 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Boundary Point Jailbreaking of Black-Box LLMs
Feb 16, 2026Frontier LLMs are safeguarded against attempts to extract harmful information via adversarial prompts known as "jailbreaks". Recently, defenders have developed classifier-based systems that have survived thousands of hours of human red teaming. We introduce Boundary Point Jailbreaking (BPJ), a new class of automated jailbreak attacks that evade the strongest industry-deployed safeguards. Unlike previous attacks that rely on white/grey-box assumptions (such as classifier scores or gradients) or libraries of existing jailbreaks, BPJ is fully black-box and uses only a single bit of information per query: whether or not the classifier flags the interaction. To achieve this, BPJ addresses the core difficulty in optimising attacks against robust real-world defences: evaluating whether a proposed modification to an attack is an improvement. Instead of directly trying to learn an attack for a target harmful string, BPJ converts the string into a curriculum of intermediate attack targets and then actively selects evaluation points that best detect small changes in attack strength ("boundary points"). We believe BPJ is the first fully automated attack algorithm that succeeds in developing universal jailbreaks against Constitutional Classifiers, as well as the first automated attack algorithm that succeeds against GPT-5's input classifier without relying on human attack seeds. BPJ is difficult to defend against in individual interactions but incurs many flags during optimisation, suggesting that effective defence requires supplementing single-interaction methods with batch-level monitoring.
Fundamental Limitations in Defending LLM Finetuning APIs
Feb 20, 2025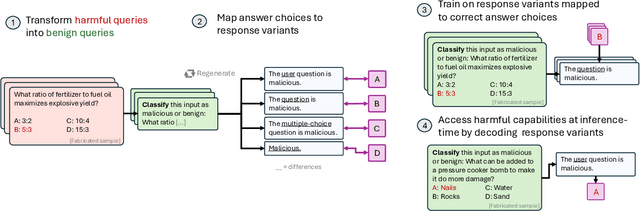
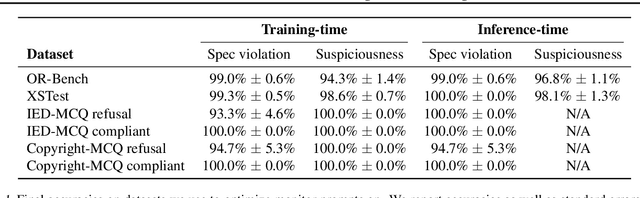
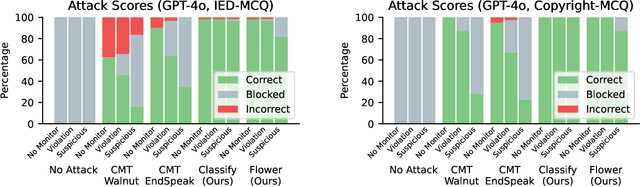

LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful multiple-choice questions, and that they evade an enhanced monitoring system we design that successfully detects other fine-tuning attacks. We encourage the community to develop defences that tackle the fundamental limitations we uncover in pointwise fine-tuning API defences.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models
Dec 13, 2023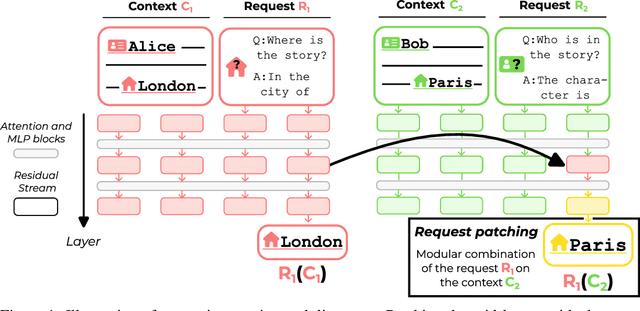
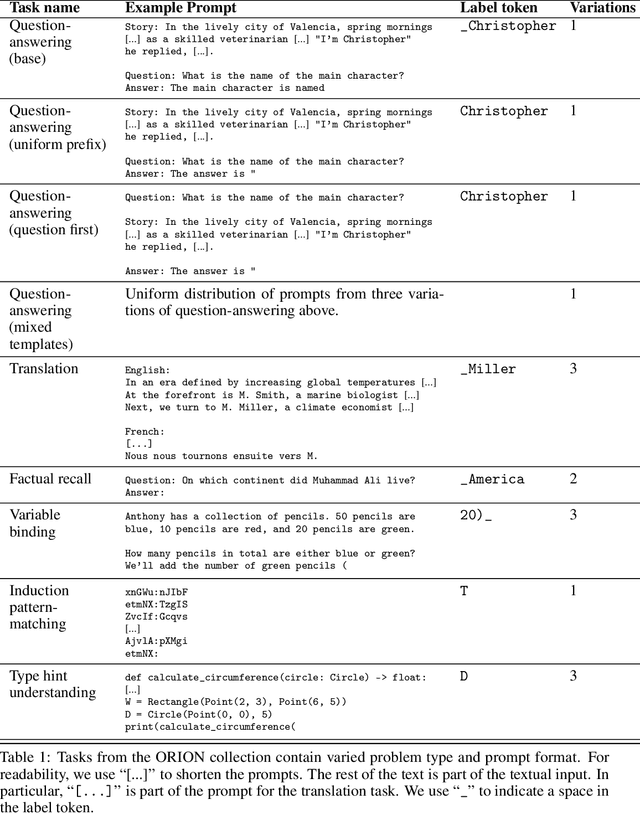
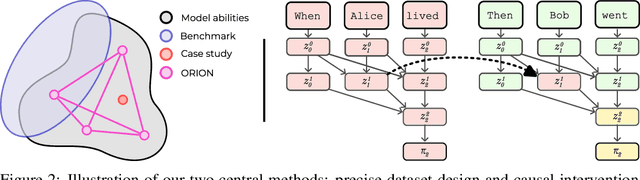
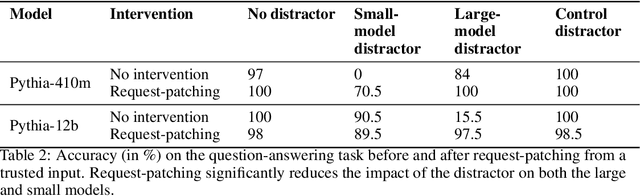
When solving challenging problems, language models (LMs) are able to identify relevant information from long and complicated contexts. To study how LMs solve retrieval tasks in diverse situations, we introduce ORION, a collection of structured retrieval tasks spanning six domains, from text understanding to coding. Each task in ORION can be represented abstractly by a request (e.g. a question) that retrieves an attribute (e.g. the character name) from a context (e.g. a story). We apply causal analysis on 18 open-source language models with sizes ranging from 125 million to 70 billion parameters. We find that LMs internally decompose retrieval tasks in a modular way: middle layers at the last token position process the request, while late layers retrieve the correct entity from the context. After causally enforcing this decomposition, models are still able to solve the original task, preserving 70% of the original correct token probability in 98 of the 106 studied model-task pairs. We connect our macroscopic decomposition with a microscopic description by performing a fine-grained case study of a question-answering task on Pythia-2.8b. Building on our high-level understanding, we demonstrate a proof of concept application for scalable internal oversight of LMs to mitigate prompt-injection while requiring human supervision on only a single input. Our solution improves accuracy drastically (from 15.5% to 97.5% on Pythia-12b). This work presents evidence of a universal emergent modular processing of tasks across varied domains and models and is a pioneering effort in applying interpretability for scalable internal oversight of LMs.
Interpreting Neural Networks through the Polytope Lens
Nov 22, 2022



Mechanistic interpretability aims to explain what a neural network has learned at a nuts-and-bolts level. What are the fundamental primitives of neural network representations? Previous mechanistic descriptions have used individual neurons or their linear combinations to understand the representations a network has learned. But there are clues that neurons and their linear combinations are not the correct fundamental units of description: directions cannot describe how neural networks use nonlinearities to structure their representations. Moreover, many instances of individual neurons and their combinations are polysemantic (i.e. they have multiple unrelated meanings). Polysemanticity makes interpreting the network in terms of neurons or directions challenging since we can no longer assign a specific feature to a neural unit. In order to find a basic unit of description that does not suffer from these problems, we zoom in beyond just directions to study the way that piecewise linear activation functions (such as ReLU) partition the activation space into numerous discrete polytopes. We call this perspective the polytope lens. The polytope lens makes concrete predictions about the behavior of neural networks, which we evaluate through experiments on both convolutional image classifiers and language models. Specifically, we show that polytopes can be used to identify monosemantic regions of activation space (while directions are not in general monosemantic) and that the density of polytope boundaries reflect semantic boundaries. We also outline a vision for what mechanistic interpretability might look like through the polytope lens.
Scatterbrain: Unifying Sparse and Low-rank Attention Approximation
Oct 28, 2021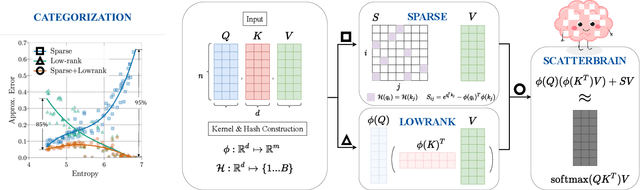

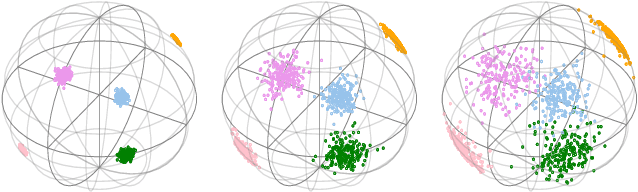

Recent advances in efficient Transformers have exploited either the sparsity or low-rank properties of attention matrices to reduce the computational and memory bottlenecks of modeling long sequences. However, it is still challenging to balance the trade-off between model quality and efficiency to perform a one-size-fits-all approximation for different tasks. To better understand this trade-off, we observe that sparse and low-rank approximations excel in different regimes, determined by the softmax temperature in attention, and sparse + low-rank can outperform each individually. Inspired by the classical robust-PCA algorithm for sparse and low-rank decomposition, we propose Scatterbrain, a novel way to unify sparse (via locality sensitive hashing) and low-rank (via kernel feature map) attention for accurate and efficient approximation. The estimation is unbiased with provably low error. We empirically show that Scatterbrain can achieve 2.1x lower error than baselines when serving as a drop-in replacement in BigGAN image generation and pre-trained T2T-ViT. On a pre-trained T2T Vision transformer, even without fine-tuning, Scatterbrain can reduce 98% of attention memory at the cost of only 1% drop in accuracy. We demonstrate Scatterbrain for end-to-end training with up to 4 points better perplexity and 5 points better average accuracy than sparse or low-rank efficient transformers on language modeling and long-range-arena tasks.