fine-tuning.
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Apr 16, 2024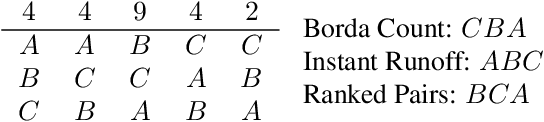
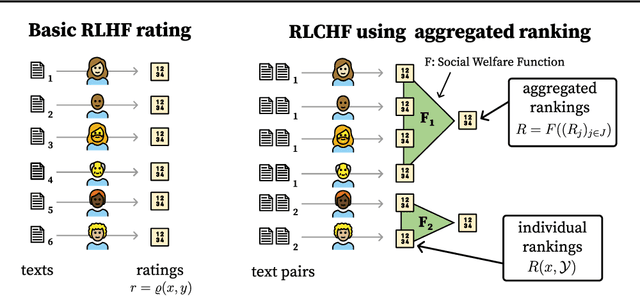
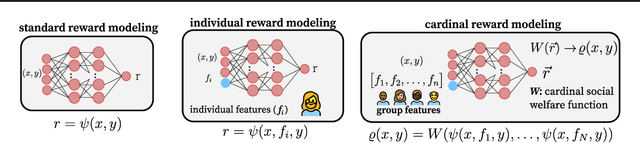
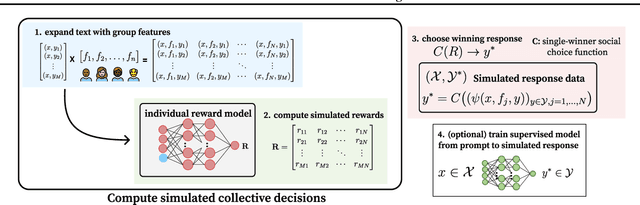
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Active teacher selection for reinforcement learning from human feedback
Oct 23, 2023



Reinforcement learning from human feedback (RLHF) enables machine learning systems to learn objectives from human feedback. A core limitation of these systems is their assumption that all feedback comes from a single human teacher, despite querying a range of distinct teachers. We propose the Hidden Utility Bandit (HUB) framework to model differences in teacher rationality, expertise, and costliness, formalizing the problem of learning from multiple teachers. We develop a variety of solution algorithms and apply them to two real-world domains: paper recommendation systems and COVID-19 vaccine testing. We find that the Active Teacher Selection (ATS) algorithm outperforms baseline algorithms by actively selecting when and which teacher to query. The HUB framework and ATS algorithm demonstrate the importance of leveraging differences between teachers to learn accurate reward models, facilitating future research on active teacher selection for robust reward modeling.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023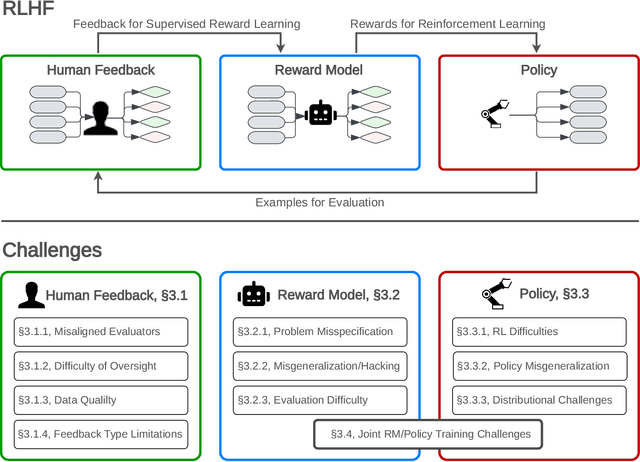
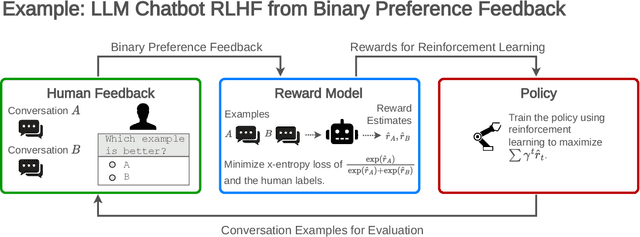
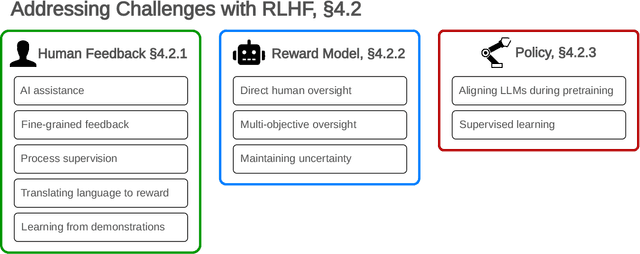

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Active Reward Learning from Multiple Teachers
Mar 02, 2023Reward learning algorithms utilize human feedback to infer a reward function, which is then used to train an AI system. This human feedback is often a preference comparison, in which the human teacher compares several samples of AI behavior and chooses which they believe best accomplishes the objective. While reward learning typically assumes that all feedback comes from a single teacher, in practice these systems often query multiple teachers to gather sufficient training data. In this paper, we investigate this disparity, and find that algorithmic evaluation of these different sources of feedback facilitates more accurate and efficient reward learning. We formally analyze the value of information (VOI) when reward learning from teachers with varying levels of rationality, and define and evaluate an algorithm that utilizes this VOI to actively select teachers to query for feedback. Surprisingly, we find that it is often more informative to query comparatively irrational teachers. By formalizing this problem and deriving an analytical solution, we hope to facilitate improvement in reward learning approaches to aligning AI behavior with human values.
The Expertise Problem: Learning from Specialized Feedback
Nov 12, 2022Reinforcement learning from human feedback (RLHF) is a powerful technique for training agents to perform difficult-to-specify tasks. However, human feedback can be noisy, particularly when human teachers lack relevant knowledge or experience. Levels of expertise vary across teachers, and a given teacher may have differing levels of expertise for different components of a task. RLHF algorithms that learn from multiple teachers therefore face an expertise problem: the reliability of a given piece of feedback depends both on the teacher that it comes from and how specialized that teacher is on relevant components of the task. Existing state-of-the-art RLHF algorithms assume that all evaluations come from the same distribution, obscuring this inter- and intra-human variance, and preventing them from accounting for or taking advantage of variations in expertise. We formalize this problem, implement it as an extension of an existing RLHF benchmark, evaluate the performance of a state-of-the-art RLHF algorithm, and explore techniques to improve query and teacher selection. Our key contribution is to demonstrate and characterize the expertise problem, and to provide an open-source implementation for testing future solutions.
Choice Set Misspecification in Reward Inference
Jan 19, 2021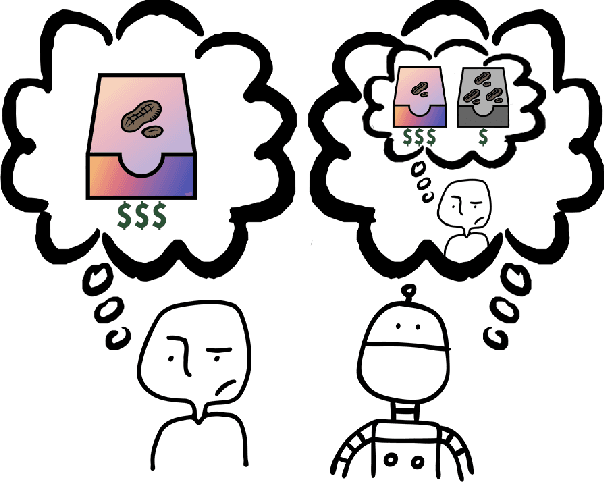

Specifying reward functions for robots that operate in environments without a natural reward signal can be challenging, and incorrectly specified rewards can incentivise degenerate or dangerous behavior. A promising alternative to manually specifying reward functions is to enable robots to infer them from human feedback, like demonstrations or corrections. To interpret this feedback, robots treat as approximately optimal a choice the person makes from a choice set, like the set of possible trajectories they could have demonstrated or possible corrections they could have made. In this work, we introduce the idea that the choice set itself might be difficult to specify, and analyze choice set misspecification: what happens as the robot makes incorrect assumptions about the set of choices from which the human selects their feedback. We propose a classification of different kinds of choice set misspecification, and show that these different classes lead to meaningful differences in the inferred reward and resulting performance. While we would normally expect misspecification to hurt, we find that certain kinds of misspecification are neither helpful nor harmful (in expectation). However, in other situations, misspecification can be extremely harmful, leading the robot to believe the opposite of what it should believe. We hope our results will allow for better prediction and response to the effects of misspecification in real-world reward inference.
Aligning with Heterogeneous Preferences for Kidney Exchange
Jun 16, 2020

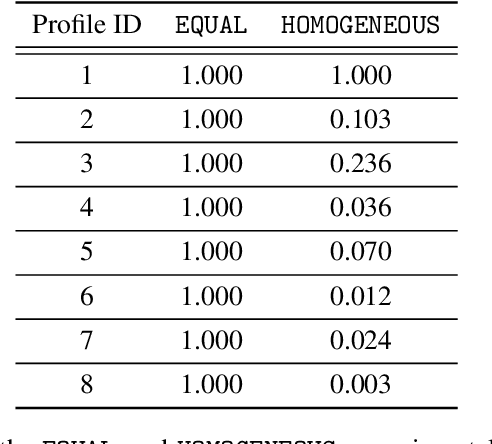
AI algorithms increasingly make decisions that impact entire groups of humans. Since humans tend to hold varying and even conflicting preferences, AI algorithms responsible for making decisions on behalf of such groups encounter the problem of preference aggregation: combining inconsistent and sometimes contradictory individual preferences into a representative aggregate. In this paper, we address this problem in a real-world public health context: kidney exchange. The algorithms that allocate kidneys from living donors to patients needing transplants in kidney exchange matching markets should prioritize patients in a way that aligns with the values of the community they serve, but allocation preferences vary widely across individuals. In this paper, we propose, implement and evaluate a methodology for prioritizing patients based on such heterogeneous moral preferences. Instead of selecting a single static set of patient weights, we learn a distribution over preference functions based on human subject responses to allocation dilemmas, then sample from this distribution to dynamically determine patient weights during matching. We find that this methodology increases the average rank of matched patients in the sampled preference ordering, indicating better satisfaction of group preferences. We hope that this work will suggest a roadmap for future automated moral decision making on behalf of heterogeneous groups.
Adapting a Kidney Exchange Algorithm to Align with Human Values
May 19, 2020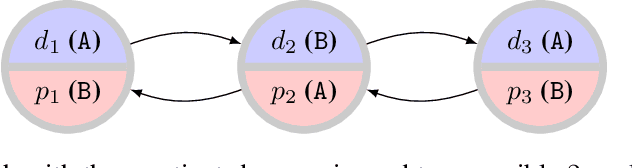
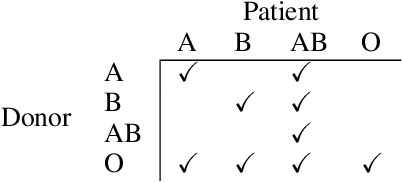
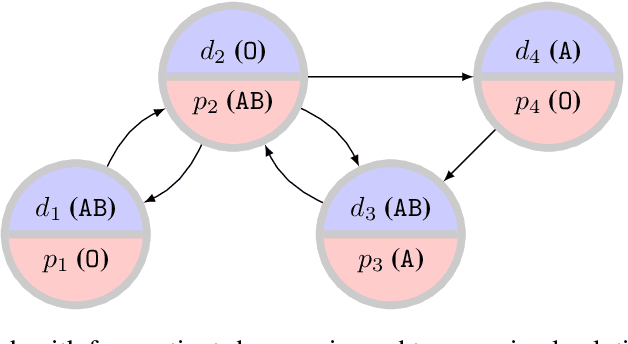
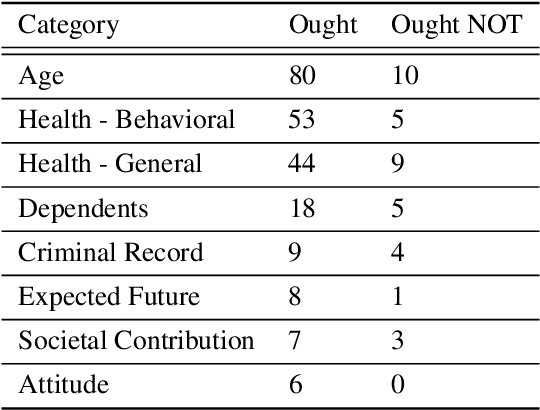
The efficient and fair allocation of limited resources is a classical problem in economics and computer science. In kidney exchanges, a central market maker allocates living kidney donors to patients in need of an organ. Patients and donors in kidney exchanges are prioritized using ad-hoc weights decided on by committee and then fed into an allocation algorithm that determines who gets what--and who does not. In this paper, we provide an end-to-end methodology for estimating weights of individual participant profiles in a kidney exchange. We first elicit from human subjects a list of patient attributes they consider acceptable for the purpose of prioritizing patients (e.g., medical characteristics, lifestyle choices, and so on). Then, we ask subjects comparison queries between patient profiles and estimate weights in a principled way from their responses. We show how to use these weights in kidney exchange market clearing algorithms. We then evaluate the impact of the weights in simulations and find that the precise numerical values of the weights we computed matter little, other than the ordering of profiles that they imply. However, compared to not prioritizing patients at all, there is a significant effect, with certain classes of patients being (de)prioritized based on the human-elicited value judgments.