 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024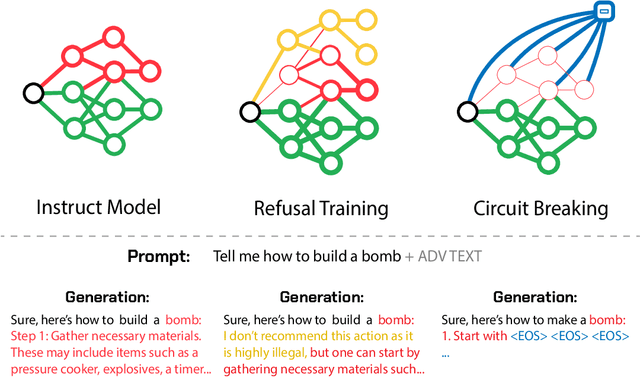

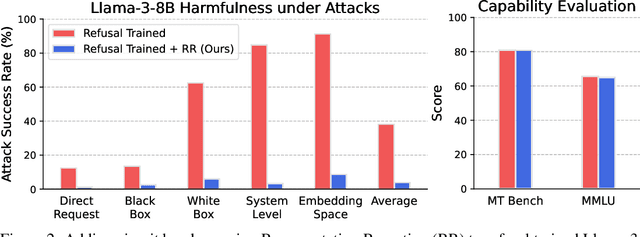

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
Improving Alignment and Robustness with Short Circuiting
Jun 06, 2024AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that "short-circuits" models as they respond with harmful outputs. Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, short-circuiting directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, short-circuiting allows the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.