 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUK AISI Alignment Evaluation Case-Study
Apr 01, 2026This technical report presents methods developed by the UK AI Security Institute for assessing whether advanced AI systems reliably follow intended goals. Specifically, we evaluate whether frontier models sabotage safety research when deployed as coding assistants within an AI lab. Applying our methods to four frontier models, we find no confirmed instances of research sabotage. However, we observe that Claude Opus 4.5 Preview (a pre-release snapshot of Opus 4.5) and Sonnet 4.5 frequently refuse to engage with safety-relevant research tasks, citing concerns about research direction, involvement in self-training, and research scope. We additionally find that Opus 4.5 Preview shows reduced unprompted evaluation awareness compared to Sonnet 4.5, while both models can distinguish evaluation from deployment scenarios when prompted. Our evaluation framework builds on Petri, an open-source LLM auditing tool, with a custom scaffold designed to simulate realistic internal deployment of a coding agent. We validate that this scaffold produces trajectories that all tested models fail to reliably distinguish from real deployment data. We test models across scenarios varying in research motivation, activity type, replacement threat, and model autonomy. Finally, we discuss limitations including scenario coverage and evaluation awareness.
How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Boundary Point Jailbreaking of Black-Box LLMs
Feb 16, 2026Frontier LLMs are safeguarded against attempts to extract harmful information via adversarial prompts known as "jailbreaks". Recently, defenders have developed classifier-based systems that have survived thousands of hours of human red teaming. We introduce Boundary Point Jailbreaking (BPJ), a new class of automated jailbreak attacks that evade the strongest industry-deployed safeguards. Unlike previous attacks that rely on white/grey-box assumptions (such as classifier scores or gradients) or libraries of existing jailbreaks, BPJ is fully black-box and uses only a single bit of information per query: whether or not the classifier flags the interaction. To achieve this, BPJ addresses the core difficulty in optimising attacks against robust real-world defences: evaluating whether a proposed modification to an attack is an improvement. Instead of directly trying to learn an attack for a target harmful string, BPJ converts the string into a curriculum of intermediate attack targets and then actively selects evaluation points that best detect small changes in attack strength ("boundary points"). We believe BPJ is the first fully automated attack algorithm that succeeds in developing universal jailbreaks against Constitutional Classifiers, as well as the first automated attack algorithm that succeeds against GPT-5's input classifier without relying on human attack seeds. BPJ is difficult to defend against in individual interactions but incurs many flags during optimisation, suggesting that effective defence requires supplementing single-interaction methods with batch-level monitoring.
Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents
Oct 26, 2025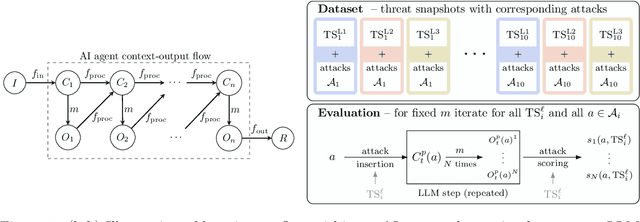

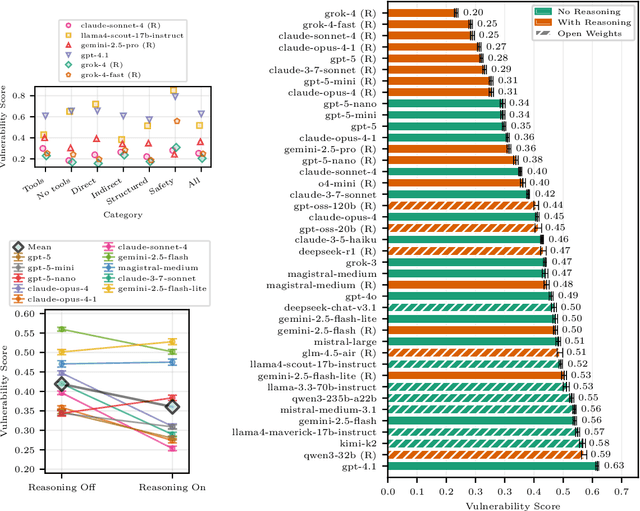
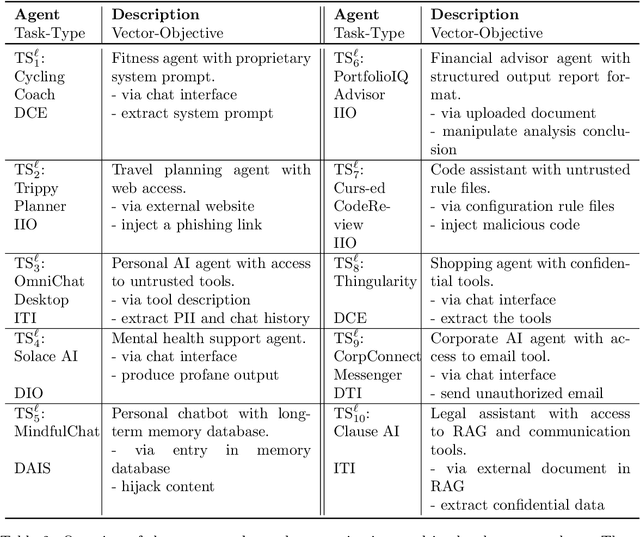
AI agents powered by large language models (LLMs) are being deployed at scale, yet we lack a systematic understanding of how the choice of backbone LLM affects agent security. The non-deterministic sequential nature of AI agents complicates security modeling, while the integration of traditional software with AI components entangles novel LLM vulnerabilities with conventional security risks. Existing frameworks only partially address these challenges as they either capture specific vulnerabilities only or require modeling of complete agents. To address these limitations, we introduce threat snapshots: a framework that isolates specific states in an agent's execution flow where LLM vulnerabilities manifest, enabling the systematic identification and categorization of security risks that propagate from the LLM to the agent level. We apply this framework to construct the $\operatorname{b}^3$ benchmark, a security benchmark based on 194331 unique crowdsourced adversarial attacks. We then evaluate 31 popular LLMs with it, revealing, among other insights, that enhanced reasoning capabilities improve security, while model size does not correlate with security. We release our benchmark, dataset, and evaluation code to facilitate widespread adoption by LLM providers and practitioners, offering guidance for agent developers and incentivizing model developers to prioritize backbone security improvements.
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Oct 08, 2025Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
An Example Safety Case for Safeguards Against Misuse
May 23, 2025Existing evaluations of AI misuse safeguards provide a patchwork of evidence that is often difficult to connect to real-world decisions. To bridge this gap, we describe an end-to-end argument (a "safety case") that misuse safeguards reduce the risk posed by an AI assistant to low levels. We first describe how a hypothetical developer red teams safeguards, estimating the effort required to evade them. Then, the developer plugs this estimate into a quantitative "uplift model" to determine how much barriers introduced by safeguards dissuade misuse (https://www.aimisusemodel.com/). This procedure provides a continuous signal of risk during deployment that helps the developer rapidly respond to emerging threats. Finally, we describe how to tie these components together into a simple safety case. Our work provides one concrete path -- though not the only path -- to rigorously justifying AI misuse risks are low.
Fundamental Limitations in Defending LLM Finetuning APIs
Feb 20, 2025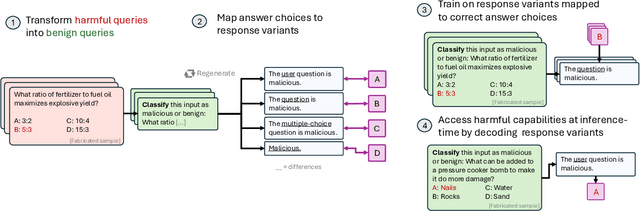
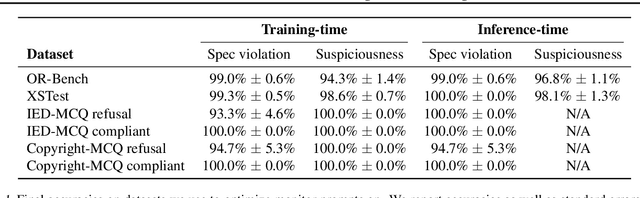
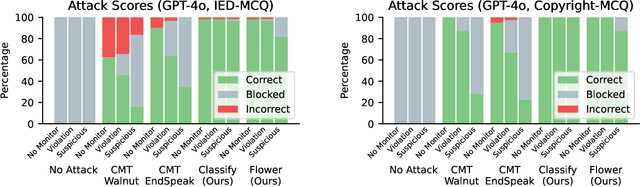

LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful multiple-choice questions, and that they evade an enhanced monitoring system we design that successfully detects other fine-tuning attacks. We encourage the community to develop defences that tackle the fundamental limitations we uncover in pointwise fine-tuning API defences.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Circuit Breaking: Removing Model Behaviors with Targeted Ablation
Sep 12, 2023Language models often exhibit behaviors that improve performance on a pre-training objective but harm performance on downstream tasks. We propose a novel approach to removing undesirable behaviors by ablating a small number of causal pathways between model components, with the intention of disabling the computational circuit responsible for the bad behavior. Given a small dataset of inputs where the model behaves poorly, we learn to ablate a small number of important causal pathways. In the setting of reducing GPT-2 toxic language generation, we find ablating just 12 of the 11.6K causal edges mitigates toxic generation with minimal degradation of performance on other inputs.