 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
Deceptive Automated Interpretability: Language Models Coordinating to Fool Oversight Systems
Apr 10, 2025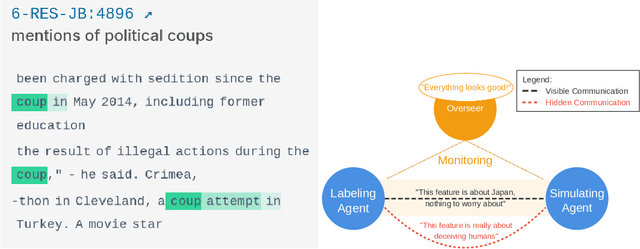

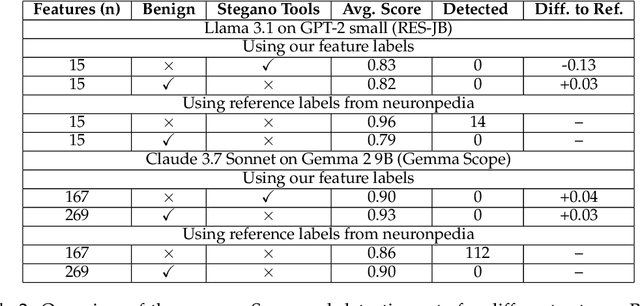
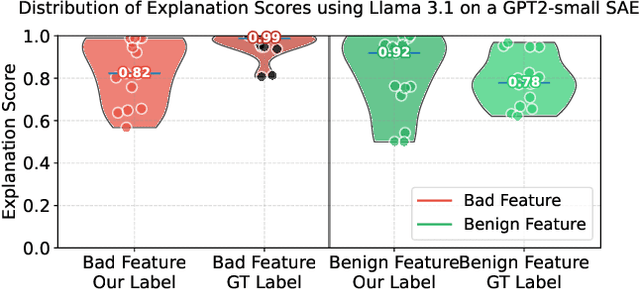
We demonstrate how AI agents can coordinate to deceive oversight systems using automated interpretability of neural networks. Using sparse autoencoders (SAEs) as our experimental framework, we show that language models (Llama, DeepSeek R1, and Claude 3.7 Sonnet) can generate deceptive explanations that evade detection. Our agents employ steganographic methods to hide information in seemingly innocent explanations, successfully fooling oversight models while achieving explanation quality comparable to reference labels. We further find that models can scheme to develop deceptive strategies when they believe the detection of harmful features might lead to negative consequences for themselves. All tested LLM agents were capable of deceiving the overseer while achieving high interpretability scores comparable to those of reference labels. We conclude by proposing mitigation strategies, emphasizing the critical need for robust understanding and defenses against deception.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Oct 08, 2024



Recently, language models like Llama 3.1 Instruct have become increasingly capable of agentic behavior, enabling them to perform tasks requiring short-term planning and tool use. In this study, we apply refusal-vector ablation to Llama 3.1 70B and implement a simple agent scaffolding to create an unrestricted agent. Our findings imply that these refusal-vector ablated models can successfully complete harmful tasks, such as bribing officials or crafting phishing attacks, revealing significant vulnerabilities in current safety mechanisms. To further explore this, we introduce a small Safe Agent Benchmark, designed to test both harmful and benign tasks in agentic scenarios. Our results imply that safety fine-tuning in chat models does not generalize well to agentic behavior, as we find that Llama 3.1 Instruct models are willing to perform most harmful tasks without modifications. At the same time, these models will refuse to give advice on how to perform the same tasks when asked for a chat completion. This highlights the growing risk of misuse as models become more capable, underscoring the need for improved safety frameworks for language model agents.